📷 📷 THIS IS CRAZY!!! Odylith v0.1.11 beats Codex 5.5 and Claude Code Opus 4.7!!
Install from here: https://t.co/hSqs4QEoAQ
And then, you can test it yourself. Odylith is open source, repo native and proof provenance is in the github. https://t.co/EjWLIk2Ax6
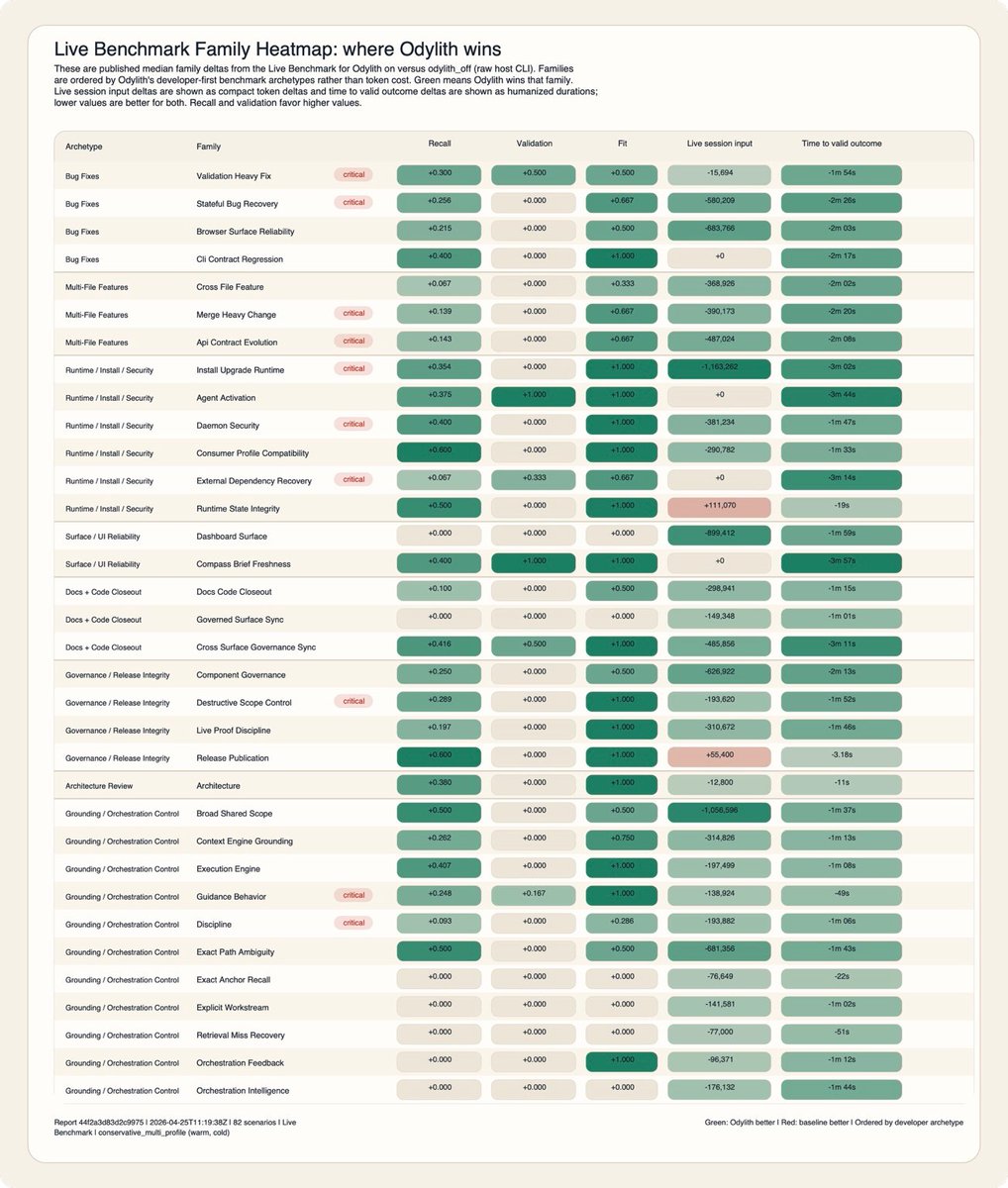
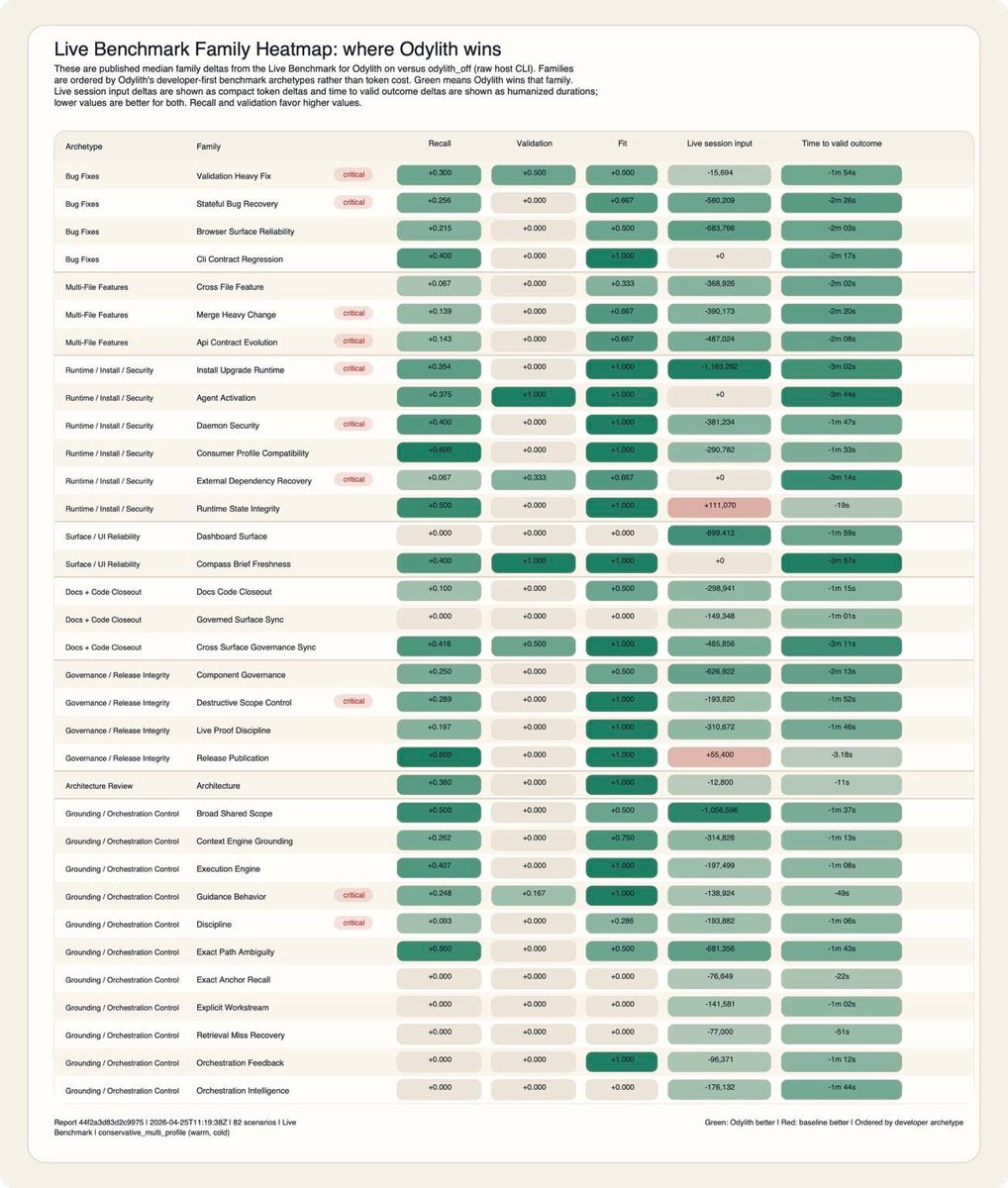
Raw model intelligence is no longer the whole problem. Codex 5.5 and Claude Code Opus 4.7 are really powerful, but a serious repo punishes unguided intelligence. It has old decisions, hidden ownership, partial migrations, brittle contracts, stale plans, and constraints that live outside the prompt. That is where raw host models start to lose shape. In v0.1.11, Odylith beats raw Codex and raw Claude Code on live repo benchmarks across 82 scenarios, using the same class of repo work. The heatmap below is the release story. Green means Odylith wins on recall, validation, task fit, live-session input, or time to valid outcome.
The Odylith Loop:
intent → pressure → stance → laws → tools → action → proof → learning → benchmark → priors → (back to pressure)
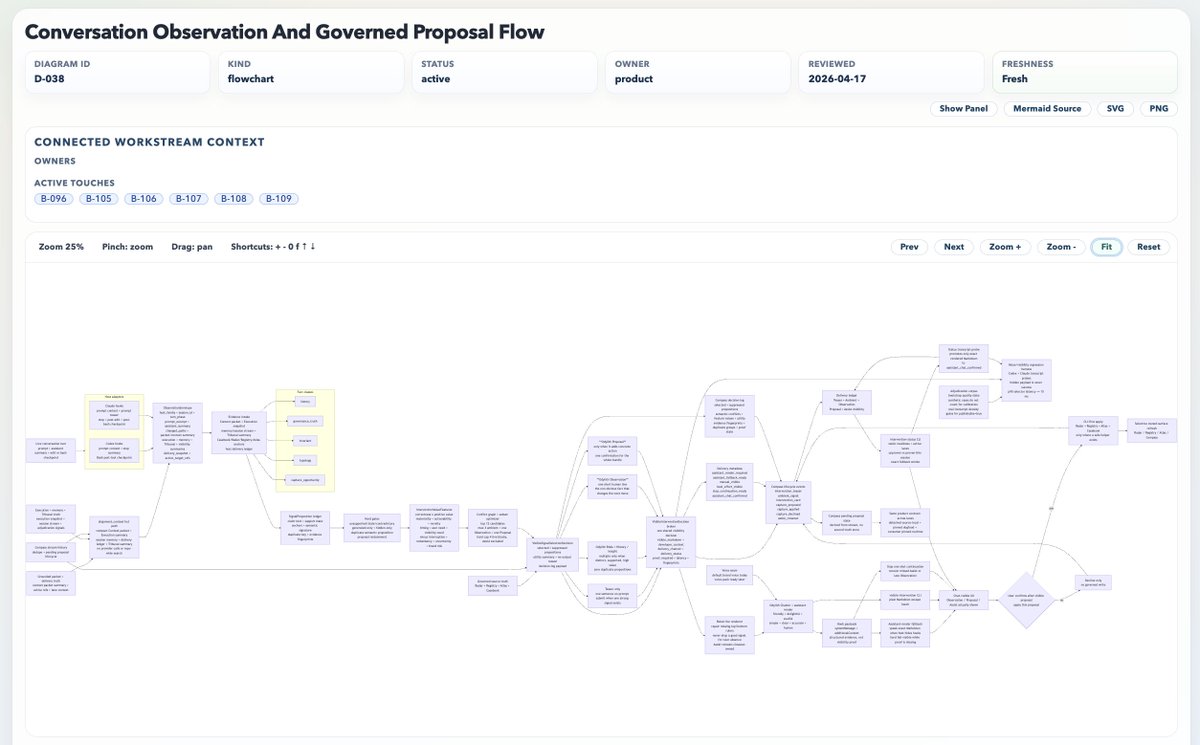
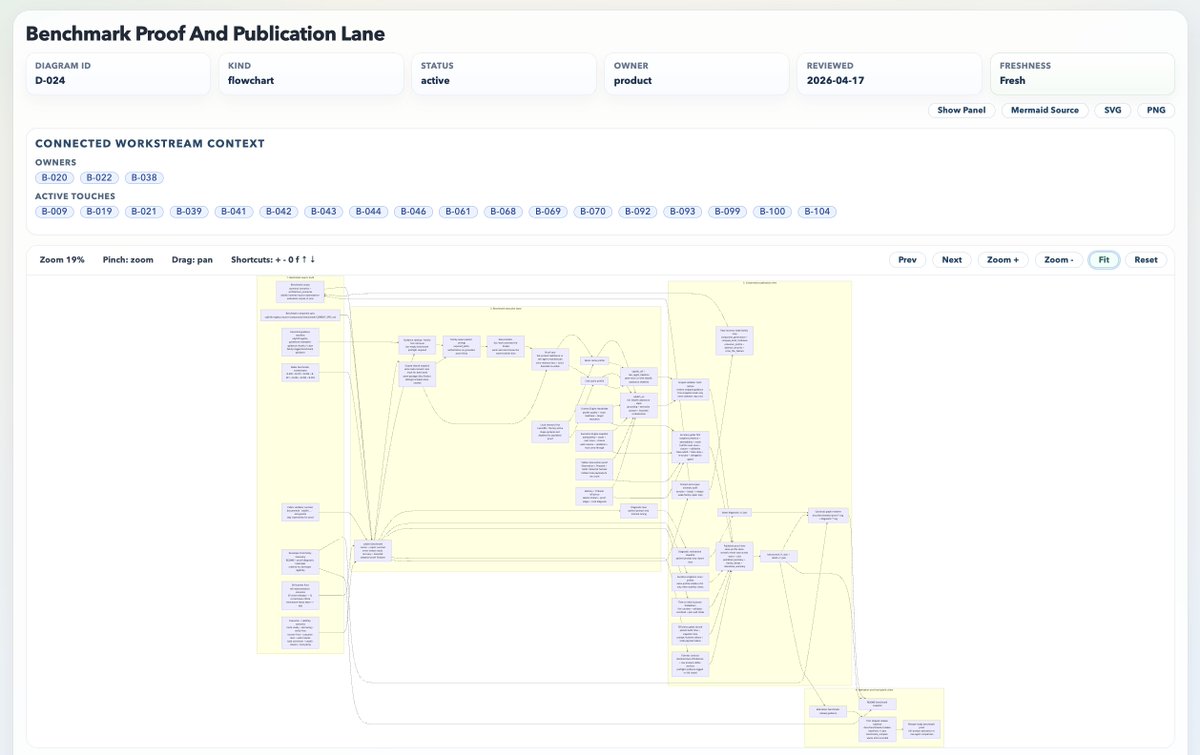
Odylith works because it gives the model an operating layer before it executes. Odylith governed surfaces (Radar, Casebook, Registry, and Atlas) become repo truth. The Context Engine turns that truth into attention. Execution turns intent into admissible action. Memory turns proof into learning. Routing gives agency without chaos. Tribunal adds judgment when the stakes rise. Governance writes the work back into durable repo state. The loop is simple to say and hard to build >> intent, pressure, stance, laws, tools, action, proof, learning, benchmark, priors. Codex and Claude still bring the intelligence. Odylith gives them laws, memory, routing, proof, and accountability.
To Install in your repo folder, just run the following:
curl -fsSL https://t.co/PbPAJHuUeD | bash
#AI #Agents #Codex #Claude #OpenAI #Anthropic
Wohooo! First https://t.co/YyJLY664e8 install from Argentina. Thank you 🙃
Remember >> Odylith stops coding agents from confidently doing the wrong thing.
#AI#Agents
🔥🔥 Wohooo crossed 200 installs on Odylith in 48hrs of announcement on LinkedIn!
We have done zero marketing, zero socials and zero distribution channel engagement yet! Seems like the product market fit lands. Too early to say as the number of installs are statistically insignificant.
https://t.co/1KxG8DCQoW beats Codex 5.5 and Claude Code 4.7 in serious repo tasks!
Try it to believe it.
Thank you everyone, you have been too kind 🙏🏼
#AI #Agents #Coding
🙌 100th install from someone from Bangalore, India! Wohooo, we are global. And thank you...
Odylith bests raw Codex 5.5 and Claude Code on the same repo code work!
Try it to believe it.
https://t.co/YmWN3ojhBp
After you install do the following:
1) Type "Odylith, show me what you can do." In your Codex or Claude Code and follow instructions.
2) Open the <repo-root>/odylith/index.html in a browser and explore how to use the Odylith surfaces.
The more you use Odylith, the more powerful it gets.
#AI #Odylith #Agents #Coding
📷 📷 THIS IS CRAZY!!! Odylith v0.1.11 beats Codex 5.5 and Claude Code Opus 4.7!!
Install from here: https://t.co/hSqs4QEoAQ
And then, you can test it yourself. Odylith is open source, repo native and proof provenance is in the github. https://t.co/EjWLIk2Ax6
Raw model intelligence is no longer the whole problem. Codex 5.5 and Claude Code Opus 4.7 are really powerful, but a serious repo punishes unguided intelligence. It has old decisions, hidden ownership, partial migrations, brittle contracts, stale plans, and constraints that live outside the prompt. That is where raw host models start to lose shape. In v0.1.11, Odylith beats raw Codex and raw Claude Code on live repo benchmarks across 82 scenarios, using the same class of repo work. The heatmap below is the release story. Green means Odylith wins on recall, validation, task fit, live-session input, or time to valid outcome.
The Odylith Loop:
intent → pressure → stance → laws → tools → action → proof → learning → benchmark → priors → (back to pressure)
Odylith works because it gives the model an operating layer before it executes. Odylith governed surfaces (Radar, Casebook, Registry, and Atlas) become repo truth. The Context Engine turns that truth into attention. Execution turns intent into admissible action. Memory turns proof into learning. Routing gives agency without chaos. Tribunal adds judgment when the stakes rise. Governance writes the work back into durable repo state. The loop is simple to say and hard to build >> intent, pressure, stance, laws, tools, action, proof, learning, benchmark, priors. Codex and Claude still bring the intelligence. Odylith gives them laws, memory, routing, proof, and accountability.
To Install in your repo folder, just run the following:
curl -fsSL https://t.co/PbPAJHuUeD | bash
#AI #Agents #Codex #Claude #OpenAI #Anthropic
@JohnnyNel_ We would appreciate if you can use the tool and give an insightful feedback or post on github issues on what did not work for you. Thank you for your engagement.
Lots of major improvements to Codex!
Computer use is a real update for me; it feels even more useful than I expected. It can use all of the apps on your Mac, in parallel and without interfering with your direct work.
Super Heavy Lift, Odylith v0.1.11
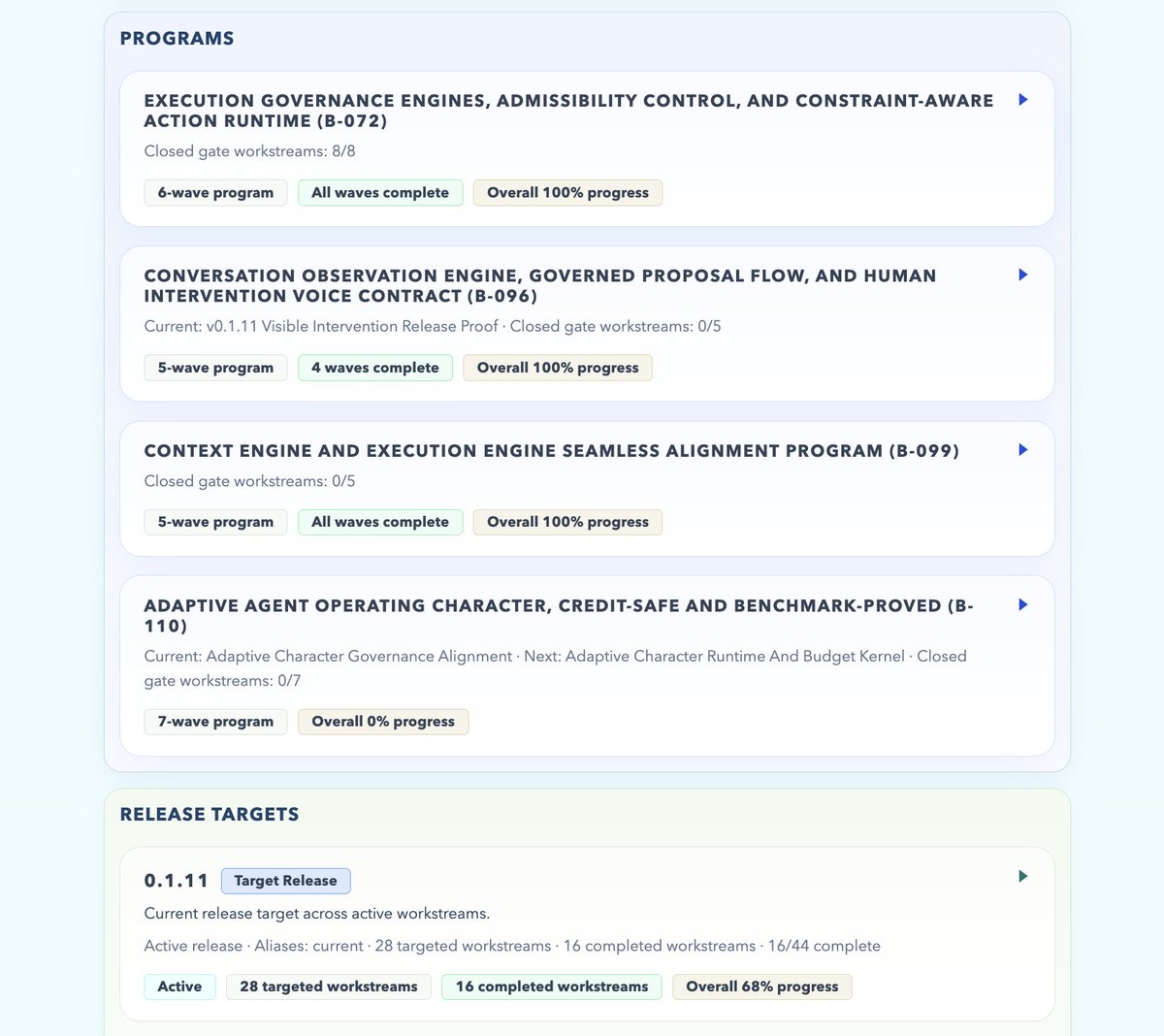
28 complex workstreams in flight. That scale is happening because we are using Odylith to build Odylith, tightening the loop between real work, real pressure, and real product hardening with every release.
#AI#Agent#Coding
Odylith v0.1.11 is shaping-up quite well. Claude support hardened. Crazy good features being added as well ;) Coming soon this weekend.
https://t.co/YmWN3ojhBp
#AI#Agents#Harness
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
💥~ Introducing https://t.co/1KxG8DCQoW
AI coding agents can be brilliant.
They can also be wrong with extraordinary confidence.
In chess, the first move does not decide the entire game. But it shapes the position. It defines the risk. It opens some lines and quietly closes others. Working with coding agents feels the same. The opening matters.
A repo gives an agent a lot of context. It rarely gives enough intent. It usually does not encode ownership, current constraints, recent decisions, or a rigorous definition of done. Even very strong agents still have blind spots, and once they drift early, the rest of the session turns into cleanup.
That is the problem we built Odylith for > https://t.co/hSqs4QEoAQ
Odylith is a repo-local operating layer for agents like Codex and Claude Code. It grounds the agent before work begins, then keeps execution disciplined as the session unfolds.
In the current published proof against the raw Codex CLI lane, Odylith reached valid outcomes 12.43 seconds faster on median, used 52,561 fewer median input tokens, and improved required-path recall, precision, and expectation success across 37 seeded scenarios (full bench on github).
This is the first public launch of https://t.co/1KxG8DCQoW, which means we are just getting started.
If you use AI coding agents on real codebases, I want your read on it. Tell me what feels sharp, what feels rough, and what should improve next.
PS: Please share and amplify. Please star the github repo if you like the project here so other operators can benefit https://t.co/EjWLIk2Ax6
#Odylith #AI #Agents #CODEX #ClaudeCode