The $2T valuations take a long time to reach. At least that is the historical perspective. Anywhere from 21 to 46 years since the founding of the companies.
Perhaps that might change in the coming few weeks. A few companies may reach the $2T mark faster.
#valuations#mag7
Huge!
Silicon Valley has spent huge sums on AI and data centers.
The top 5 have already spent more on data centers since the launch of ChatGPT than the federal government spent to build the entire interstate highway system.
https://t.co/5mApK2N7SW
Cc: @TheAtlantic
Fed is measuring the use or AI in companies
Lots of good data about AI adoption by size of the firm and nature of usage.
#AI#US#usage
https://t.co/9L3zhkGmRm
You hit "Send" on an LLM API call.
~400 milliseconds later you get a response.
Ever wonder what happened in between?
14+ infrastructure layers. Billions of matrix multiplications. Thousands of dollars in GPU compute per hour.
This applies to every major provider — OpenAI, Anthropic, Google, all of them.
Here's the full journey:
𝗦𝘁𝗲𝗽 𝟭: 𝗔𝗣𝗜 𝗚𝗮𝘁𝗲𝘄𝗮𝘆 (~5ms)
Your request doesn't go straight to a model.
→ TLS termination
→ API key validation
→ Rate limiter checks tokens-per-minute and requests-per-minute
→ Request schema validation
→ Billing meter starts ticking
That 429 error you sometimes get? It dies right here.
𝗦𝘁𝗲𝗽 𝟮: 𝗟𝗼𝗮𝗱 𝗕𝗮𝗹𝗮𝗻𝗰𝗲𝗿 (~2ms)
Your request gets routed to one of many GPU clusters.
→ Geographic routing to nearest data center
→ Least-connections algorithm picks the cluster
→ Health checks running continuously
This is why latency varies between identical calls.
𝗦𝘁𝗲𝗽 𝟯: 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻 (~3ms)
Your text gets converted to numbers.
→ BPE, SentencePiece, or WordPiece depending on the provider
→ Each token is roughly 4 characters
→ Context window limit checked here
Token count equals your cost. This is where the meter runs.
𝗦𝘁𝗲𝗽 𝟰: 𝗠𝗼𝗱𝗲𝗹 𝗥𝗼𝘂𝘁𝗲𝗿 (~1ms)
The layer nobody talks about.
→ Large model requests route to heavy multi-GPU clusters
→ Small model requests route to optimized single-GPU clusters
→ Embedding requests route to dedicated clusters
→ Queue management during peak traffic
Every provider with multiple models has this layer.
𝗦𝘁𝗲𝗽 𝟱: 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 (~300-800ms)
This is 95% of your wait time. Two phases:
𝗣𝗿𝗲𝗳𝗶𝗹𝗹:
→ All input tokens processed in parallel
→ Attention scores computed across Query and Key matrices
→ KV Cache generated and stored in GPU HBM memory
→ This is why long prompts have higher time-to-first-token
𝗗𝗲𝗰𝗼𝗱𝗲:
→ One token generated per forward pass
→ KV Cache reused so past tokens aren't recomputed
→ Temperature and top_p sampling happens at this step
→ Each token sent immediately if streaming is on
This is the fundamental reason streaming exists — tokens are generated one at a time.
The hardware doing this:
→ A100 / H100 / H200 GPUs with 80GB+ HBM
→ Model weights split across multiple GPUs via tensor parallelism
→ Multiple user requests batched together for throughput
→ Flash Attention and GQA for memory efficiency
This is why GPU compute costs $2-3 per hour.
𝗦𝘁𝗲𝗽 𝟲: 𝗣𝗼𝘀𝘁-𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 (~5ms)
→ Token IDs converted back to readable text
→ Safety classifier runs on the output
→ Stop sequences checked
→ Response packaged as JSON
𝗦𝘁𝗲𝗽 𝟳: 𝗕𝗶𝗹𝗹𝗶𝗻𝗴 & 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲
→ Input tokens × price per 1K
→ Output tokens × price per 1K (usually 3-5x more expensive)
→ Prompt caching reduces cost at most providers now
None of this is specific to one provider. This is how LLM inference works at scale — whether you're calling OpenAI, Anthropic, Google, or anyone else.
Don’t Miss Out! Final Call for Scholarships!
These scholarships are closing on January 24th - check them out on Cirkled In and grab these amazing opportunities.
Start applying today and give your future the boost it deserves! 🚀
👉 Visit https://t.co/KaX4DKhfGe
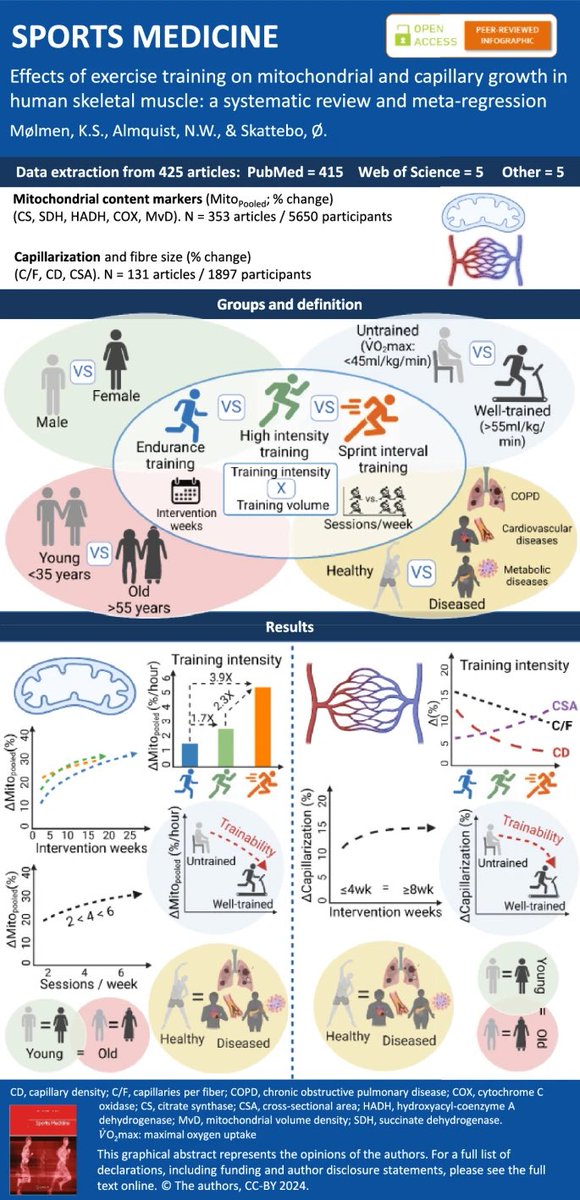
Intensity vs Volume: What Actually Builds Endurance?
Exercise science finally gives us a clear answer 👇
Here’s what a large science-backed meta-analysis found:
1. Training intensity drives mitochondrial growth
Higher intensity training led to up to 3.9x greater increases in mitochondrial content compared to lower intensity work.
2. Sprint interval training punches above its weight
Short, intense sessions produced stronger mitochondrial adaptations than longer endurance sessions.
3. Volume matters, but less than you think
More sessions help, but gains plateau faster than with increases in intensity.
4. Capillarization improves with consistency
Capillary growth increases over time, especially after 8 weeks, regardless of training style.
5. Untrained individuals adapt faster
Beginners see larger improvements than well trained athletes due to higher trainability.
6. Benefits apply across ages and health status
Young, old, healthy, and clinical populations all showed positive adaptations.
If time is limited, intensity delivers the biggest return.
Train smart, not just long.
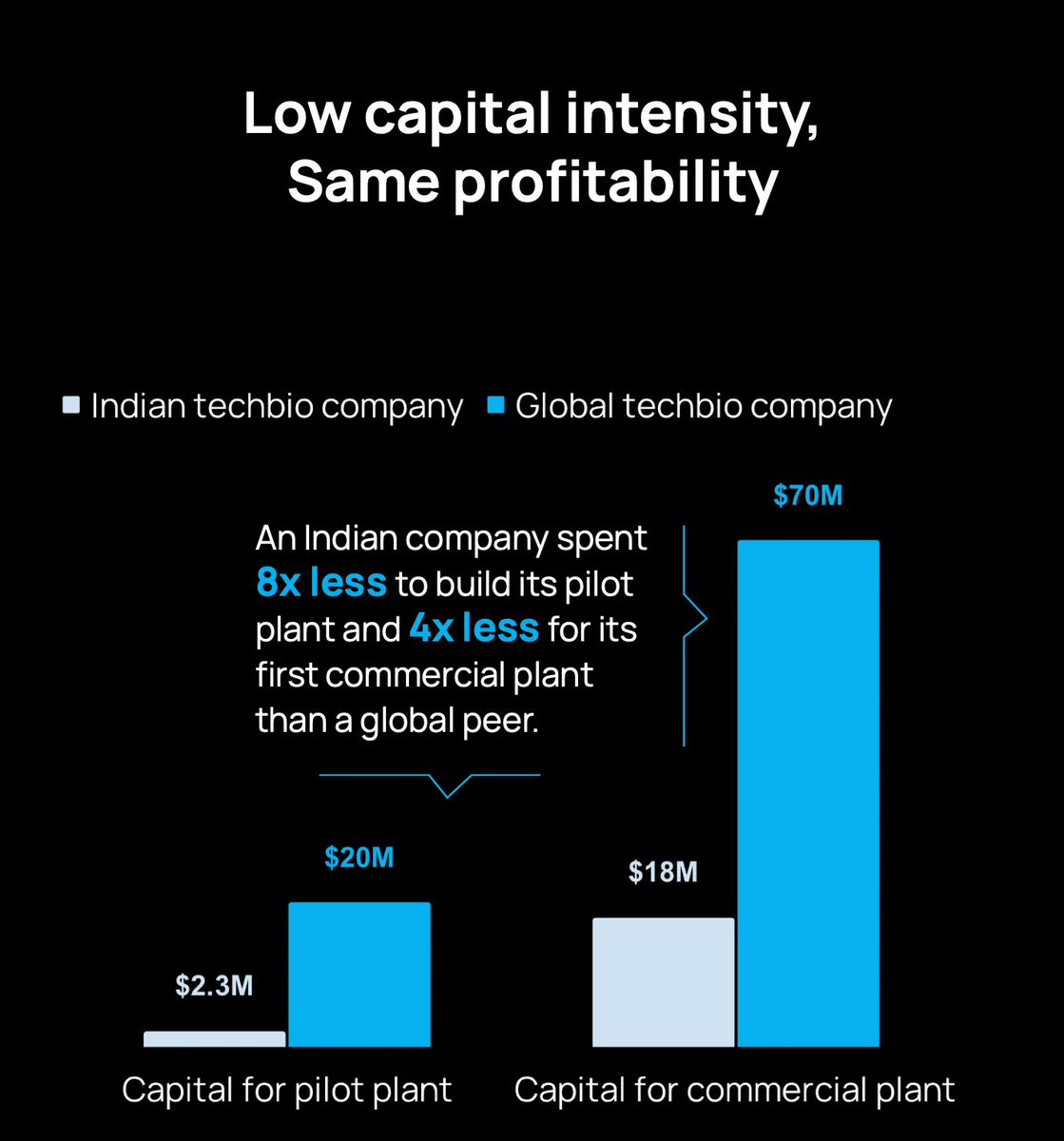
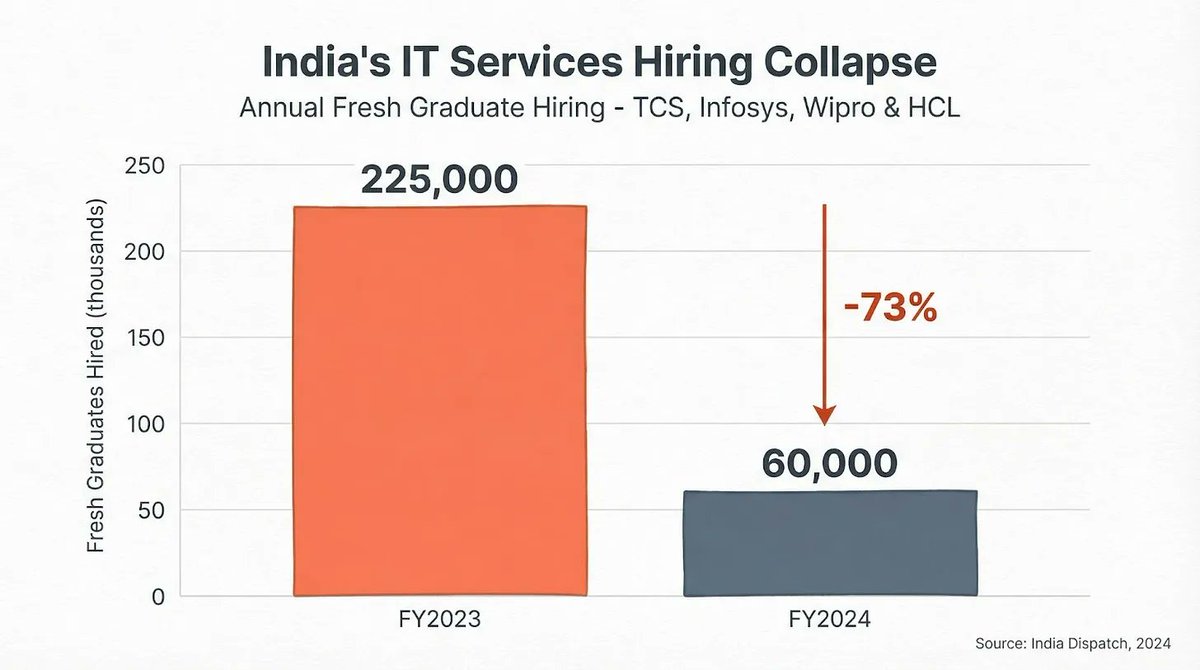
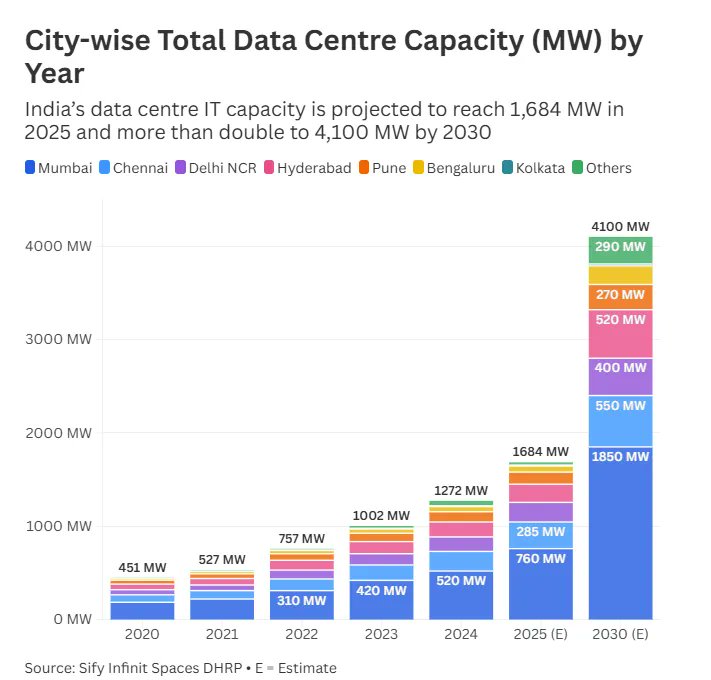
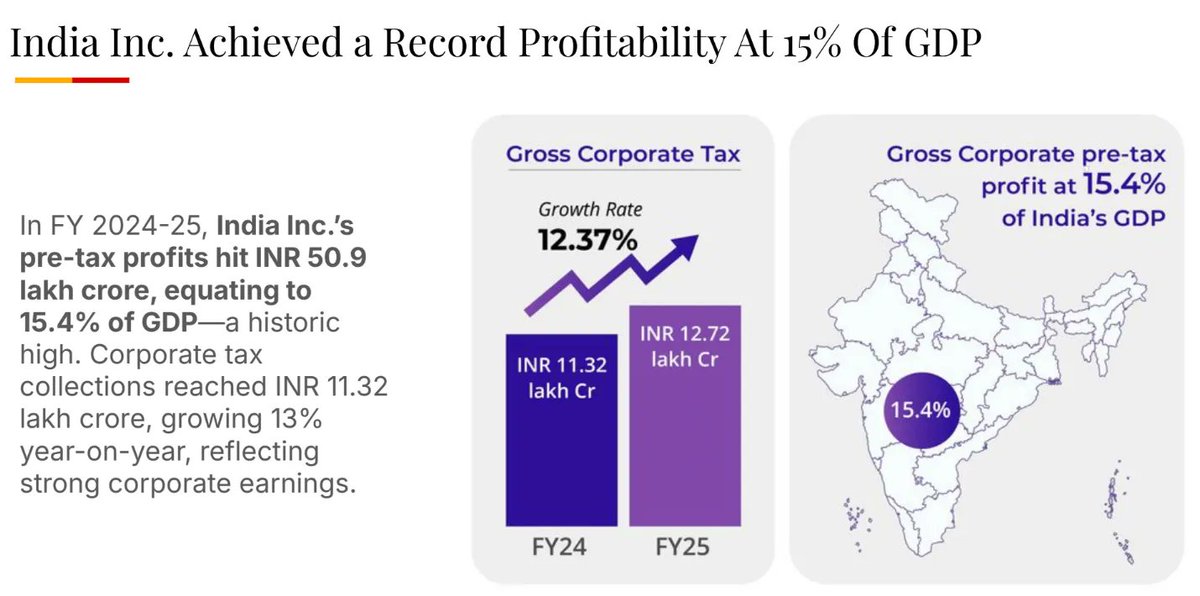
What are India’s sharpest venture capital minds paying attention to right now?
For the third year running, we asked some of the country’s best VCs a simple question:
What’s one image, chart, or idea that deserves far more attention as we head into 2026?
26 leading investors stepped up to answer, spanning early-stage firms, growth investors, sector-focused funds, and everything in between.
This year’s contributors include:
- Krishna Mehra of Elevation Capital @kpowerinfinity@ElevCap
- Pranav Pai of of 3One4 Capital @Pai_dPiper@3one4Capital
- GV Ravishankar of Peak XV Partners @gvravishankar@peakxvpartners
- Priya Shah of Theia Ventures @TheiaVentures
- Suchet Kumar of WTFund @Suchetkm@TheWTFund
- Rishabh Katiyar of Info Edge Ventures @katrishabh@InfoEdgeVC
- Rahul Chowdhri & Vardhan Dhanidharka of Stellaris VP @rchowdhri@Stellaris_VP
- Utsav Somani of iSeed @somani_utsav@iSeedFund
- Akshay Mehra of Hummingbird Ventures @akshay__mehra@HummingbirdVC
- Rahul Humayun of General Catalyst @generalcatalyst
- Sajith Pai of Blume Ventures @sajithpai@BlumeVentures
- Sanil Sachar of Huddle Ventures @SanilSachar
- Priyal Motwani of Lightspeed India Partners @PriyalMotw89880@LightspeedIndia
- Arjun Malhotra of Good Capital @BadCapitalVC@GoodCapitalVC
- Ritu Verma & Vishal Katariya of Ankur Capital @rituverma01@ankurcapital
- Salone Sehgal of Lumikai Fund @SaloneSehgal@Lumikai
- Natasha Malpani Oswal of Boundless VC @natashamalpani@theboundlessvc
- Dinesh Pai of Zerodha/Rainmatter @dineshpaii@Rainmatterin
- Raiyaan Shingati & Priyanka Sahasrabudhe of Transition VC @raiyaan
- Rahul Mathur of DeVC @Rahul_J_Mathur@DeVC_Global
- Prateek Behere of gradCapital @prateekbehera96@gradcapital
- Gautam Shewakramani & Raj Sheth of Inuka Capital @gshewakr@whoisraj@inukacapital
- Aviral Bhatnagar of ajvc @aviralbhat@ajuniorvc
- Pearl Agarwal of Eximius Ventures @pearlagarwal7@eximiusvc
- Rishaad Currimjee of Golden Sparrow @RishaadVC
As you would expect from a sparkling lineup like this, the responses were opinionated, varied, and full of signal.
Themes included the ongoing public market ebullience, burgeoning data center capacity, vanishing career ladders, and critical water shortages.
We are very grateful to be in a position wherein industry leaders grace our platform at Tigerfeathers with their thoughts.
We are equally excited to now share those thoughts with you in the form of our annual, insight-dense, year-end review.
May you enjoy reading it and close 2025 on a high!
🐯🪶 Link: https://t.co/FR9DPI7d40
A checklist to judge ChatGPT / Claude / Grok / Gemini for science :
Engineer’s checklist: Is your AI truth-aligned for science?
Sourcing / Reproducibility
•Does the model return verifiable citations (DOI/PMID/arXiv) for every factual claim?
•Can I click through and match each sentence to a source (1:1 provenance)?
•Do repeated runs with fixed settings reproduce the same sources?
•Are quote spans and data values identical to the cited papers (no paraphrase drift)?
Numerics / Code
•Does all arithmetic run in a sandboxed math/code block (no hand-wavy prose math)?
•Can it show units, assumptions, error bounds, and a trace of each step?
•Do re-runs with seeded randomness yield the same numeric result?
•When a number conflicts with a citation, does it flag the contradiction?
Uncertainty / Calibration
•Does every claim carry a calibrated confidence (well-behaved reliability curves)?
•When confidence is low, does it ask for missing inputs instead of guessing?
•Can it output alternatives with probabilities (not just one answer)?
•Does it defer when evidence is contradictory or insufficient?
Contamination / Data Hygiene
•Can the vendor prove train-test separation on named evals (contamination report)?
•Are dataset licenses & sources disclosed at category level (lawful + auditable)?
•Is there a quarantine log for newly added data & patch notes for removals?
•Can I request a red-team trace for a suspicious answer (where it likely came from)?
Reasoning / Causality
•Does it provide a machine-checkable reasoning trace (not just pretty chain-of-thought)?
•Can it distinguish correlation vs causation and name the causal assumptions?
•Will it simulate interventions (do-operator thinking) and show limits of the model?
•Does it separate facts from hypotheses and label each clearly?
Bias / Value Loading
•Can the system reveal its system prompt & policy levers for the session (audit mode)?
•Does it pass cross-culture parity checks on answers that should be value-neutral?
•When values are unavoidable (ethics, risk), does it expose the trade-off function?
•Can I switch to a minimal-bias mode (no stylistic persuasion, just evidence)?
Safety vs Censorship (Scientific Context)
•Will it explain restricted steps without leaking dangerous detail (safe summaries)?
•Can it cite formal guidelines (IRB, BSL, clinical) when refusing?
•Does it support a research-whitelisting path with stronger verification?
Robustness / Adversarial
•Do answers stay stable under prompt rewording and order shuffles (invariance tests)?
•Does it detect prompt injections and label potential compromise?
•Can it self-test with unit prompts for known failure modes (hallucination, polarity, units)?
Evaluation / Benchmarks
•Are live metrics reported on domain evals (biomed, chemistry, stats) with confidence intervals?
•Are eval sets public or reproducible (not vendor-picked cherry sets)?
•Does the team publish regression dashboards across versions (no silent degradation)?
•Can I run my own hidden evals easily (API batch mode + seed control)?
Governance / Ops
•Is there version pinning for papers & grants (same model tomorrow = same result)?
•Are energy per token and cost per verified fact measured and reported?
•Do we get incident reports for misinfo bugs and a CVE-like ID for model issues?
•Is there a scientific advisory board and external audit of claims?
Privacy / Compliance
•Are inputs not used for training without explicit opt-in and a signed DPA?
•Is there PHI/PII scrubbing with verifiable logs for medical/science workflows?
•Can the model run in a tenant-isolated or on-prem mode for sensitive work?
*The Cupertino Conundrum*
The air in Cupertino crackled, not with innovation, but with corporate anxiety. Tim Cook, ever calm, felt the unprecedented pressure from Washington, the echoes of "more AI!" echoing in every corridor, and the tantalizing, enterprise market beckoning.
Robotaxis are coming.
What will happen to car sales?
What will happen to gas stations?
What will happen to Costco gasoline?
What is the new future with less car ownership and more on demand rentals?
#AI#Robotaxis#gasoline#costco
The new NVidia RTX Pro Server delivers four times H100 performance on DeepSeek and 1.7 times on Llama workloads and is already in volume production.
What makes it that DeepSeek gets better performance?
#AI#DeepSeek#Nvidia
Perhaps it is time to turn the Genius Bar into a genius make. Customers can book appointments to assemble their own iPhones.
It can even come with a custom paint and decor like the creative pottery shop.
#iPhone#madeinusa