AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]
“Staying calm during a crisis is worth far more than airtime on CNBC” 😎
@VivianBala today at @CNBC Converge Live
A few more interesting points shared by Mr. Vivian Balakrishnan today:
➡️ Trust must be built and it cannot be assumed. Trust is one of the most effective ways to reduce transactional costs.
➡️ The future is not just about oil and gas prices, it’s an opportunity to diversify and prepare for what comes next.
➡️ As more global trade flows through the Strait of Malacca - at points as narrow as just 2 nautical mile, this critical hub must remains protected.
This is AWESOME... Some guy just sequenced his entire DNA genome on his kitchen table 🧬🧪
It tells his cancer risk, drug responses, what his kids will inherit, and which diseases are coming decades before the symptoms.
Your genome is a 3.2 billion letter source code that predicts more about your health than any other test in existence. Almost no one has ever read their own.
This used to require a hospital, a specialist, and a referral that most doctors won't write. The raw data would sit in a medical record you'd never see.
Until now.
Here's how he did it:
→ Rubbed a cheek swab against the inside of his mouth for 60 seconds
→ Extracted the DNA from his cells using a $150 kit
→ Prepped the DNA for sequencing with enzymes that attach a motor protein to each strand
→ Loaded the sample onto a nanopore device the size of a highlighter, plugged into a MacBook
The device works by pulling single strands of DNA through holes one atom wide. As each letter passes through, it changes the electrical resistance in a tiny but measurable way. A neural network listens to the signal and reconstructs the sequence. 48 hours later, he had his full genome on his hard drive.
The data never touched a server. No spit kit in the mail. No company owning his most sensitive biological information. No risk of the whole thing getting auctioned off in a bankruptcy, which is exactly what happened to 23andMe's 15 million customers earlier this year.
AI is unlocking personal health in a way that has been impossible. We're still so early.
If "superintelligence" is defined not as a system that already knows almost everything at launch but as one with extremely high learning speed, then safe AGI is best viewed as a super-capable learner, iteratively educated via incremental, tightly monitored deployment @ilyasut
https://t.co/wy0lYFhR4y
Great talk by @BradSmi Vice Chair and President of @Microsoft ⬇️
➡️ How to stay relevant in the age of AI? Focus on the uniquely human advantage - the 5 Cs:
💪 Curiosity
💪 Communication
💪 Compassion
💪 Courage
💪 Creativity
➡️ #AI will be the most defining technology of the next 25 years.
➡️ Innovation alone isn’t enough - diffusion (adoption) matters just as much.
➡️ Skilling has always been at the heart of tech adoption.
➡️ #Singapore continues to rank as a global leader in AI adoption, with Microsoft investing an additional $50B across Singapore, Indonesia, Malaysia and Thailand.
Thanks @IMDAsg for organizing!
If "superintelligence" is defined not as a system that already knows almost everything at launch but as one with extremely high learning speed, then safe AGI is best viewed as a super-capable learner, iteratively educated via incremental, tightly monitored deployment @ilyasut
https://t.co/wy0lYFhR4y
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
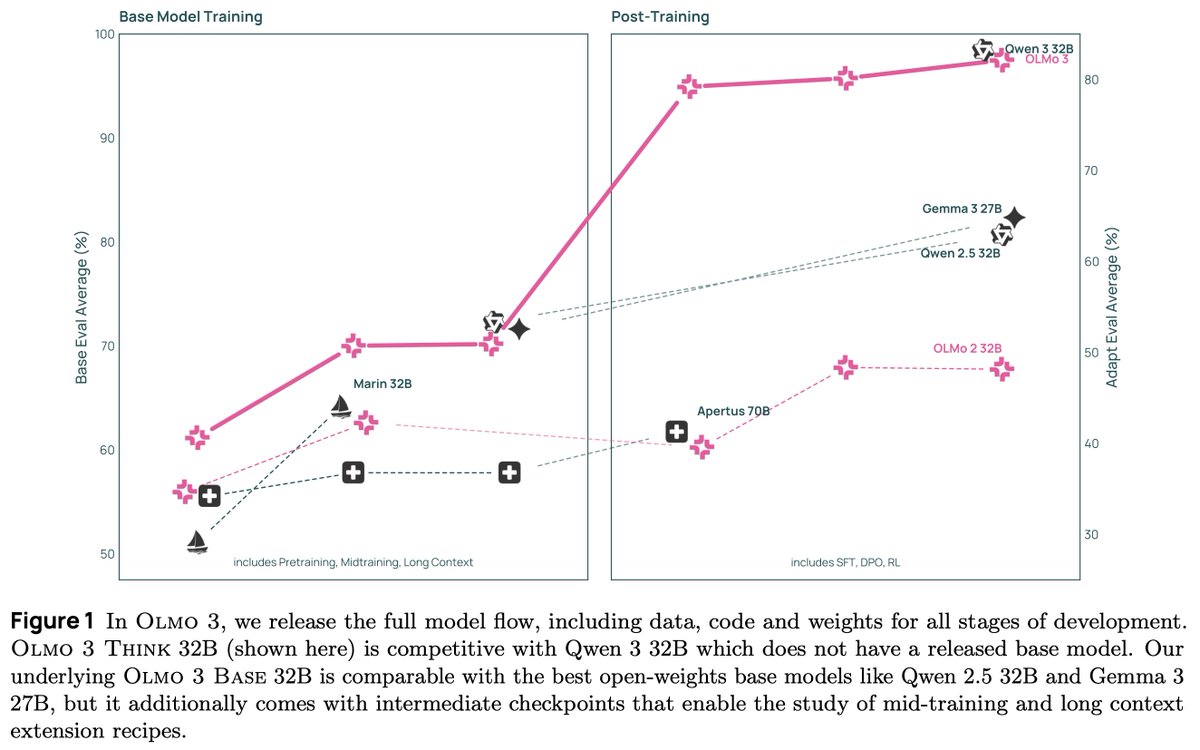
This is a big milestone for Ai2 and the Olmo project. These aren’t huge models (more on that later), but it’s crucial for the viability of fully open-source models that they are competitive on performance – not just replications of models that came out 6 to 12 months ago. As always, all of our models come with full training data, code, intermediate checkpoints, training logs, and a detailed technical report. All are available today, with some more additions coming before the end of the year.
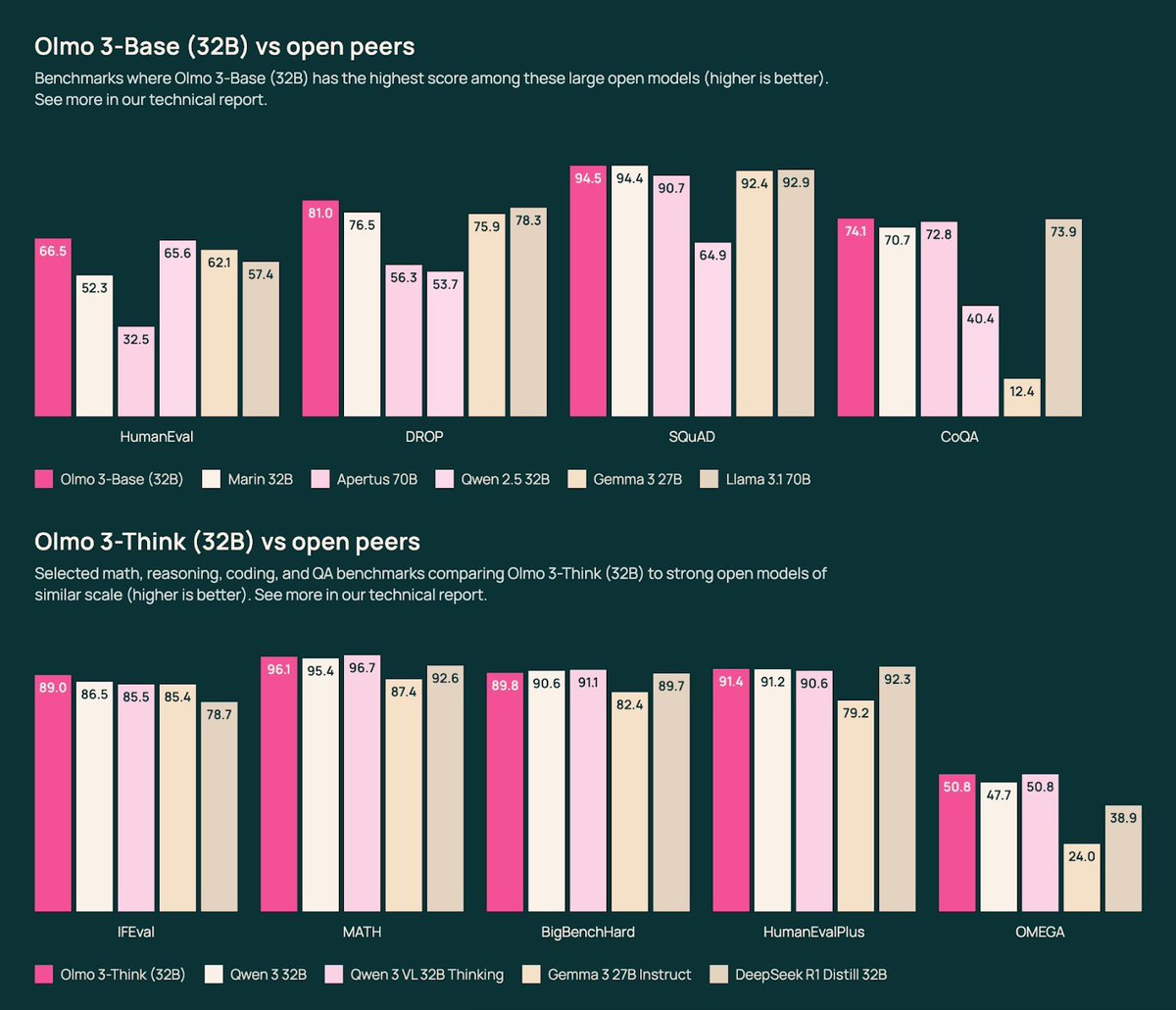
As with OLMo 2 32B at its release, OLMo 3 32B is the best open-source language model ever released. It’s an awesome privilege to get to provide these models to the broader community researching and understanding what is happening in AI today.
Base models – a strong foundation
Pretraining’s demise is now regularly overstated. 2025 has marked a year where the entire industry rebuilt their training stack to focus on reasoning and agentic tasks, but some established base model sizes haven’t seen a new leading model since @alibaba_qwen's Qwen 2.5 in 2024. The Olmo 3 32B base model could be our most impactful artifact here, as Qwen3 did not release their 32B base model (likely for competitive reasons). We show that our 7B recipe competes with Qwen 3, and the 32B size enables a starting point for strong reasoning models or specialized agents. Our base model’s performance is in the same ballpark as Qwen 2.5, surpassing the likes of Stanford’s Marin (@stanfordAILab) and Gemma 3 (@GoogleDeepMind), but with pretraining data and code available, it should be more accessible to the community to learn how to finetune it (and be confident in our results).
We’re excited to see the community take Olmo 3 32B base in many directions. 32B is a loved size for easy deployment on single 80GB+ memory GPUs and even on many laptops, like the MacBook I’m using to write this on.
A model flow – the lifecycle of creating a model
With these strong base models, we’ve created a variety of post-training checkpoints to showcase the many ways post-training can be done to suit different needs. We’re calling this a “Model Flow.” For post-training, we’re releasing Instruct versions – short, snappy, intelligent, and useful especially for synthetic data en masse (e.g. recent work by Datology @datologyai on OLMo 2 Instruct), Think versions – thoughtful reasoners with the performance you expect from a leading thinking model on math, code, etc. and RL Zero versions – controlled experiments for researchers understanding how to build post-training recipes that start with large-scale RL on the base model.
The first two post-training recipes are distilled from a variety of leading, open and closed, language models. At the 32B and smaller scale, direct distillation with further preference finetuning and reinforcement learning with verifiable rewards (RLVR) is becoming an accessible and highly capable pipeline. Our post-training recipe follows our recent models: 1) create an excellent SFT set, 2) use direct preference optimization (DPO) as a highly iterable, cheap, and stable preference learning method despite its critics, and 3) finish up with scaled up RLVR. All of these stages confer meaningful improvements on the models’ final performance.
Instruct models – low latency workhorse
Instruct models today are often somewhat forgotten, but the likes of @aiatmeta Llama 3.1 Instruct and smaller, concise models are some of the most adopted open models of all time. The instruct models we’re building are a major polishing and evolution of the Tülu 3 pipeline – you’ll see many similar datasets and methods, but with pretty much every datapoint or training code being refreshed. Olmo 3 Instruct should be a clear upgrade on Llama 3.1 8B, representing the best 7B scale model from a Western or American company. As scientists we don’t like to condition the quality of our work based on its geographic origins, but this is a very real consideration to many enterprises looking to open models as a solution for trusted AI deployments with sensitive data.
Building a thinking model
What people have most likely been waiting for are our thinking or reasoning models, both because every company needs to have a reasoning model in 2025, but also to clearly open the black box for the most recent evolution of language models. Olmo 3 Think, particularly the 32B, are flagship models of this release, where we considered what would be best for a reasoning model at every stage of training.
Extensive effort (ask me IRL about more war stories) went into every stage of the post-training of the Think models. We’re impressed by the magnitude of gains that can be achieved in each stage – neither SFT nor RL is all you need at these intermediate model scales.
First we built an extensive reasoning dataset for supervised finetuning (SFT), called Dolci-Think-SFT, building on very impactful open projects like OpenThoughts3, Nvidia’s Nemotron Post-training, Prime Intellect’s SYNETHIC-2, and many more open prompt sources we pulled forward from Tülu 3 / OLMo 2. Datasets like this are often some of our most impactful contributions (see the Tülu 3 dataset as an example in Thinking Machine’s Tinker :D @thinkymachines @tinker_api – please add Dolci-Think-SFT too, and Olmo 3 while you’re at it, the architecture is very similar to Qwen which you have).
For DPO with reasoning, we converged on a very similar method as HuggingFace’s (@huggingface) SmolLM 3 with Qwen3 32B as the chosen model and Qwen3 0.6B as the rejected. Our intuition is that the delta between the chosen and rejected samples is what the model learns from, rather than the overall quality of the chosen answer alone. These two models provide a very consistent delta, which provides way stronger gains than expected. Same goes for the Instruct model. It is likely that DPO is helping the model converge on more stable reasoning strategies and softening the post-SFT model, as seen by large gains even on frontier evaluations such as AIME.
Our DPO approach was an expansion of Geng, Scott, et al. "The delta learning hypothesis: Preference tuning on weak data can yield strong gains." arXiv preprint arXiv:2507.06187 (2025). Many early open thinking models that were also distilled from larger, open-weight thinking models likely left a meaningful amount of performance on the table by not including this stage.
Finally, we turn to the RL stage. Most of the effort here went into building effective infrastructure to be able to run stable experiments with the long-generations of larger language models. This was an incredible team effort to be a small part of, and reflects work ongoing at many labs right now. Most of the details are in the paper, but our details are a mixture of ideas that have been shown already like ServiceNow’s PipelineRL or algorithmic innovations like DAPO and Dr. GRPO. We have some new tricks too!
Some of the exciting contributions of our RL experiments are 1) what we call “active refilling” which is a way of keeping the generations from the learner nodes constantly flowing until there’s a full batch of completions with nonzero gradients (from equal advantages) – a major advantage of our asynchronous approach; and 2) cleaning, documenting, decontaminating, mixing, and proving out the large swaths of work done by the community over the last months.
The result is an excellent model that we’re very proud of. It has very strong reasoning benchmarks (AIME, GPQA, etc.) while also being stable, quirky, and fun in chat with excellent instruction following. The 32B range is largely devoid of non-Qwen competition. The scores for both of our Thinkers get within 1-2 points overall with their respective Qwen3 8/32B models – we’re proud of this!
A very strong 7B scale, Western thinking model is Nvidia’s (@NVIDIAAI) NVIDIA-Nemotron-Nano-9B-v2 hybrid model. It came out months ago and is extremely strong. I personally suspect it may be due to the hybrid architecture making subtle implementation bugs in popular libraries, but who knows.
All in, the Olmo 3 Think recipe gives us a lot of excitement for new things to try in 2026.
RL Zero
DeepSeek R1 showed us a way to new post-training recipes for frontier models, starting with RL on the base model rather than a big SFT stage (yes, I know about cold-start SFT and so on, but that’s an implementation detail). We used RL on base model as a core feedback cycle when developing the model, such as during intermediate midtraining mixing. This is viewed now as a fundamental, largely innate, capability of the base-model.
To facilitate further research on RL Zero, we released 4 datasets and series of checkpoints, showing per-domain RL Zero performance on our 7B model for data mixes focus on math, code, instruction following, and all mixed together.
In particular, we’re excited about the future of RL Zero research on Olmo 3 precisely because everything is open. Researchers can study the interaction between the reasoning traces we include at midtraining and the downstream model behavior (qualitative and quantitative).
This helps answer questions that have plagued RLVR results on Qwen models, hinting at forms of data contamination particularly on math and reasoning benchmarks (see Shao, Rulin, et al. "Spurious rewards: Rethinking training signals in rlvr." arXiv preprint arXiv:2506.10947 (2025). or Wu, Mingqi, et al. "Reasoning or memorization? unreliable results of reinforcement learning due to data contamination." arXiv preprint arXiv:2507.10532 (2025).)
What’s next
This is the biggest project we’ve ever taken on at Ai2 (@allen_ai), with 60+ authors and numerous other support staff.
In building and observing “thinking” and “instruct” models coming today, it is clear to us that there’s a very wide variety of models that fall into both of these buckets. The way we view it is that thinking and instruct characteristics are on a spectrum, as measured by the number of tokens used per evaluation task. In the future we’re excited to view this thinking budget as a trade-off, and build models that serve different use-cases based on latency/throughput needs.
As for a list of next models or things we’ll build, we can give you a list of things you’d expect from a (becoming) frontier lab: MoEs, better character training, pareto efficient instruct vs think, scale, specialized models we actually use at Ai2 internally, and all the normal things.
This is one small step towards what I see as a success for my ATOM project.
We thank you for all your support of our work at Ai2. We have a lot of work to do. We’re going to be hunting for top talent at NeurIPS to help us scale up our Olmo team in 2026.
This post in full also appears on Interconnects – the full links to the artifacts and paper are below.
Moo, moo, rawr!
Nothing beats hands-on experience, like writing code (without code assistants) managing dimensions, optimizations, and the "minor" details that separate high-level understanding from true expertise
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
We introduce h4rm3l, a language, a synthesizer, and a scalable and explainable dynamic LLM red-teaming toolkit. h4rm3l found > 2.6k new jailbreak attacks targeting @OpenAI, @AIatMeta, and @AnthropicAI LLMs.
📝 https://t.co/BjgHgW66Ru
🌐 https://t.co/GcKvDQcV4g
🧵1/6 👇🏾
Attending @NVIDIAGTC 2025 keynote in person at the fully packed SAP Center in San Jose, California, was an exciting experience.
CEO Jensen Huang, wearing his signature black leather jacket, addressed a crowd of over 25,000 attendees.
👇Here are the key highlights
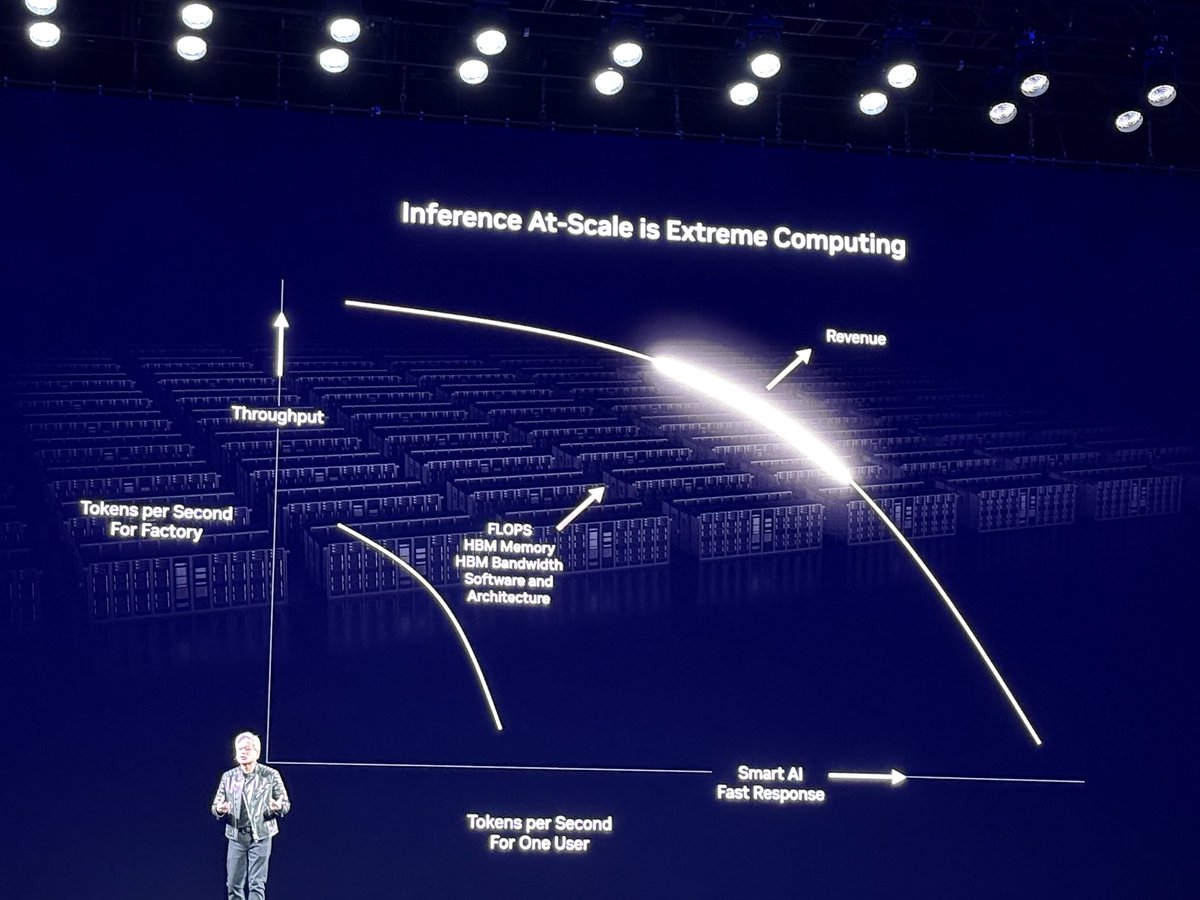
1. Inference Token Surge: Jensen revealed that inference now demands 100 times more tokens than last year, due to:
•The evolution from one-shot inference to complex reasoning models.
•The adoption of reinforcement learning with verifiable results (RLVR).
2. Data Center Investment Boom: A significant increase in data center capital expenditures is projected, escalating from $250 billion in 2022 to an anticipated $1 trillion by 2028.
3. Industry-Specific Software Innovations: The introduction of CUDA-X tailored for various industries was announced, featuring tools like cuPYNUMERIC, Megatron, NCCL, and cuDNN to enhance deep learning applications.
4. Collaboration with General Motors: NVIDIA is partnering with General Motors to develop future self-driving vehicles, integrating the Halos Chip-to-Development AV Safety System to enhance autonomous vehicle safety.
5. Grace Blackwell Production: The Grace Blackwell platform has entered full production.
6. Launch of NVIDIA Dynamo: Huang introduced NVIDIA Dynamo, an open-source distributed inference serving library designed to manage inference at scale. He emphasized balancing high tokens per user with overall system throughput, noting that batching requests can increase system tokens but may also elevate user latency.
7. Upcoming Vera Rubin Platforms: The Vera Rubin NVL144 is scheduled for release in the second half of 2026, followed by the Rubin Ultra NVL576 in the latter half of 2027, signaling NVIDIA’s ongoing innovation in AI infrastructure.
8. NVidia Nemotron Super 49B model.
Awesome fireside chat with @joetsai1999, Chairman of Alibaba Group @AlibabaGroup
at the @CNBC Converge Live event 👏
Joe Tsai discussed sports, company culture, AI, AGI, and the power of open source.
He openly shared about the intense competition in e-commerce and Alibaba’s challenge with slow decision-making due to multiple approval layers. To address this, he encouraged his leaders to view @AlibabaGroup as two units: e-commerce and cloud computing, while empowering employees to make faster decisions.
He sees AI as a major driver of productivity, impacting 60% of GDP and a $10 trillion TAM. Their focus includes running a cloud computing business benefiting from AI inference and fine-tuning, and leveraging AI in products like e-commerce, mapping, and advertising to optimize conversion rates.
He also emphasized the importance of open source in fostering innovation and enabling the development of cutting-edge AI models.
#CNBCConvergeLive #AI
Awesome to see @Benioff and @RayDalio discussing AI, deep tech, digital labor, agents, investment and innovation at @CNBC converge live 2025 #CNBCConvergeLive
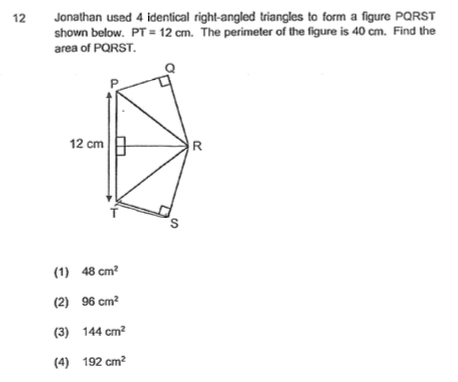
With all the latest AI advancements, you (Calude 3.5, ChatGPT o1, Grok 2) still can't solve a primary school geometry problem. How about solving it before solving AGI? @elonmusk@sama
Meta just released Movie Gen, including two foundation models:
• Movie Gen Video. A 30B parameter model for joint text-to-image and text-to-video generation
* Movie Gen Audio. A 13B parameter model for video- and text-to-audio generation
https://t.co/j6wjLCPgik
#acl2024nlp highlights:
💡@rao2z on LLMs' limitations in planning
💡@barbara_plank on the importance of embracing variation in NLP to address biases and trust issues
💡@AyuP_AI, William & Serana on the ongoing efforts to develop #LLMs in Southeast Asia.
https://t.co/2l3WhxL9XC



























![AndrewYNg's tweet photo. AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]](https://pbs.twimg.com/media/HG7HHJqbsAA3iao.jpg)