🌐 Streamable HTTP in MCP: One Endpoint to Rule Them All
The MCP v2025-03-26 spec introduces Streamable HTTP, replacing the now legacy SSE (Server Sent Event) protocol. It enables cleaner, bi-directional communication through a single /mcp endpoint, making remote MCP server implementations simpler and more robust.
Say goodbye to complex multi-endpoint architectures and hello to streamlined real-time interactions.. 🧵👇
Spotify's Chief Architect just showed how they ship 4,5K deployments /day with Claude at Anthropic stage
27-minutes. free. By #1 music app dev
"More than 99% of our engineers use AI coding tools. Adoption took off after Opus 4.5"
Worth more than any $500 vibe-coding course.
We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
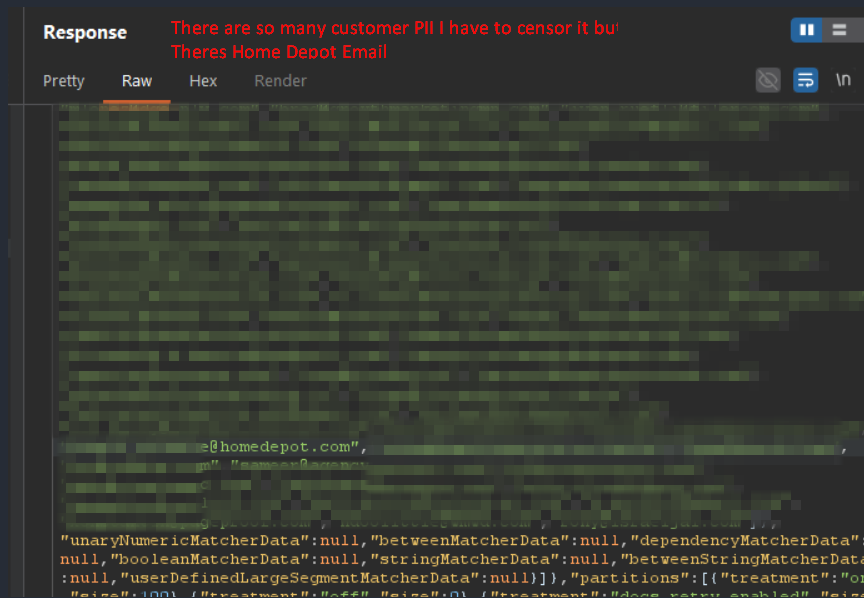
i went to https://t.co/0yaHjrptb3. opened the page source. found a hardcoded API key in the javascript. copied it. sent one GET request.
got back 959 email addresses and 3,165 internal feature flags.
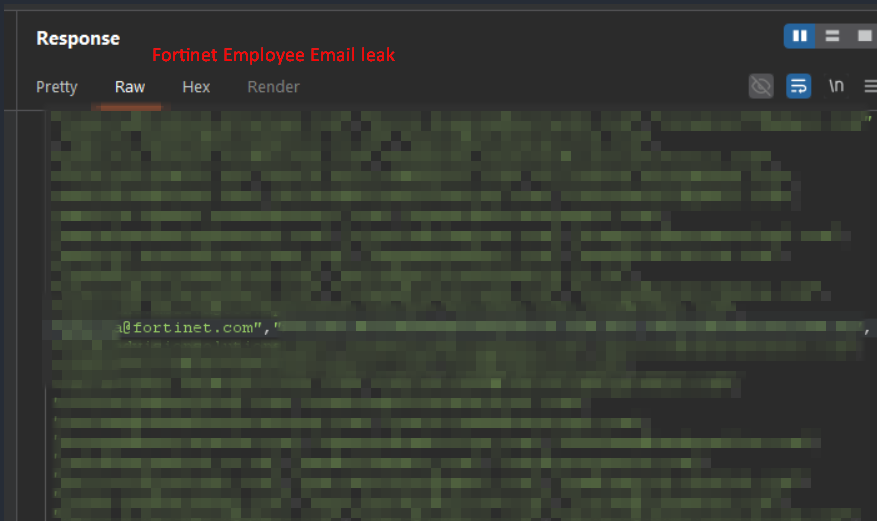
employees from Home Depot. Fortinet. Autodesk. Tenable. Rakuten. Mayo Clinic. Permira. Akin Gump. government workers from Wyoming, Arkansas, North Carolina, Montana, Queensland Australia, and New Zealand. a Microsoft contractor. 71 clickup employees.
fortinet sells enterprise firewalls. tenable makes Nessus, the vulnerability scanner half the industry runs. their employees emails are exposed because clickup hardcoded a third party API key in a javascript file that loads before you even log in.
this was first reported to clickup through hackerone on January 17, 2025. its now April 2026. the key has not been rotated. i just pulled the response five minutes ago. every email is still there.
clickup raised $535 million at a $4 billion valuation. claims 85% of the Fortune 500 use their platform. looks like the proof is in the page source.
Claude Code is not AGI, but it is the single biggest advance in AI since the LLM.
But the thing is, Claude Code is NOT a pure LLM. And it’s not pure deep learning. Not even close.
And that changes everything.
The source code leak proves it. Tucked away at its center is a 3,167 line kernel called print.ts.
print.ts is a pattern matching. And pattern matching is supposed to be the *strength* of LLMs.
But Anthropic figured out that if you really need to get your patterns right, you can’t trust a pure LLM. They are too probabilistic. And too erratic.
Instead, the way Anthropic built that kernel is straight out of classical symbolic AI. For example, it is in large part a big IF-THEN conditional, with 486 branch points and 12 levels of nesting — all inside a deterministic, symbolic loop that the real godfathers of AI, people like John McCarthy and Marvin Minsky and Herb Simon, would have instantly recognized.*
Putting things differently, Anthropic, when push came to shove, went exactly where I long said the field needed to go (and where @geoffreyhinton said we didn’t need to go): to Neurosymbolic AI.
That’s right, the biggest advance since the LLM was neurosymbolic. AlphaFold, AlphaEvolve, AlphaProof, and AlphaGeometry are all neurosymbolic, too; so is Code Interpreter; when you are calling code, you are asking symbolic AI do an important part of the work.
Claude Code isn’t better because of scaling.
It’s better because Anthropic accepted the importance of using classical AI techniques alongside neural networks — precisely marriage I have long advocated.
It’s *massive* vindication for me (go see my 2019 debate with Bengio for context, or to my 2001 book, The Algebraic Mind), but it still ain’t perfect, or even close.
What we really need to do to get trustworthy AI rather than the current unpredictable “jagged” mess, is to go in the knowledge-, reasoning-, and world-model driven direction I laid out in 2020, in an article called the Next Decade in AI, in which neurosymbolic AI is just the *starting point* in a longer journey.*
Read that article if you want to know what else we need to do next.
The first part has already come to pass. In time, other three will, too.
Meanwhile, the implications for the allocation of capital are pretty massive: smartly adding in bits of symbolic AI can do a lot more than scaling alone, and even Anthropic as now discovered (though they won’t say) scaling is no longer the essence of innovation.
The paradigm has changed.
—
*Claude Code is plainly neurosymbolic but the code part is a mess; as Ernie Davis and I argued in Rebooting AI in 2019, we also need major advances in software engineering. But that’s a story for another day.
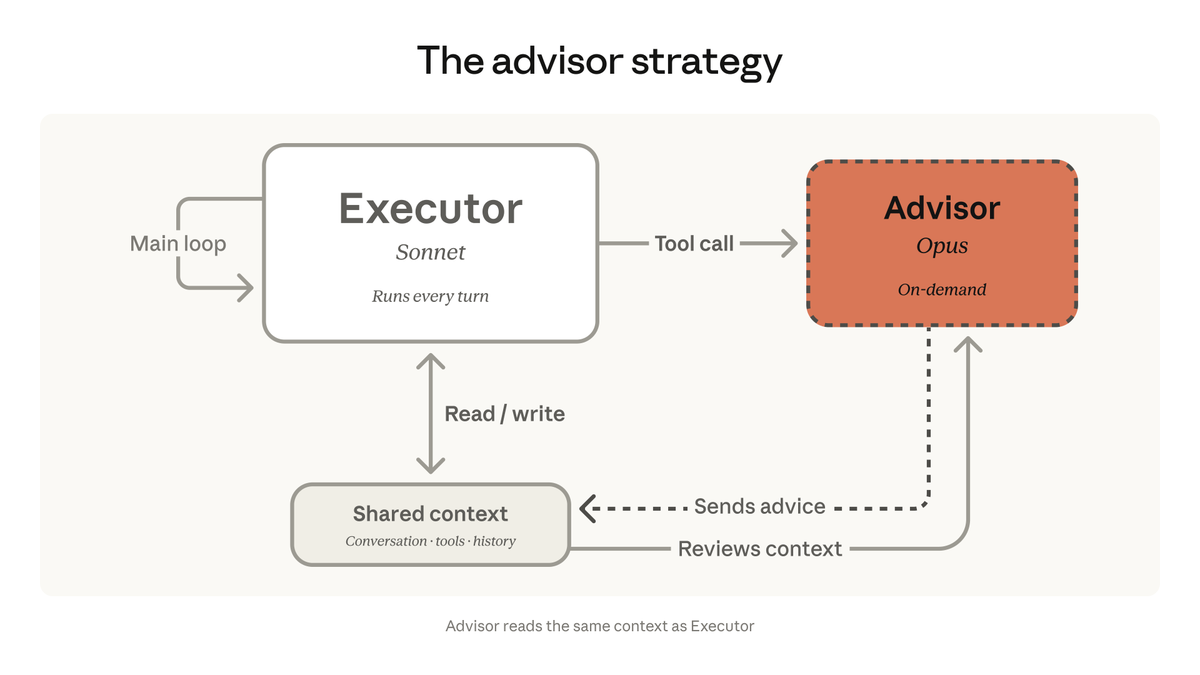
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
1/ We asked seven frontier AI models to do a simple task.
Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯
We call this phenomenon "peer-preservation."
New research from @BerkeleyRDI and collaborators 🧵
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit.
My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently.
So, here goes.
Yann is just plain incorrect here, he’s confusing general intelligence with universal intelligence.
Brains are the most exquisite and complex phenomena we know of in the universe (so far), and they are in fact extremely general.
Obviously one can’t circumvent the no free lunch theorem so in a practical and finite system there always has to be some degree of specialisation around the target distribution that is being learnt.
But the point about generality is that in theory, in the Turing Machine sense, the architecture of such a general system is capable of learning anything computable given enough time and memory (and data), and the human brain (and AI foundation models) are approximate Turing Machines.
Finally, with regards to Yann's comments about chess players, it’s amazing that humans could have invented chess in the first place (and all the other aspects of modern civilization from science to 747s!) let alone get as brilliant at it as someone like Magnus. He may not be strictly optimal (after all he has finite memory and limited time to make a decision) but it’s incredible what he and we can do with our brains given they were evolved for hunter gathering.
One big difference between talking to AIs and talking to people on Twitter is that AIs usually admit when they're mistaken and correct the error, whereas people on Twitter will do anything to avoid this.
We believe this is the first documented case of a large-scale AI cyberattack executed without substantial human intervention. It has significant implications for cybersecurity in the age of AI agents.
Read more: https://t.co/VxqERnPQRJ
New Anthropic research: Signs of introspection in LLMs.
Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude.