⚡ Speed is Iceberg’s biggest Achilles’ heel.
Most teams chase Velox or Gluten for Spark speed. Yet the real wins sit in fast I/O and layers untouched.
We’ve spent years making lakehouse pipelines fast—but this isn’t a table-format debate.
It’s slow I/O, shuffles, and reprocessing driving costs up.
Speed is a stack:
⚡ SIMD
📊 Columnar processing
🔍 Query plans
💾 Fast I/O
🗄️ Metadata
📐 Storage layout
🔗 Indexes
🔄 Merging
Full-stack engine: 3–4× faster than OSS Spark on Iceberg, better price/perf than Photon, no lock-in.
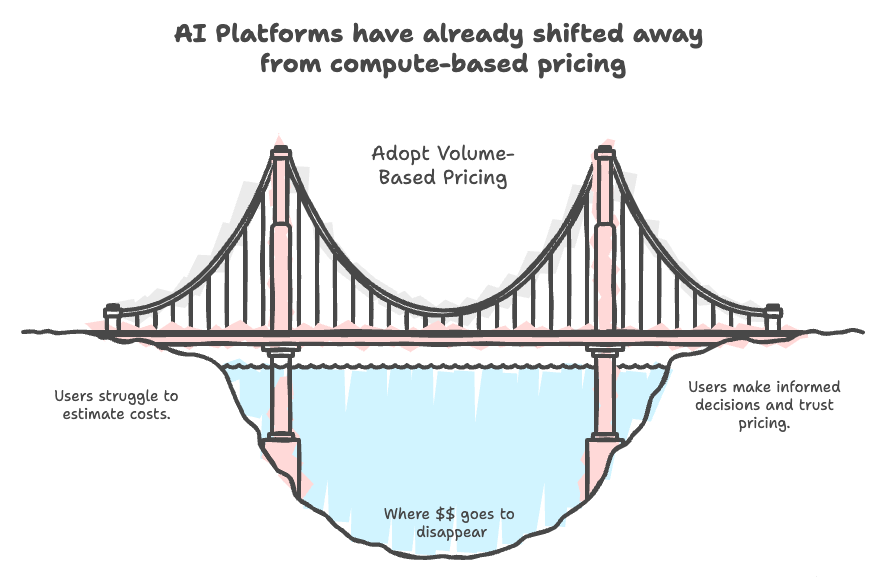
🧠 Anthropic and OpenAI may have taught Databricks and big data vendors a pricing lesson.
🤖 Frontier models price inference by tokens, not GPU FLOPs. it’s intuitive: bigger context or more work costs more.
Cloud data platforms still price by compute: DBUs, EC2 hours, slot time.
Ask: “How many DBUs will this query use on Databricks vs EMR?” 🤷
Ask: “How much data will it scan?” most engineers can answer fast.
Data engineers: hours tuning Spark jobs, yet Hudi, Iceberg, or Parquet reads still take minutes? We've all been there.
Most pipelines bottleneck pre-join. Details below 👇
Everyone assumes usage-based pricing in cloud data is fair and efficient. ⚖️
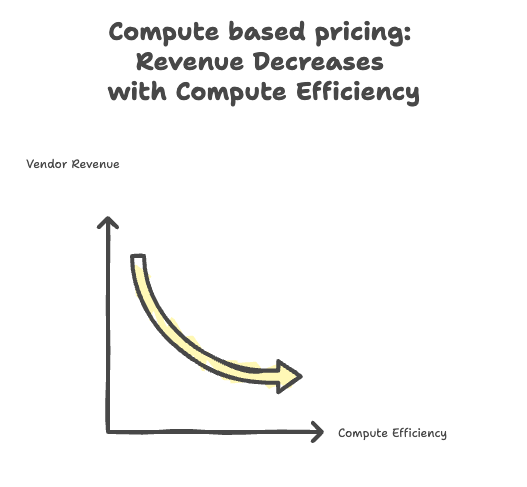
But it has a real problem: It can stop vendors for building faster engines.
Traditional models priced on value—Oracle earned more for standout features.
Now, with EMR or Databricks, bills hinge on compute usage. Customers win from compute efficiency (lower costs), but vendors lose revenue, pushing them to own the compute layer for pricing control.
Sure, usage models offer flexibility, but they misalign incentives long-term.
What's better? We need outcome-based pricing that rewards real value, like queries executed or data processed. 🚀📊
🚀 Quanton now also powers Apache Iceberg natively — delivering 3× faster Spark workloads!
When we launched Quanton, the goal was ambitious: make Spark truly lakehouse-optimized — faster, smarter, and format-aware.
👇
💸 Most teams running Apache Spark™ are burning 30-70% of their compute budget, and they don’t even know it.
Why? Because Spark’s defaults are built for throughput, not efficiency.
On Nov 18, join us for a live session on The True Cost of Spark, and how to cut it in half.
We’ll unpack:
⚙️ Where Spark leaks money (and how to see it in your own jobs)
📉 Real-world fixes that delivered 50–60% cost savings
🚀 How to achieve 2-3x better price/performance, no code changes required
📅 Nov 18, 10am PT
👉Save your spot: https://t.co/MaGCoCucpu
#ApacheSpark #DataEngineering #ETL #Lakehouse
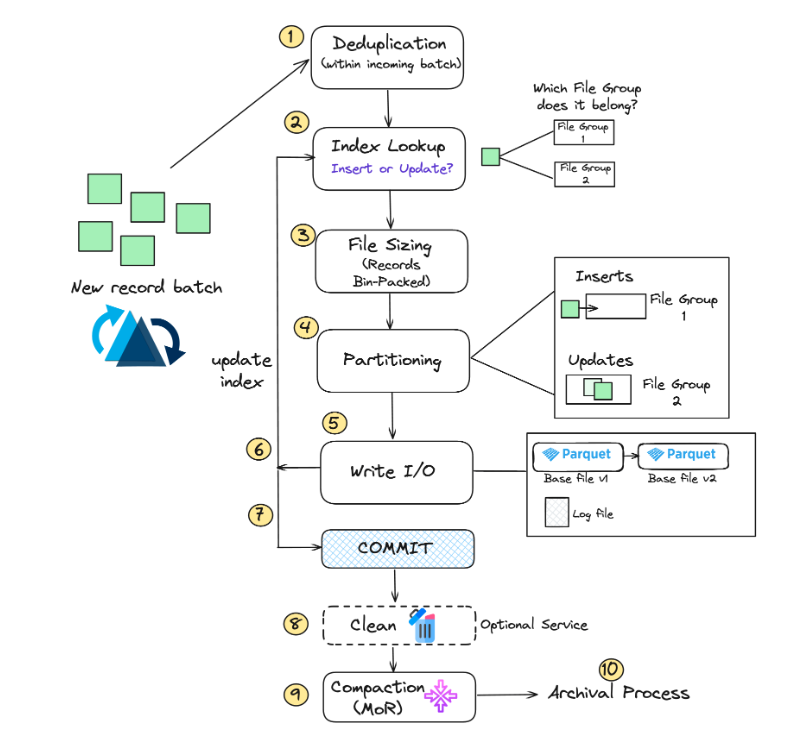
🚀 [New Blog] Performing append-only write operations is quite easy in #ApacheHudi!
Since v0.14 (2023-09), you don’t need to set a record key field to start writing to Hudi tables. Auto key generation lowers the barrier for getting started with a data lakehouse—perfect for append-only writes.
Check out the deep dive blog by Hudi PMC member @_xushiyan on the design: https://t.co/AJyzbNucql
#DataEngineering #DataLakehouse #OpenSource
Supplementing Onehousehq’s Open Engines feature (https://t.co/Yt4JvFiTFv), I had the opportunity to write a deep-dive style blog (https://t.co/SJziAu8Gyp) comparing popular streaming engines like Apache Flink, Spark’s Structured Streaming and Kafka Streams. #dataeng#streaming
Supplementing Onehousehq’s Open Engines feature (https://t.co/Yt4JvFiTFv), I had the opportunity to write a deep-dive style blog (https://t.co/SJziAu8Gyp) comparing popular streaming engines like Apache Flink, Spark’s Structured Streaming and Kafka Streams. #dataeng#streaming
🚨 Announcing Open Engines™, a quick + reliable way to deploy @trinodb, @raydistributed, and @ApacheFlink making it easy to choose the right engine for analytics, streaming, or ML/DS.
Read the details👉
https://t.co/Gvg7J95NYR
🥦 SQL Server CDC makes it possible to keep analytics fresh and up-to-date. But you have to hook up the change stream to your analytics data store to keep it current.
✅ ✅✅ You also need a streaming platform to deliver the news, and a flexible data store. Kafka? Check. Onehouse? Double-check.
🤓 Our new solution guide shows you how to do just that. Check it out!
#onehouse #dataengineering #nolockin
#datalakehouse #opensource
https://t.co/VbMqjzWGl2
Have you been keeping up with Hudi docs lately? Esp. in the past few months the team made some great strides. If you are looking at your spark UI for Hudi writes and wondering, "wait, what's going on?"
Here's what's going on: https://t.co/oYmBiBUtUS
☝️ What if you could use the catalog(s) and query engine(s) of your choice, against a single source of truth?
🐎 In this blog post, Po Hong shows you how to make that vision real.
😃 And see our cool infographic for a few useful data architecture principles.
https://t.co/XgdyjlAEBA
#onehouse #dataengineering #nolockin
#universaldatalakehouse #apachextable #opensource
🏇 You can mix and match data lakehouse table formats and query engines for best performance.
🧱 In one case, Hudi drove Databricks query execution time from 1 minute to 4 seconds.
⚒️ Find out how in this technical deep dive from Sagar Lakshmipathy of Onehouse.
https://t.co/4KuXobRiMj
#onehouse #dataengineering #nolockin
#universaldatalakehouse #apachehudi
#apachextable #opensource
























![apachehudi's tweet photo. 🚀 [New Blog] Performing append-only write operations is quite easy in #ApacheHudi!
Since v0.14 (2023-09), you don’t need to set a record key field to start writing to Hudi tables. Auto key generation lowers the barrier for getting started with a data lakehouse—perfect for append-only writes.
Check out the deep dive blog by Hudi PMC member @_xushiyan on the design: https://t.co/AJyzbNucql
#DataEngineering #DataLakehouse #OpenSource](https://pbs.twimg.com/media/G1FKwIWWwAId6KV.jpg)