🚨 THE ENTIRE AI BOOM MIGHT BE BUILT ON FAKE REVENUE.
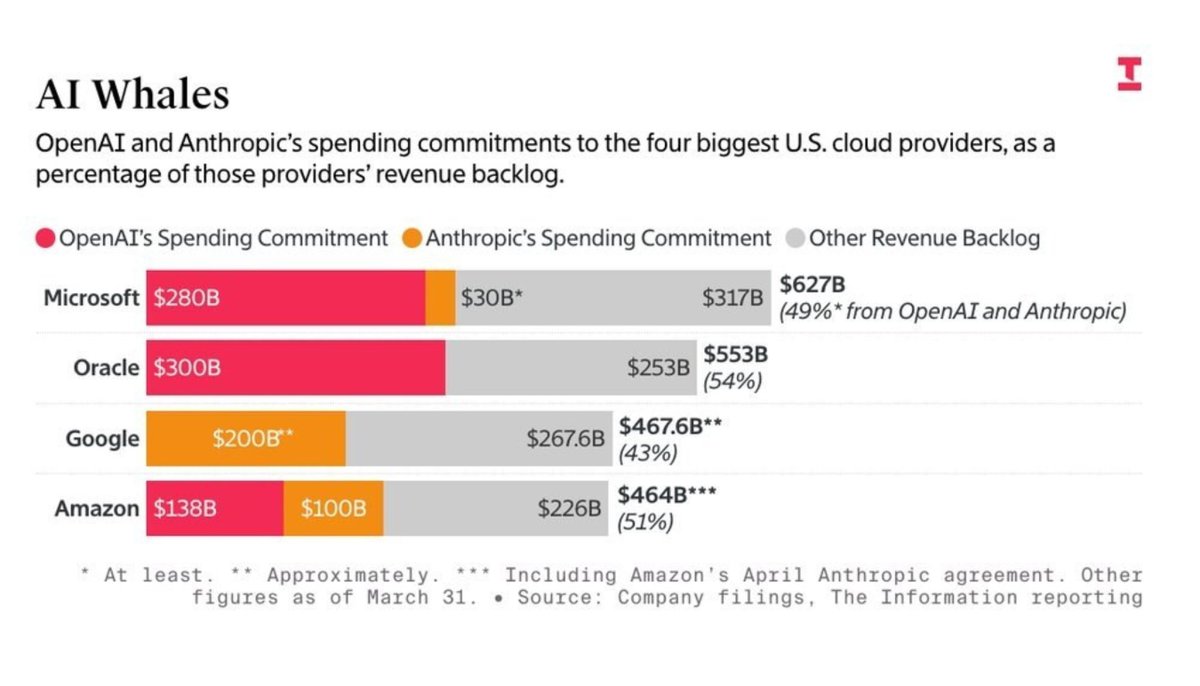
Latest corporate filings show that OpenAI and Anthropic alone make up over half of the entire $2 trillion future cloud backlog held by Microsoft, Oracle, Google, and Amazon.
This massive pipeline is actually being created through a circular accounting trick called a round trip revenue loop.
But how it works ?
A tech giant gives billions of dollars to an AI startup as an "investment". But hidden in the contract is a strict rule forcing the startup to hand that exact same money straight back to the tech giant to rent their computer servers.
Look at the documented case of Microsoft and OpenAI.
When Microsoft invested $13 billion into OpenAI, it didn't just give them cash; it gave them "cloud credits" to use Microsoft servers. OpenAI used those exact credits to train its AI models, and Microsoft then turned around and recorded that server usage as brand new "cloud revenue" from a customer.
The tech giant is literally paying itself with its own money and calling it a sale.
This is why OpenAI’s annual cloud bill has ballooned to over $60 billion, double its actual revenue of $25 billion, kept alive solely by this recycled funding loop.
Anthropic runs the exact same play, spending $2.66 billion on Amazon Web Services in just nine months, which was basically 100% of all the money it earned at the time.
This manufactured demand triggers a second accounting trick where tech giants book massive paper profits. Every time a startup gets a higher value from a new funding round, the tech giant updates the value of its investment on its books and counts that unearned paper gain as direct profit.
In Q1 2026, Alphabet reported a record $62.6 billion profit, but $28.7 billion nearly half, was just a paper markup on its Anthropic investment. In the same quarter, Amazon reported $30.3 billion in profit, but $16.8 billion of it was just an Anthropic paper gain.
While Amazon reported record profits, its actual free cash flow collapsed 95% to just $1.2 billion because it had to spend $44.2 billion in real cash to build physical data centers.
This has created a massive danger where these giant companies rely heavily on just one or two unstable startups. Microsoft has 49% of its $627 billion future backlog tied to OpenAI, while Oracle has an incredible 54% of its entire $553 billion pipeline relying on OpenAI alone.
This perfectly mirrors the 2001 dot-com crash when Global Crossing and Qwest Communications swapped identical fiber-optic network capacity with each other just to book fake sales.
Qwest had to erase $1.4 billion in fake income, and Global Crossing went completely bankrupt.
The only difference is that the dot-com swaps were illegal, but today's AI loop is fully legal under current accounting rules.
This legal loop inflates tech company stock prices, forcing automatic retirement accounts and index funds to buy even more of these tech stocks. It is a self feeding loop where investments, sales, and stock prices all go up on paper without the AI technology ever making real cash profits.
Andrej Karpathy spent 4 minutes in an interview explaining a single idea
about how most people haven’t even started learning how to use AI
and everyone paying $20/month for a subscription.. that's not really using Claude at all
his point is that the real skill gap is the ability to build with AI
he identified 4 behaviors that break Claude Code and put them all into one file
a developer expanded it into 21 rules and published it - 82,000 stars and #1 on GitHub Trending
coding accuracy jumped from 65% to 94%
here's what these 21 rules actually are and why most developers using Claude every day have never configured them
the full breakdown is covered in the article below 👇
Spotify's Chief Architect just showed how they ship 4,5K deployments /day with Claude at Anthropic stage
27-minutes. free. By #1 music app dev
"More than 99% of our engineers use AI coding tools. Adoption took off after Opus 4.5"
Worth more than any $500 vibe-coding course.
AI has stopped being a feature and started being the foundation.
We're excited about a new wave of startups rebuilding software, services, and silicon— and pushing AI into the physical world.
https://t.co/QCIz6DnQnN
i went to https://t.co/0yaHjrptb3. opened the page source. found a hardcoded API key in the javascript. copied it. sent one GET request.
got back 959 email addresses and 3,165 internal feature flags.
employees from Home Depot. Fortinet. Autodesk. Tenable. Rakuten. Mayo Clinic. Permira. Akin Gump. government workers from Wyoming, Arkansas, North Carolina, Montana, Queensland Australia, and New Zealand. a Microsoft contractor. 71 clickup employees.
fortinet sells enterprise firewalls. tenable makes Nessus, the vulnerability scanner half the industry runs. their employees emails are exposed because clickup hardcoded a third party API key in a javascript file that loads before you even log in.
this was first reported to clickup through hackerone on January 17, 2025. its now April 2026. the key has not been rotated. i just pulled the response five minutes ago. every email is still there.
clickup raised $535 million at a $4 billion valuation. claims 85% of the Fortune 500 use their platform. looks like the proof is in the page source.
🚨 BREAKING: Someone just open-sourced software that sees you through walls using only WIFI signals.
it’s called WiFi-DensePose. It maps your exact body pose in real-time. no cameras. no sensors. just your living room router.
100% Open Source.
BREAKING: MIT just mass released their Al library for free. (Links included)
I went through these and honestly... this is better than most paid courses I've seen.
Here's the full list of books:
Foundations
1. Foundations of Machine Learning Core algorithms explained. Theory meets practice.
2. Understanding Deep Learning Neural networks demystified. Visual explanations included.
3. Machine Learning Systems Production-ready architecture. System design principles.
Advanced Techniques
4. Algorithms for ML Computational thinking simplified. Decision-making frameworks.
5. Deep Learning The definitive textbook. Covers everything deeply.
Reinforcement Learning
6. RL Basics (Sutton & Barto) The classic. Agent training fundamentals.
7. Distributional RL Beyond expected rewards. Advanced theory.
8. Multi-Agent Systems Agents working together. Coordination and competition.
9. Long Game Al Strategic agent design. Future-focused thinking.
Ethics & Probability
10. Fairness in ML Bias detection. Responsible Al practices.
11. Probabilistic ML (Part 1 & 2)
Links: https://t.co/AhDqm9x1QC
Most people pay thousands for bootcamps that teach half of this.
Bookmark it. Start anywhere. Just start.
Repost for others Follow for more insights on Al Agents.
MIT's books on Al
Foundations
1. Foundations of Machine Learning - https://t.co/HxbXfsDIl6
2. Understanding Deep Learning - https://t.co/AyeQav2yzN
3. Machine Learning Systems - https://t.co/0AxGtjBFwA
Advanced Techniques
4. Algorithms for ML - https://t.co/LOjFeK1hut
5. Deep Learning - https://t.co/Ztmu7X6gNM
Reinforcement Learning
6. RL Basics (Sutton & Barto) - https://t.co/HAWxL28df1
7. Distributional RL - https://t.co/VB1zBuSzag
8. Multi-Agent Systems - https://t.co/3tWqJaimYn
9. Long Game Al - https://t.co/vYDuy1XKT2
Ethics & Probability
10. Fairness in ML - https://t.co/B4lAj2ivpF
11. Probabilistic ML (Part 1) - https://t.co/folJrX24sf
12. Probabilistic ML (Part 2) - https://t.co/BMOjc8qSqZ
If you are struggling to keep up with the fast moving AI industry,
here is the shortest roadmap that does the bare minimum in 2 weeks and actually works.
No hype. No rabbit holes. Just enough to stop feeling lost.
Week 1. Build the mental map
Day 1. What AI actually is today
AI today = Large Language Models + tools around them.
Understand what an LLM is and why transformers matter.
https://t.co/lehoO8UMm3
https://t.co/1qyNoW2X8Q
Day 2. How models are trained
Only learn the pipeline.
Data → pretraining → fine tuning → inference.
Ignore math. Focus on cost and scale.
https://t.co/WfHSwrS9xT
Day 3. The big model families
Know who builds what and why people choose them.
GPT, Claude, Gemini, LLaMA, Mistral.
https://t.co/EZKBifZB9d
Day 4. Prompting that actually matters
Forget fancy prompts. Learn only this.
Context. Constraints. Examples.
https://t.co/mno8aO5iax
Day 5. Tools and agents
Understand function calling and agent loops.
Most agents are just prompts plus retries.
https://t.co/zvvUiCcW4S
https://t.co/iVpOVf8Dli
⸻
Week 2. Become practically dangerous
Day 6. APIs at a high level
Know what an API call looks like, what tokens cost, and why latency matters.
https://t.co/zikyBUahpk
https://t.co/Z0r1W5rkiT
Day 7. Retrieval Augmented Generation
LLMs + your data ≠ training.
Understand embeddings and vector search.
https://t.co/myoirwfe65
Day 8. Local vs hosted models
Learn when people say run locally, on device, or edge AI.
https://t.co/sYdzVTyir2
Day 9. What breaks in production
This is where real engineers live.
Hallucinations, cost explosions, latency spikes.
https://t.co/LSK8dz0kiM
Day 10. The AI product layer
AI features are not AI products.
Most startups die here.
https://t.co/WyJ9l2uKg7
Day 11. Job impact
Ignore doomsday takes. Look at workflow changes.
https://t.co/jywxWOsgv6
Day 12. Read one serious blog
Pick one and go deep.
https://t.co/CXwl5e6osg
https://t.co/AphoXogFoU
https://t.co/nKp8wPpo6q
Day 13. Build one tiny thing
A prompt workflow, internal tool, or small automation.
Building collapses confusion.
https://t.co/djTOOPYCkY
Day 14. Synthesize
Write one page.
What AI does well.
What it fails at.
Where cost and latency show up.
Where you personally can use it.
⸻
You do not need to chase every model release.
You need a stable mental model and light hands on exposure.
Two weeks of this puts you ahead of most people posting about AI.
Save this. Bookmark it. Come back to it.
Japan has successfully tested a system that generates electricity in space and transmits it wirelessly back to Earth. Solar panels placed in orbit collected energy and sent it to a ground station using microwave transmission.
Once received on Earth, the microwave energy was converted back into usable electricity. This demonstrates that power can be harvested beyond the planet and delivered without physical cables or fuel transport.
Unlike ground-based solar power, space-based systems can collect energy continuously without weather, clouds, or night cycles. This makes the concept especially attractive for stable, large-scale renewable energy production.
The test represents an early but critical step toward future space-based solar farms. Engineers believe much larger arrays could eventually provide clean power to cities or remote regions.
Experts see this as a potential shift in how humanity produces energy, blending space technology with climate-focused solutions. While still experimental, the success confirms the concept is technically feasible.
via Paul Koti, LinkedIn
Microservices is the software industry’s most successful confidence scam. It convinces small teams that they are “thinking big” while systematically destroying their ability to move at all. It flatters ambition by weaponizing insecurity: if you’re not running a constellation of services, are you even a real company? Never mind that this architecture was invented to cope with organizational dysfunction at planetary scale. Now it’s being prescribed to teams that still share a Slack channel and a lunch table.
Small teams run on shared context. That is their superpower. Everyone can reason end-to-end. Everyone can change anything. Microservices vaporize that advantage on contact. They replace shared understanding with distributed ignorance. No one owns the whole anymore. Everyone owns a shard. The system becomes something that merely happens to the team, rather than something the team actively understands. This isn’t sophistication. It’s abdication.
Then comes the operational farce. Each service demands its own pipeline, secrets, alerts, metrics, dashboards, permissions, backups, and rituals of appeasement. You don’t “deploy” anymore—you synchronize a fleet. One bug now requires a multi-service autopsy. A feature release becomes a coordination exercise across artificial borders you invented for no reason. You didn’t simplify your system. You shattered it and called the debris “architecture.”
Microservices also lock incompetence in amber. You are forced to define APIs before you understand your own business. Guesses become contracts. Bad ideas become permanent dependencies. Every early mistake metastasizes through the network. In a monolith, wrong thinking is corrected with a refactor. In microservices, wrong thinking becomes infrastructure. You don’t just regret it—you host it, version it, and monitor it.
The claim that monoliths don’t scale is one of the dumbest lies in modern engineering folklore. What doesn’t scale is chaos. What doesn’t scale is process cosplay. What doesn’t scale is pretending you’re Netflix while shipping a glorified CRUD app. Monoliths scale just fine when teams have discipline, tests, and restraint. But restraint isn’t fashionable, and boring doesn’t make conference talks.
Microservices for small teams is not a technical mistake—it is a philosophical failure. It announces, loudly, that the team does not trust itself to understand its own system. It replaces accountability with protocol and momentum with middleware. You don’t get “future proofing.” You get permanent drag. And by the time you finally earn the scale that might justify this circus, your speed, your clarity, and your product instincts will already be gone.
The notion that AGI would have infinite returns has been used to justify investment far above expected returns (by 10x-100x) for technology that is neither AGI nor on the path to AGI
New breakthrough quantum algorithm published in @Nature today: Our Willow chip has achieved the first-ever verifiable quantum advantage.
Willow ran the algorithm - which we’ve named Quantum Echoes - 13,000x faster than the best classical algorithm on one of the world's fastest supercomputers. This new algorithm can explain interactions between atoms in a molecule using nuclear magnetic resonance, paving a path towards potential future uses in drug discovery and materials science.
And the result is verifiable, meaning its outcome can be repeated by other quantum computers or confirmed by experiments.
This breakthrough is a significant step toward the first real-world application of quantum computing, and we're excited to see where it leads.
If you really want to understand LLMs from scratch, start with n-gram models (unigram, bigram, trigram etc). They’re simple but they teach the core idea, which is predicting the next word from context.
You’ll quickly notice their limits like short memory, data sparsity etc which makes the leap to neural networks and transformers click.
N-grams aren’t required but they are a great stepping stone.
why the private network addresses 192.168.*.*?
because a company used it in some early documentation, people literally copied the same while setting up their networks, and that eventually became the standard.
fascinating.
Breaking: Today we're excited to announce Couchbase Edge Server—a lightweight, offline-first database server and sync solution designed for resource constrained edge environments 🌐
From airplanes to retail stores, #Couchbase Edge Server delivers fast, reliable data access and processing regardless of internet connectivity 🛰️. Learn more: https://t.co/yNXi8VjgQW