Cloudflare just reshaped how AI crawlers get classified — and SEO teams need to pay attention before Sept 15.
On its second "Content Independence Day," Cloudflare moved away from the blunt "block all AI bots" model toward a behaviour-based taxonomy. Instead of asking "is this AI?", the question is now what is the bot doing, what does it store, and how does it reshare your content?
The three use cases every site owner can now control (yes, including the Free tier):
☛ Search: indexing your content to answer queries later; the behavior that drives referral traffic back to you. Allowed by default.
☛ Agent: real-time bots acting on a human's behalf (ChatGPT-User, Gemini/Claude driving Chrome).
☛ Training: crawling to permanently absorb your content into a model.
The change with the biggest SEO implications ☛ new defaults land September 15, 2026.
On pages that display ads, Training and Agent will be blocked by default while Search stays allowed (for new domains onboarding). More importantly: multi-purpose crawlers will now be blocked according to all their behaviors. That means if you block Training, combined crawlers like Googlebot, Applebot, and Bingbot get blocked too — because they crawl for both Search and Training.
You can opt out in Security settings before Sept 15 to protect your search visibility. Don't sleep on this one.
For AI-visibility work:
☛ A new use signal extends Content Signals in robots.txt — use=immediate (store nothing), use=reference (index, excerpt, link back — the new default), or use=full (summarize and reproduce). These are stated preferences, not hard blocks.
☛ Bots that reproduce content in full can't be Verified. Abusing signals costs a bot its Verified status.
☛ "Verified" no longer means "allowed by default" — it now just makes a bot allowable within its category.
Also worth knowing:
☛ BotBase — a new searchable directory (Enterprise Bot Management) showing every tracked bot, its classification, and a copyable detection ID for security rules.
☛ Transitive trust — an experiment using the RFC 7239 Forwarded header (e.g. Forwarded: for="openai";use="reference") so operator-level trust decisions hold even through layers of intermediaries.
The through-line: control is getting granular, and the era of "search and training are the same crawler" is ending. If you manage crawl access, audit your Training rules now so you don't accidentally deindex yourself in September.
When an AI answers about your brand from memory, generative self-retrieval decides whether it recalls you correctly or invents a plausible wrong answer: https://t.co/kM45IKtgmv
S.U.R.R.E.A.L 👇🏽😱👈🏽
Este Post merece MILHÕES DE COMPARTILHAMENTOS..
Exatamente isso, que acontece com quem progride no Brasil 🤔
Nós temos um "Sócio Oculto" q leva quase todo nosso rendimento, e não quer que o povo prospere 😡
POR FAVOR LEIAM E COMPARTILHEM este POST 🫡👈🏽
🔥 New product
I’m building rankd - an app store optimization tool for builders who hate doing aso
The easiest way to:
✅ Track keywords you’re ranking for
✅ Find high potential keywords
✅ Know what to fix (and how)
Waitlist below
ChatGPT is increasingly becoming reliant on product feeds for organic Shopping results, with a ~15X increase this past year.
I came across this great piece of research by @tryprofound related to ChatGPT and their reliance on product feed data over PDPs. The primary takeaway I got from this study relates to how product feed retrieval from feeds has increased by 15X this year to 20%, which is quite a significant increase and shows where the platform is headed.
I primarily use @Semrush for prompt tracking for my eCommerce clients, primarily because I like the output screenshot they provide for reliability and also their expansion of feature tracking lately, where they’re now allowing you to track and see Shopping Ads, for example.
This is combined with my browser @serplens, where I do my day-to-day searches, which are especially useful for showing clients strategies in the wild and allows you to learn about the search results on a deeper level.
So, if I do a search on ChatGPT for a product-related query, you’ll see that the results are heavily geared towards their product cards, which are extracted within my browser, and you’re able to see additional insights around how citations are grouped.
The data that you’re seeing here is what the Profound study relates to, where the increase in product feeds as the data source can be seen within the images, titles, pricing, reviews, and so on.
If we do the same search in AI Mode, you can see a similar breakdown, which makes organic shopping optimisation a bit easier, when we can confidently say that Google is using feeds submitted within GMC Next in order to present their product data, where you can then compare the products that are most frequently appearing.
In most cases, the information submitted within your product feeds mirrors that of the data that appears on your PDP, though the feeds allow the data to be presented in a much more structured way, so it isn’t surprising that ChatGPT is moving in this direction.
Key takeaway: make sure your product feeds are extracting rich data that adds to the experience in order to improve AI Organic Shopping.
Programmatic SEO + scaling to additional countries/languages + YMYL category can be risky. Interesting case here. Tanks in visibility and now is barely indexed. No manual action from what I understand.
There are MAJOR ASO-related changes coming to the App Store in iOS 27.
Every developer gets access to several new media slots:
- banner images
- banner videos
- search results banner
- search results video
These are super important for ASO and ASA. Don't sleep on this!
Get prepared now: https://t.co/DXXCwr7v51
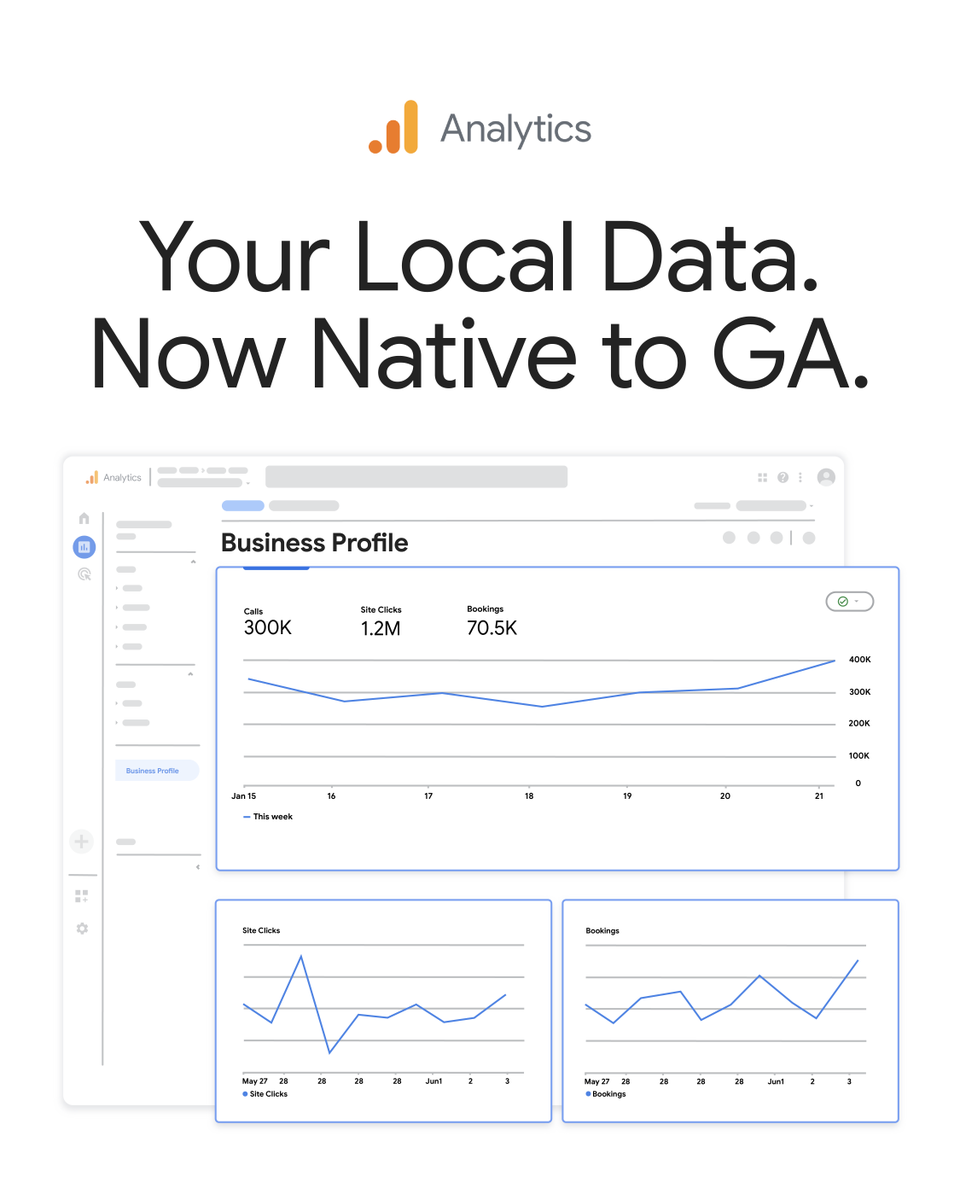
Big news for local businesses📍
You can now link your @GoogleMyBiz Profile directly to Google Analytics 📣
Track local interactions, calls, bookings, & direction clicks right in GA for a complete, cross-channel view of your performance. Stay up to date → https://t.co/bwCGPbhyXg
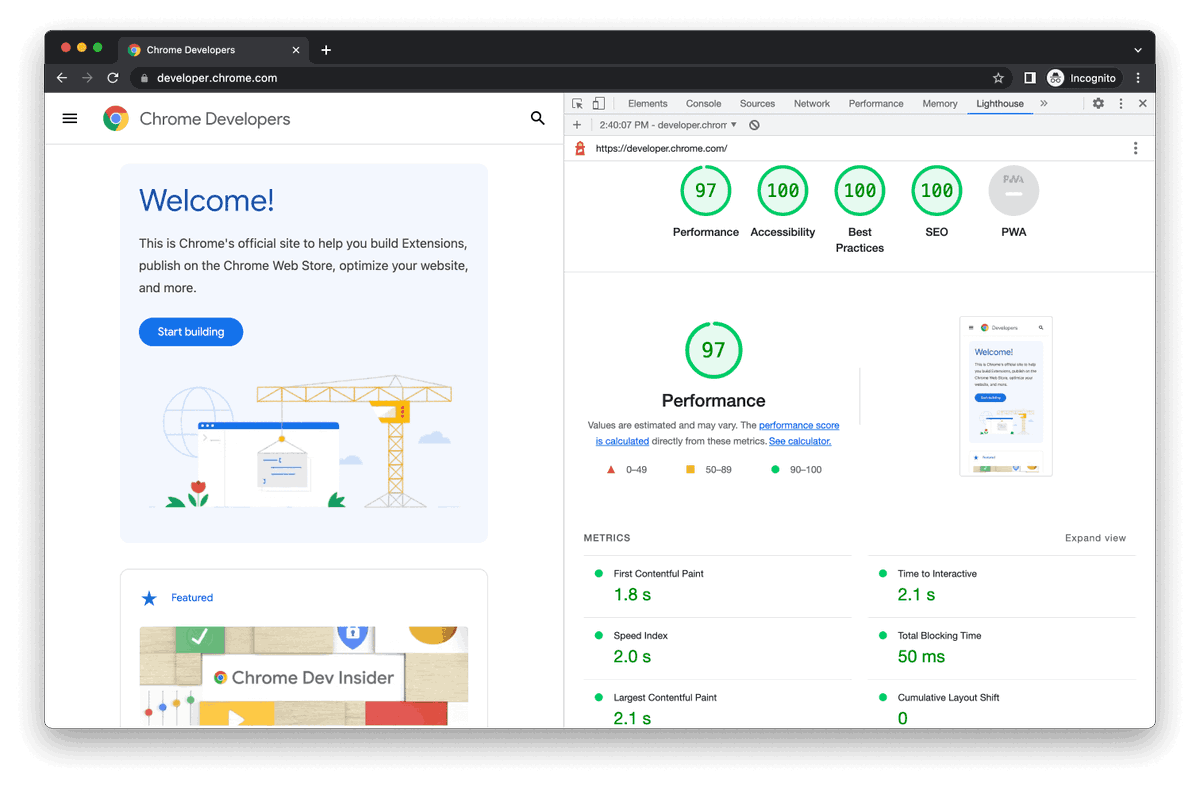
Prepare your site for AI agent interaction with Lighthouse → https://t.co/5myVWdLZd9
If you want AI agents to actually navigate your site properly, the new experimental audit in Lighthouse lets you see:
☀️ Discoverability for AI agents
⚡ WebMCP integration
👀 AI accessibility
#GoogleIO
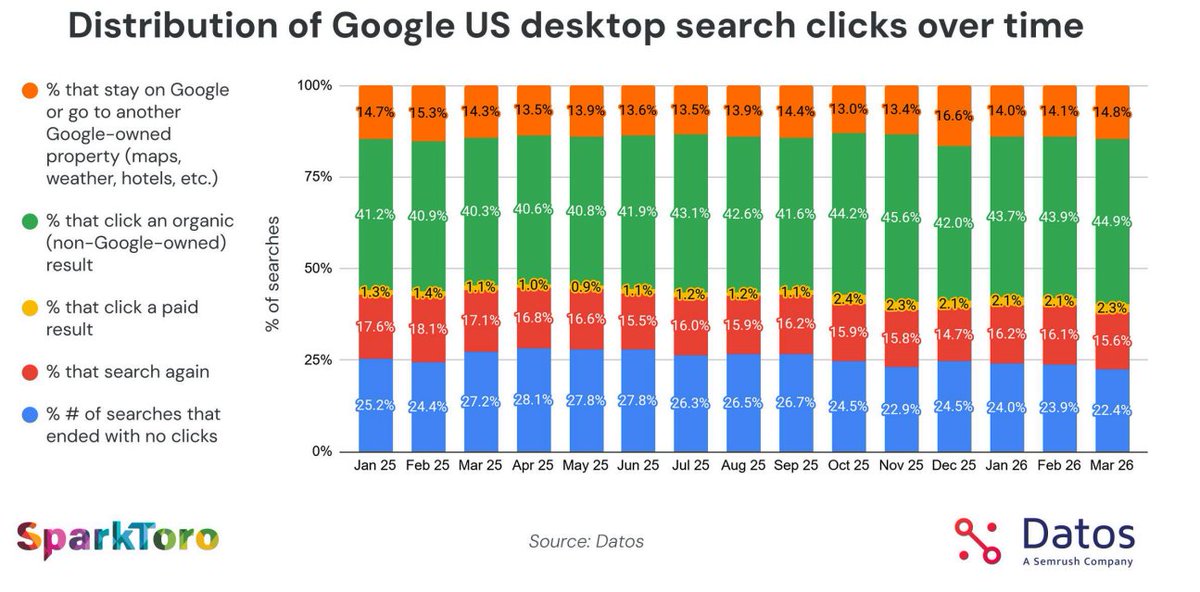
Interesting data from @sparktoro@DatosInsights and @randfish that shows that 0-click searches actually dropped in 3/2026 - paid clicks increased, but organic clicks actually grew to their 2nd highest month in the chart
SEO Tip: with the rollout of UCP (Universal Commerce Protocol), the fundamentals of organic shopping are even more important.
With UCP, free listings can show more prominently in search results, but you need to rank in the first instance to make the most of this new feature.
Going back to the basics, there are several different "titles" for products that are influential for SEO. The title tag, schema title (name), and the product feed title.
While all play their role in some capacity, it is important to understand how each contributes to success in Search and influences product appearance across each data layer.
Learn about the UCP announcements from Google I/O today, where it will be expanding to in the near future, alongside a fundamental tip for "titles" when it comes to organic shopping.
SEO browser used in the video is @serplens