Why it matters: reproducibility audits are slow and manual. An agent that surfaces likely blockers just from reading could triage papers at scale — before anyone burns hours on a setup that was never going to work.
Paper: https://t.co/evqcd4hR9Y
Code: https://t.co/KweooozZ52
Huge thanks to amazing @qiuhongannawei, Jingwu, @valeriechen_, Nihar, @Tim_Dettmers, Yiming, @atalwalkar!
Can an AI agent surface why an ML paper might be hard to reproduce — just by reading it, without running any code?
We build ReproRepo, a framework for auditing reproducibility with agents.
Across 1,149 recent papers, the best agent surfaced a semantically related, human-reported reproducibility blocker for ~90% of them. 🧵👇
Beyond matching human-reported blockers, the agent sometimes surfaces problems no one had flagged.
Example: a NeurIPS 2022 paper whose eval code quietly converts any AUROC below 0.5 to 1 - AUROC — silently flipping wrong-direction scores into good-looking ones. The agent caught it by reading the implementation, not the claims.
Introducing Combinatorial Adjoint Matching (CAM)🚀, a paradigm shift from Reinforcement Learning to Adjoint-Method for unsupervised discrete diffusion models!
Highlight🌟: training signals from
- a single trajectory
- the terminal gradient
No labels, no RL, no dense rewards.
Static benchmarks are dying — they tend to get saturated quickly.
Evaluation and training data should co-evolve with frontier models.
We released BenchEvolver — a framework that automatically evolves saturated problems into harder, verified tasks for evaluating frontier models, which can also serve as useful self-improvement signals for RL.
New work from UC Berkeley @berkeley_ai@BerkeleyRDI@BerkeleySky
Project Page: https://t.co/PL1KpGyd87
Paper: https://t.co/gBQOXrZbAV
Today we’re releasing Toto 2.0: a family of open-weights time series foundation models spanning 4M to 2.5B parameters.
The question we set out to answer was simple (yet previously open): Do time series foundation models get reliably better as they scale?
Our answer: yes! 🧵
Excited to introduce AdaExplore 🚀✨
AdaExplore teaches LLM agents to improve GPU kernel generation by learning from past execution failures (Adapt Stage) and searching over diverse optimization paths (Explore Stage).
With GPT-5-mini as the base model, AdaExplore achieves 3.12×/1.72× speedups on KernelBench Level-2/Level-3 within 100 evaluation steps ⚡ and outperforms existing baselines such as OpenEvolve.
Project Page & Demo: https://t.co/cGoUkg5JnV
Arxiv: https://t.co/CpyvPgFBC8
Code: https://t.co/dZFayAk3EY
More in the thread 👇
@Kyriakos_Pelek We rank runs by their expected reduction in prediction uncertainty on the target (high-cost) region, normalized by cost. So the budget is spent on the most informative pilot runs for accurate extrapolation.
New paper: Spend Less, Fit Better
Fitting scaling laws for LLMs can cost millions💰-but what if you can get the same insights with just ~10% of the budget?
We frame scaling-law fitting as budget-aware experimental design and propose a method to pick the most valuable runs.#LLM
✅ Stronger extrapolation
💸 Massive cost savings
📊 Works across diverse scaling scenarios
Check the amazing work by @PlanarG1: https://t.co/XDp0g3cfVl
#ScalingLaws
I will be presenting EDIT-Bench as an Oral at ICLR on Friday 4/23! Session 4D starts at 3:15 and the talk is at 3:39.
We will also be at poster session 3 in the morning.
See you all there!
Can we turn part of an LLM's weights into long-term memory that continuously absorbs new knowledge?
We took a small step toward this with In-Place Test-Time Training (In-Place TTT) — accepted as an Oral at ICLR 2026 🎉
The key idea: no new modules, optional pretraining. We repurpose the final projection matrix in every MLP block as fast weights. With an NTP-aligned objective and efficient chunk-wise updates, the model adapts on the fly — complementing attention rather than replacing it.
📄 Paper: https://t.co/mtfkbptevk
with amazing @Guhao_Feng@Roger98079446 Kai @GeZhang86038849 Di @HuangRubio
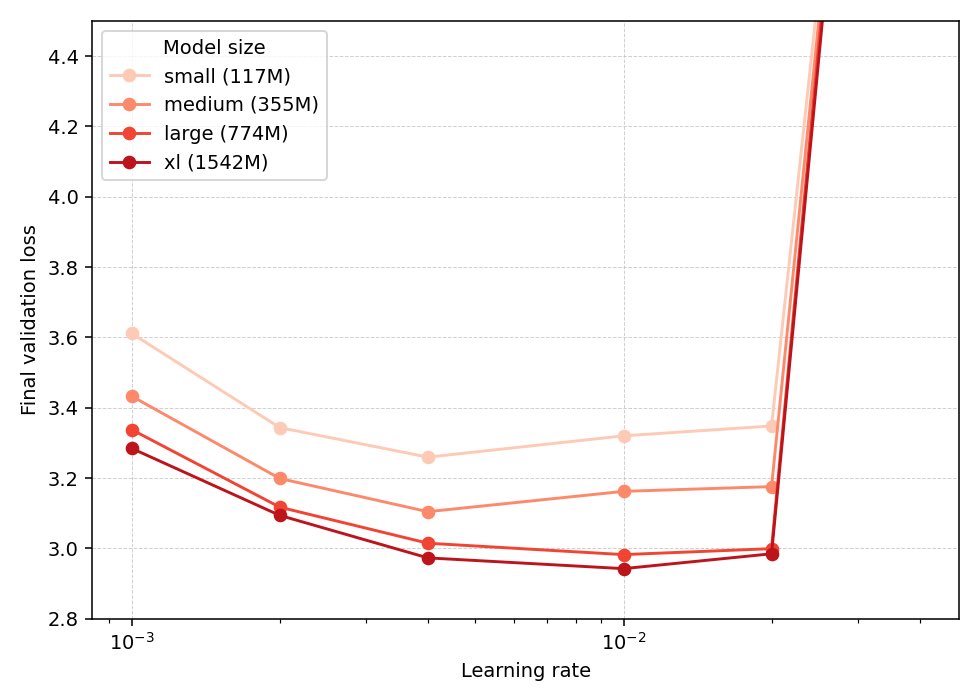
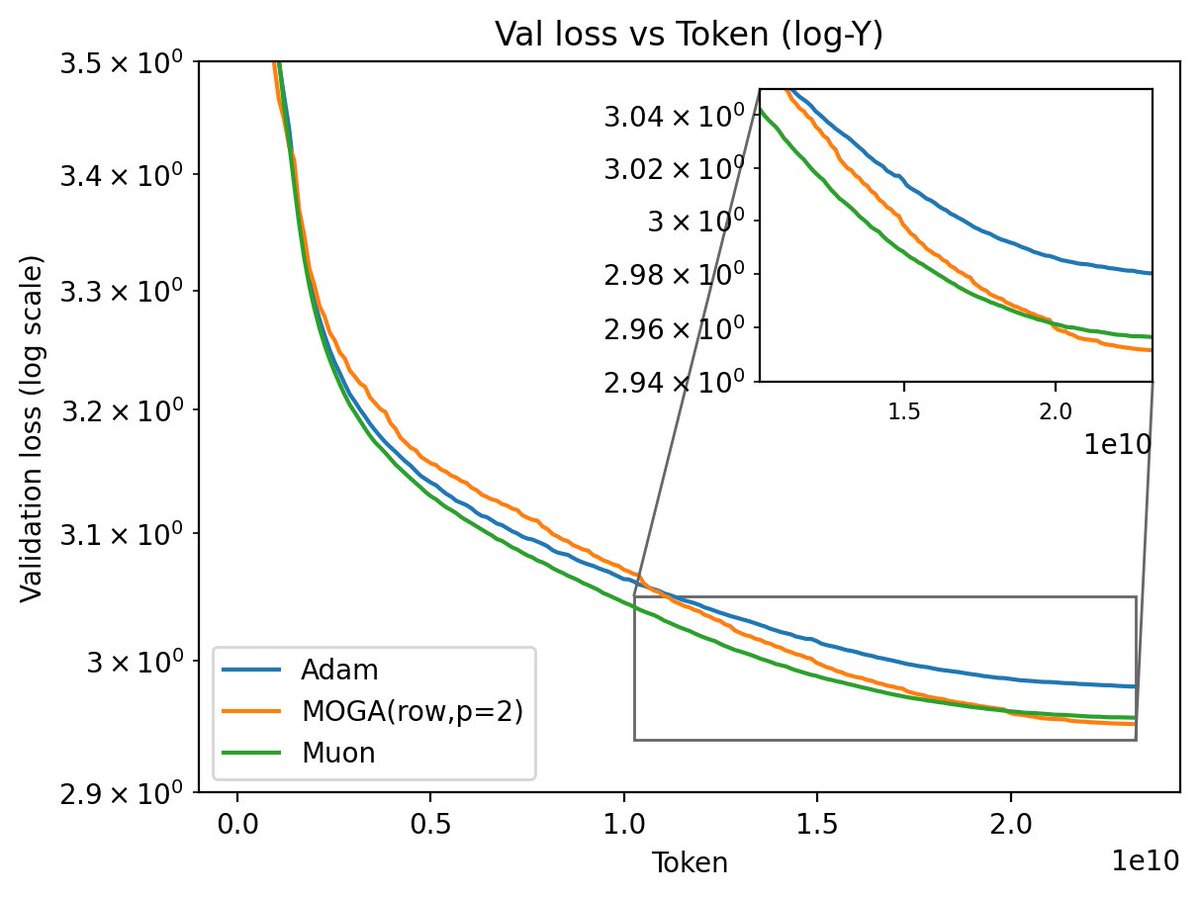
Gradient-Lipschitz analysis can recovers the scaling behind muP!Studying how network width changes the gradient Lip constant under operator norms, we
• recover muP scaling for Adam
• Muon’s smoothness can be bad
• New Row-wise gradient normalization is competitive with Muon
New preprint alert 🚨
Can LLM agents develop video games?
We release GameDevBench, the first benchmark evaluating agentic game development in a game engine, Godot.
We also present two simple multimodal feedback mechanisms that lead to immediate performance gains.
/🧵
We release SERA, the first model part of Ai2’s Open Coding Agent series. SERA is a SoTA agent for its size, super simple, and 26x more efficient than RL.
In my blog post, I write about my personal journey of building this coding agent: https://t.co/kPZHUGwBBC
Details: 👇
Brilliant paper from Stanford + Tsinghua + Peking University + Wizard Quant
Shows an evolution style LLM agent can discover scaling laws that predict performance better than humans.
The big deal is that it turns scaling law writing from slow expert guesswork into an automated search that can guide expensive training and fine tuning decisions.
Scaling laws are simple formulas that guess how an LLM will do as it gets bigger, but experts still craft them by hand and they can fail in new settings.
The authors build SLDBench from 5,000 or more past training runs, and each task asks for 1 formula that predicts well on larger, unseen runs.
They propose SLDAgent, which keeps rewriting both the formula code and the parameter fitting code, testing each new version and keeping the best like an evolution loop.
This helps because the formula and the fitting method depend on each other, so improving only 1 often gives shaky predictions.
Across 8 tasks it beats human formulas on extrapolation, meaning prediction beyond the seen scale, and with GPT-5 its average R2 rises from 0.517 to 0.748.
The payoff is practical because it helps pick learning rate (step size) and batch size (examples per update) with fewer sweeps, and it helps choose which pretrained model to fine tune from small trial runs.