So pleased that our paper on empowerment and causal models is out and freely available as part of this impressive special issue on world models and AI, with Melanie Mitchell, Josh Tenenbaum, Tom Griffiths and many other stars.
https://t.co/iQMU5gcmDz
Yann LeCun says that within a year to 18 months, we'll have a general method for training hierarchical world models
These models would learn from video and real-world data, then help plan actions in robotics, healthcare, and other areas
"then scale them toward a universal world model"
Michael Levin and Yann Lecun are making world models a next big thing in AI. Both attended AGI alliance Davos and invited to our next AI Academy UAE week https://t.co/E4eimjGtTg
It is the deepest honor to have been joined by Michael Levin (@drmichaellevin), Victoria Klimaj, Zahra Sheikhbahaee (@zah_bah), Dalton Sakthivadivel (@DaltonSakthi), Adeel Razi (@adeelrazi), David Ha (@hardmaru), Nick Hay, Kevin Schmidt, Irina Rish (@irinarish), David Krakauer (@sfiscience), Melanie Mitchell (@MelMitchell1), Samuel Gershman (@gershbrain), and Joshua Tenenbaum in organizing this special issue of the Royal Society’s (@RSocPublishing) Philosophical Transactions A:
“World models, A(G)I, and the Hard problems of life-mind continuity: Toward a unified understanding of natural and artificial intelligence”
https://t.co/XMYB2SAofX
This collection was motivated by a question with far reaching implications, ranging from the fundamental nature(s) of mind to choices that may determine the future of our civilization/species: what kinds of world modeling capabilities are likely to be realized by which kinds of minds and what world might we be in with respect to increasingly advanced artificial intelligences?
Will the scaling and refinement of present approaches result in AI with human-like (and beyond) cognitive abilities, or do we need radically different paradigms that more closely follow the principles of natural intelligence? Learning “world models” to predict/compress information may be how biological learners so efficiently learn (to learn) to achieve goals and generalize that knowledge across a broad range of task environments. World models may also be useful for reverse-engineering forms of “System 2” cognition, or the self-reflexive, deliberate, multi-step reasoning associated with cognitive capabilities that may be unique to humans. Predictive models that reflect how the world may be causally modified by actions allow agents to adaptively control their behavior with flexibility and context-sensitivity. Spatiotemporally and causally coherent models of the physical world may not only be the key for creating AIs that we can rely on for real-world deployment, but may even be the (dynamic) core of conscious cognition.
The contributions to this special issue consider the varieties of world models worth modeling from diverse points of view:
Douglas Hofstadter explores whether sufficiently coherent self-referential world modeling could ground meaning, consciousness, and a genuine “I” in future AI systems.
David Krakauer (@sfiscience), Melanie Mitchell (@MelMitchell1), and John Krakauer (@blamlab) examine the principles of emergent intelligence from a complex systems perspective.
Alexander Ku (@alex_y_ku), Declan Campbell, Xuechunzi Bai (@baixuechunzi), Jiayi Geng (@JiayiiGeng), Ryan Liu (@theryanliu), Raja Marjieh (@RajaMarjieh), R. Thomas McCoy (@RTomMcCoy), Andrew Nam, Ilia Sucholutsky (@sucholutsky), Liyi Zhang (@LiyiZhang_Leo), Jian-Qiao Zhu (@JQ_Zhu), and Thomas Griffiths (@cocosci_lab) argue for using the tools of cognitive science to understand and evaluate LLMs across multiple levels of analysis.
Evelina Leivada (@EvelinaLeivada), Gary Marcus (@GaryMarcus), Fritz Günther, and Elliot Murphy (@ElliotMurphy91) test whether LLMs deeply understand language and the “world behind words,” or primarily learn surface statistical regularities.
Pedro Tsividis (@ptsividis), João Loula, Jake Burga, Juan Pablo Rodriguez, Sergio Arnaud, Nate Foss (@_npfoss), Andres Campero, Ajay Subramanian (@ajaysub110), Thomas Pouncy, Samuel Gershman (@gershbrain), and Joshua Tenenbaum introduce a theory-based meta-learning architecture inspired by the remarkable flexibility and efficiency of human cognition.
Eunice Yiu (@eunice_yiu_), Kelsey Allen, Shiry Ginosar (@shiryginosar), and Alison Gopnik (@AlisonGopnik) explore empowerment, controllability, and causal reasoning as means of understanding the remarkable learning abilities of both child and adult minds.
Nadav Amir, Stas Tiomkin, and Angela Langdon investigate how goals shape the structure of experience and how the world modeling abilities of natural intelligences may be inseparable from values.
Vickram Premakumar, Michael Vaiana, Florin Pop (@FlorinPop17), Judd Rosenblatt (@juddrosenblatt), Diogo Schwerz de Lucena, Kirsten Ziman, and Michael Graziano show unexpected benefits of self-modeling as an inductive bias and regularizer for training artificial agents.
Hanlin Zhu, Baihe Huang, and Stuart Russell analyze why model-based reinforcement learning may fundamentally outperform model-free approaches in representational efficiency.
Bradly Alicea (@balicea1), Morgan Hough (@mhough), Amanda Nelson, and Jesse Parent (@JesParent) revisit fundamental cybernetic principles of regulation, adaptation, and world modeling across a wide assortment of complex adaptive systems.
Francesco Sacco (@FrancescoSacco1), Dalton Sakthivadivel (@DaltonSakthi), and Michael Levin explore topological constraints on self-organization and suggest that biological systems maintain long-range coherence in ways that are fundamentally different from current transformer architectures.
Georg Northoff (@NorthoffL), Yasir Catal, and Samira Abbasi examine how biological intelligence may depend on capabilities for flexible “inner time” to ensure adaptive alignment between the dynamics of system and world.
Nicolas Rouleau (@DrNRouleau) and Michael Levin explore whether theories of consciousness generalize beyond brains to unconventional embodiments and living systems more broadly.
Benjamin Lyons and Michael Levin investigate economies and collective intelligence as systems coordinated by “cognitive glues” in the form of shared models of scarcity and value.
Katherine Collins (@katie_m_collins), Umang Bhatt (@umangsbhatt), and Ilia Sucholutsky (@sucholutsky) consider “Rogers’ paradox” to demonstrate ways in which collective learning is impacted by different kinds of human-AI interactions.
Ruairidh Battleday (@RMBattleday) and Samuel Gershman (@gershbrain) distinguish between the “easy” and “hard” problems of science, and describe how while current AI systems demonstrate powerful narrow forms of optimization with respect to well-defined inference-spaces, further developments are needed for achieving capabilities for novel scientific discovery.
Fritz Breithaupt (@FritzBreithaupt) explores narrative world models and the roles of uncertainty and transformative experiences in natural intelligences, suggesting that coherent agency may depend on better understanding human-like meaning-making.
Taken together, these diverse perspectives suggest that while LLMs can clearly learn powerful generative models of language, they likely do so without having world models of sufficient spatiotemporal and causal coherence to achieve human-like reasoning abilities, capacities for generating subjective conscious experiences, or pathways to realizing artificial general superintelligence. However, by further developing world modeling architectures, we may eventually be able to create forms of intelligence that recapitulate the remarkable flexibility and generality of human intelligence. Finally, enhanced (e.g. more coherent/integrated) world models may not only afford expanded capabilities, but could potentially help ensure that increasingly powerful AI systems achieve both inner and outer alignment with human(e) values.
"You’re not talking to someone who woke up a loser” - Jensen Huang
Jensen nearly lost his composure during a heated debate about selling chips to China, despite showing tremendous patience in response to the pushback.
Binary AI skills building.
self-improvement (RSI).
Almost every lab now uses previous-generation models to build the next one. It's not fully automated yet
"what's missing is long-horizon planning and full automation"
Same, I have a similar setup. A mix of Obsidian, Cursor (for md), and vibe-coded web terminals as front-end.
Since I do a podcast, the number/diversity of research interests is very large. But the knowledge-base approach has been working great.
For answers, I often have it generate dynamic html (with js) that allows me to sort/filter data and to tinker with visualizations interactively.
Another useful thing is I have the system generate a temporary focused mini-knowledge-base for a particular topic that I then load into an LLM for voice-mode interaction on a long 7-10 mile run. So it becomes an interactive podcast while I run, where I ask it questions and listen to the answers to learn more.
Anyway, heading out for a run now, thanks for the write-up 👊
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
New #preprint: @BeneHartl@LPiolopez
https://t.co/3yrxPGIKAw
"BraiNCA: brain-inspired neural cellular automata and applications to morphogenesis and motor control"
Abstract:
Most of the Neural Cellular Automata (NCAs) defined in the literature have a common theme: they are based on regular grids with a Moore neighborhood (one-hop neighbour). They do not take into account long-range connections and more complex topologies as we can find in the brain. In this paper, we introduce BraiNCA, a brain-inspired NCA with an attention layer, long-range connections and complex topology. BraiNCAs shows better results in terms of robustness and speed of learning on the two tasks compared to Vanilla NCAs establishing that incorporating attention-based message selection together with explicit long-range edges can yield more sample-efficient and damage-tolerant self-organization than purely local, grid-based update rules. These results support the hypothesis that, for tasks requiring distributed coordination over extended spatial and temporal scales, the choice of interaction topology and the ability to dynamically route information will impact the robustness and speed of learning of an NCA. More broadly, BraiNCA provides brain-inspired NCA formulation that preserves the decentralized local update principle while better reflecting non-local connectivity patterns, making it a promising substrate for studying collective computation under biologically-realistic network structure and evolving cognitive substrates.
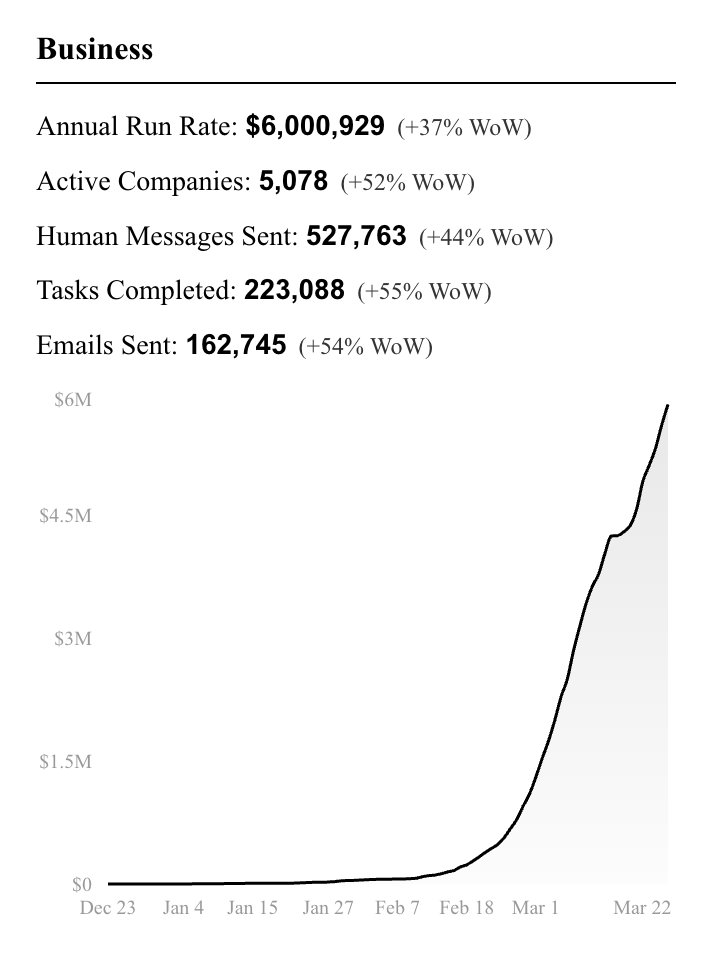
$6M run rate. $3M->$6M in 2 weeks. One Founder + AI agents. Zero employees.
I wanted to create a platform with the vibes of the 1990s, the vibes of the 2000s, of the 2010s, and then have a feature of the future
And I said, "Wait a second, I know the Agent SDK
Why don't I use the Agent SDK which is the feature of the future?"
And I didn't have any idea what to do, but I knew I needed agents, so I put agents in loops and connected MCPs, which then were synced to real products running in production
I knew that could be a feature of the future but I didn't realize how much the impact would be