Today, among the goods that are universally intended for everyone, we must also include new forms of property, such as patents, algorithms, digital platforms, technological infrastructure and data. In a context where the wealth of nations depends increasingly on knowledge and technology, when these goods remain concentrated in the hands of a few, without adequate forms of sharing and access, a new imbalance is created that contradicts the universal destination of goods. In turn, it widens the gap between the included and the excluded, between those who can participate in the digital revolution and those who remain on the margins. #MagnificaHumanitas
🚨 CEO Anthropic Dario Amodei właśnie dostał nokaut na oczach całego świata.
Chiński founder Moonshot AI Yang Zhilin wziął i wrzucił za darmo całą rewolucyjną architekturę Kimi Agent Swarm.
Rój ponad 100 agentów działających równolegle. 1500 wywołań narzędzi jednocześnie.
Zadania, które Claude 4.5 i GPT-5.2 robią w godzinę, Kimi załatwia w 15 minut.
40-minutowy masterclass na NVIDIA GTC, w którym Yang tłumaczy wszystko krok po kroku:
• Orchestrator + parallel reinforcement learning
• MoE na bilionach parametrów
• Kimi Linear i 3D-synergia kontekstu
Efekt?
Kimi K2.5 miażdży Zachód w kluczowych benchmarkach agentycznych (HLE-Full, MathVista, OCRBench, multimodal) i robi to 4–5× taniej.
Anthropic just paid millions to hire Andrej Karpathy.
He gave you the same knowledge for $0 the same week.
Co-founder of OpenAI. Former head of AI at Tesla. The man who coined vibe coding.
No recruitment fee. No exclusive access. Just a link and 29 minutes.
LLMs are ghosts not animals.
Vibe coding is dead.
Software 3.0 is here.
Watch it.
Then read this.
Because Karpathy tells you what Software 3.0 is.
This shows you how to build one - a software factory with Claude Code that ships features while you sleep.
The full build guide is below.
Este repositorio es una joya. Te da todos los pasos e instrucciones para proteger y asegurar tu servidor Linux.
Perfecto por si tienes un servidor propio o VPS:
https://t.co/yJD2GnXFPj
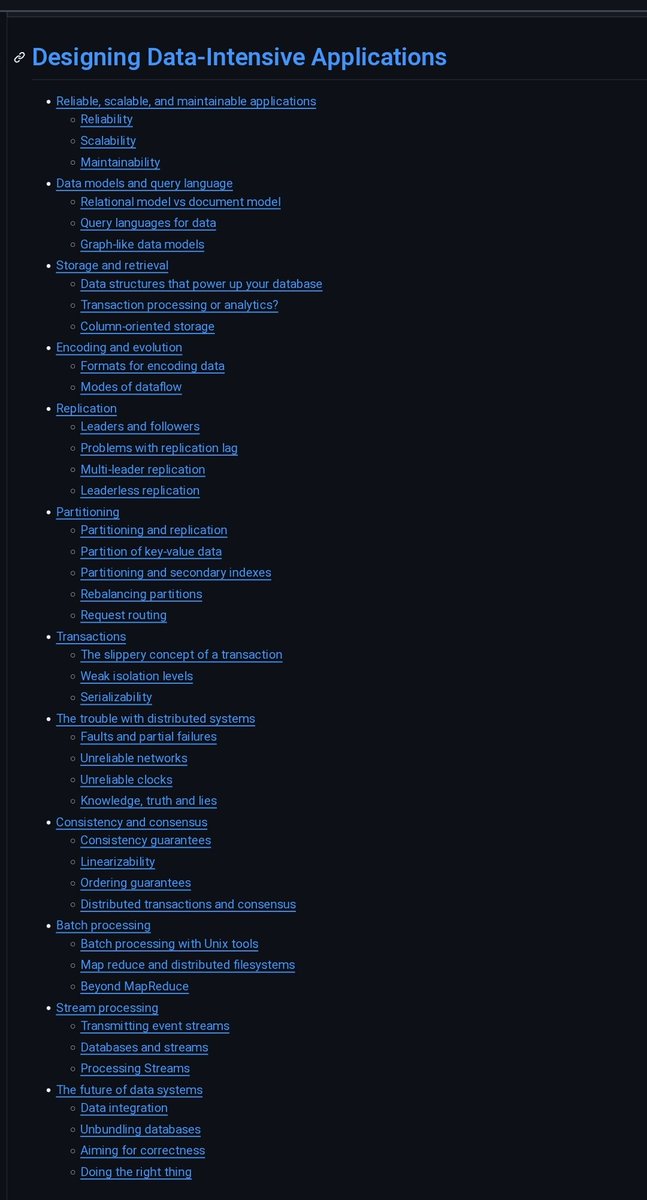
DDIA (Designing Data-Intensive Applications) IS THE BIBLE OF BACKEND ENGINEERING
Martin Kleppmann spent years inside google, linkedin & distributed systems research
then wrote everything down in one book
600 pages of how real systems fail, scale & survive
most people buy it...few finish it
this dev did & turned every chapter into clean github notes
replication & sharding..transactions & consensus...batch vs stream processing...why databases quietly lie to you
the exact knowledge that separates a junior who codes from a senior who architects
one repo no excuses
🔗 https://t.co/9UlMCljPBQ
ANDREJ KARPATHY JUST DROPPED THE MOST IMPORTANT PYTHON FILE FOR ANYONE LEARNING LLMs
He wrote https://t.co/WMajAg17sX a complete GPT from scratch... no libraries... no frameworks... pure python
the entire algorithm fits in one file
the only imports are math, random & os
here's what's inside:
▫️a from-scratch autograd engine (yes, he built backprop by hand).
▫️a full transformer token embeddings, positional embeddings, multi-head attention, MLP, RMSNorm
▫️Adam optimizer implemented from scratch
▫️training loop + inference in under 200 lines
the comment at the top says it all:
"this file is the complete algorithm.
everything else is just efficiency."
and the community went insane 5000+ stars, ports in rust, go, OCaml, julia, CUDA & JS already exist
if you've ever used transformers without really understanding what's happening underneath this is your weekend project
read it once...you'll never look at LLMs the same way
→https://t.co/2MbPGJJeJ1
THIS IS THE ONLY AI ENGINEERING REPO YOU NEED
93+ production-ready projects all in one place
the ai-engineering-hub covers everything
RAG pipelines, AI agents, LLM fine-tuning, MCP integrations, voice bots, multimodal apps
not just theory actual working code you can run, adapt & ship
beginner...? start with a simple RAG or local ChatGPT clone
intermediate..? build agentic workflows with CrewAI and LangGraph
advanced...? fine-tune DeepSeek, build reasoning models, deploy production systems
and it keeps growing new projects drop regularly
if you're trying to break into AI engineering or level up your skills this is where you start and keep coming back
open source...free...no gatekeeping
→ https://t.co/OVBNcq4ppm
These 5 GitHub repos are blowing up this week… and they’re not random drops.
They’re literally the future of AI agents (learning, memory, self-evolution).
Save this list 👇
1. andrej-karpathy-skills
https://t.co/F69sDfLKqD
A single CLAUDE.md that fixes how AI codes
→ based on Karpathy’s insights on LLM mistakes
→ fewer hallucinations, better decisions
→ simple file, massive impact
2. hermes-agent
https://t.co/myr9QKqmCS
An agent that actually learns and evolves
→ builds skills from experience
→ remembers past interactions
→ gets better over time
3. claude-mem
https://t.co/nNvO3H6gEC
Gives Claude real memory
→ records sessions
→ compresses context
→ injects it into future runs
4. evolver
https://t.co/Sjxtt6Wr5M
Self-evolving agent engine
→ uses evolution-style optimization
→ continuously improves strategies
→ built for autonomous systems
5. GenericAgent
https://t.co/wPYh926Xom
Full system-control agent
→ builds its own skill tree
→ high efficiency, low token usage
→ scales complex workflows
Notice the pattern?
Not tools.
Not prompts.
Systems that learn, remember, and improve.
Bookmark this.
Retweet before everyone starts copying this exact stack.
The Local LLM Cheat Sheet for your 32GB RAM device
I was asked to put together a practical lineup of local models that fit comfortably on a 32GB machine.
At this tier, you start getting access to real flagship-class local models, plus a growing number of custom quants. But for most people, these are the core models worth knowing first.
Flagship Models
Qwen3.5 27B / GGUF / Q6_K_M
The best overall 32GB flagship. General chat, writing, research, and agent workflows. Great if you want one model that can handle almost everything well.
Qwen3.6-35B-A3B / GGUF / UD-Q4_K_M
Best MoE flagship. Stronger for coding, reasoning, and tool use than most smaller generalists.
Gemma 4 31B / GGUF / Q6_K_M
Dense premium model. Writing, analysis, reasoning, and high-end local chat. Heavier than the MoE options, but excellent when quality matters more than speed.
Models for Fast Flagship Use
Gemma 4 26B A4B / GGUF / Q6_K_M
Great balance of speed and quality for general assistant work, coding, agent tasks, and research. This is one of the best 32GB picks if you want something that feels high-end without dragging.
DeepSeek-R1 Distill Qwen 32B / GGUF / Q4_K_M
Offline reasoning engine. Best for math, logic, deliberate analysis, and step-by-step problem solving.
Mistral Small 24B / GGUF / Q6_K_M
Tool-calling specialist. Strong for assistants, chat workflows, local business tasks, and function calling. Available for 24GB machines.
Models for Companion Use
Qwen3.5 9B / GGUF / Q6_K_M
Best sidekick. Fast drafts, search loops, cheap retries, and secondary agent work. Even on a 32GB machine, you still want a smaller model around for support tasks.
Llama 3.1 8B / GGUF / Q6_K_M
Long-context companion. RAG, doc ingestion, codebase chat, and long prompts. The output quality is not the sharpest anymore, but it is still useful when needing simple tasks fast.
From what my community tells me, the best single models are Qwen3.5 27B or Gemma 4 31B.
For two models, the strongest general pairing is Qwen3.5 27B + Qwen3.5 9B.
If you are more code-heavy, Qwen3.6-35B-A3B + Llama 3.1 8B.
Let me know what models you are running on 32GB, and which ones have actually been worth the RAM.
The second edition of the Africa AI Policy Opportunities Digest is out with the latest fellowships, events, funding, and courses!
https://t.co/PkYvhtmWol
The Local LLM cheat sheet for your 16GB RAM device
I pulled together a lineup of small models that can run comfortably on a Mac Mini or personal laptop while still leaving room for context without melting your machine.
Models for Daily Use
Qwen3.5 9B / GGUF / Q4_K_M
Daily driver. General chat, drafting, research, translation. If you're keeping only one, keep this.
DeepSeek-R1 Distill Qwen 7B / GGUF / Q4_K_M
Reasoning engine. Math, logic, step-by-step problems. Slower, but worth it when you need actual thinking.
Models for Specialty Work
Qwen2.5 Coder 7B / GGUF / Q4_K_M
Code specialist. Completions, refactors, debugging, repo Q&A. Better than a generalist when the task is code.
Llama 3.1 8B / GGUF / Q4_K_M
Long context worker. RAG, doc chat, codebase Q and A. The output isn't top tier, but the context is strong for its size.
Phi-4 Mini Reasoning / GGUF / Q4_K_M
Compact thinker. Logic, structured answers, math, and short coding bursts. Smaller context is the catch.
Models for Efficiency
Gemma 4 E4B / GGUF / Q4_K_M
Light all-rounder. Writing, chat, light agents, structured output.
Phi-3.5 Mini / GGUF / Q5_K_M
Pocket sidekick. Summaries, extraction, background doc chat. Easy to pair with a bigger model.
Qwen3.5 2B / GGUF / Q4_K_M
Useful for summaries, tagging, rewrites, and lightweight sidekick work.
Micro Models
Qwen3.5 0.8B / GGUF / Q5_K_M
Classification, keyword routing, binary decisions, triage.
Gemma 4 E2B-it / GGUF / Q4_K_M
Lightweight chat, quick Q and A, summaries, tiny agents.
My personal choice for a single model is Qwen3.5 9B
For two models use Qwen3.5 9B + Qwen2.5 Coder 7B for code, or Qwen3.5 9B + Phi-3.5 Mini for support tasks.
Let me know in the comments your experience with these models, or any I have left out.
I have 12 years of experience and working as a Principal Engineer @Atlassian and I have seen concurrency scaring the hell out of a lot of junior engineers.
It’s one of the most feared topics in system design & backend interviews — race conditions, deadlocks, thread pools… you name it.
But once you internalize these 20 must-know concepts, everything clicks.
Save this thread. Read till the end.
Your future interviews and production systems will thank you.
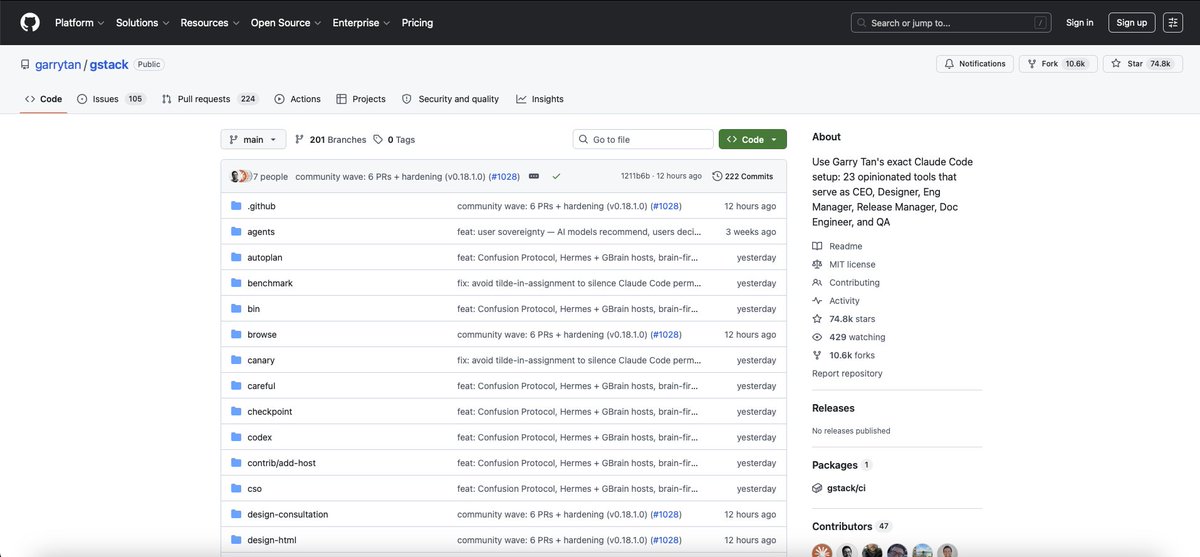
The CEO of Y Combinator just open-sourced his entire AI development setup.
And it is already at 72,600 stars on GitHub.
Garry Tan runs Y Combinator. He has worked with Coinbase, Instacart, and Rippling when they were two people in a garage. Before that he was one of the first engineers at Palantir. He has seen more startups build product than almost anyone alive.
He is now shipping 10,000 to 20,000 lines of production code per day. Part-time. While running YC full-time.
In the last 60 days alone: 600,000 lines of production code. 35% of it tests.
That number is not a typo.
Here is exactly how he does it.
He built a system called gstack — 23 AI tools that turn Claude Code into a full engineering team. He open-sourced the entire thing. Free. MIT license. One command to install. And then he posted the quote that explains why he built it:
"I don't think I've typed like a line of code probably since December, basically, which is an extremely large change." — Andrej Karpathy, March 2026.
When Tan heard that, he wanted to find out how. The result is gstack.
Here is what the 23 tools actually do.
There is a CEO tool that challenges your product framing before you write a line of code. It does not just approve your idea. It finds the 10-star product hiding inside what you described and pushes back on everything you got wrong.
There is an engineering manager that locks architecture, draws ASCII diagrams of data flow, and forces hidden assumptions into the open before anything gets built.
There is a designer that rates every design decision on a 0 to 10 scale, explains what a 10 looks like, and edits the plan until it gets there. It also has AI slop detection. It catches the generic AI output that looks fine and ships badly.
There is a QA lead that opens a real browser, clicks through your actual app, finds bugs, writes regression tests, and verifies the fix. Not a simulation. A real browser.
There is a security officer that runs OWASP Top 10 and STRIDE threat modeling with 17 false positive exclusions built in, so you only see findings that actually matter.
There is a release engineer that syncs main, runs tests, audits coverage, pushes, and opens the PR. One command from approved to shipped.
And then there is something Tan says was the biggest unlock of all.
You can run 10 to 15 of these sprints in parallel. Each one in its own isolated workspace. One agent challenging a product idea. One implementing a feature. One doing QA on staging. Six more on separate branches. All at the same time.
Tan's GitHub contribution graph for 2026 is a vertical wall. In 2013, building Bookface at YC from scratch, he made 772 contributions in a year. In 2026, he is at 1,237 — and still climbing.
Same person. Different era. The difference is the tooling.
One more thing.
In the README, Tan quotes the number directly: 140,751 lines added. 362 commits. 115,000 net lines of code. In one week. Part-time.
That is not what a solo developer looks like. That is what a team looks like.
Except it is one person with 23 AI specialists and a GitHub repo you can clone right now for free.
https://t.co/LRoiMcSYcx
New course: Spec-Driven Development with Coding Agents, built in partnership with @jetbrains, and taught by @paulweveritt.
Vibe coding is fast, but often produces code that doesn't match what you asked for. This short course teaches you spec-driven development: write a detailed spec defining what to build, and work with your coding agent to implement it. Many of the best developers already build this way.
A spec lets you control large code changes with a few words, preserve context across agent sessions, and stay in control as your project grows in complexity.
Skills you'll gain:
- Write a detailed specification to define your mission, tech stack, and roadmap, giving your agent the context it needs from the start
- Plan, implement, and validate features in iterative loops using a spec as your agent's guide
- Apply the same repeatable workflow to both new and legacy codebases
- Package your workflow into a portable agent skill that works across agents and IDEs
Join and write specs that keep your coding agent on track!
https://t.co/hI4GwuvhtN
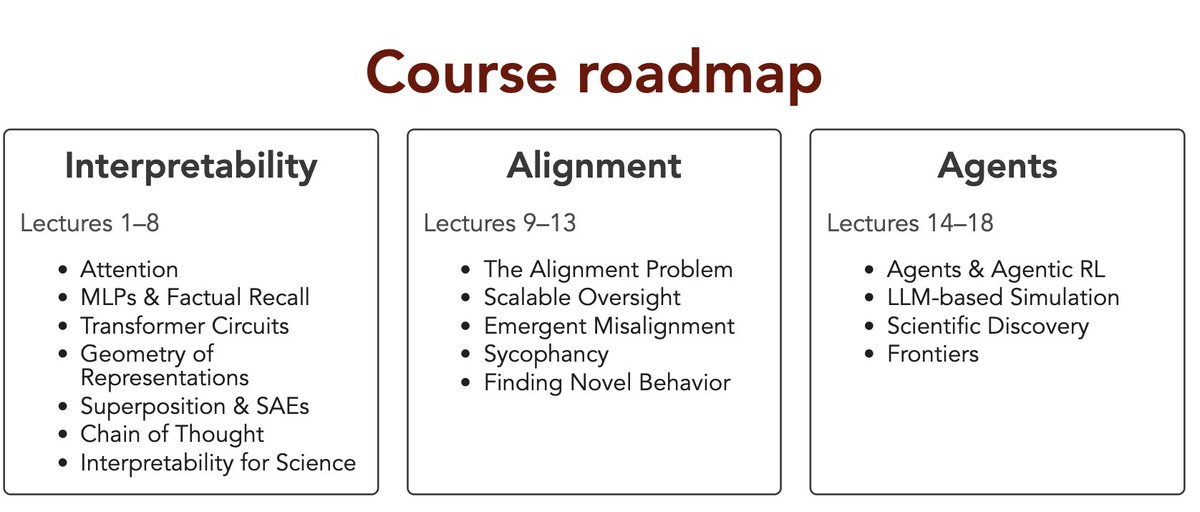
This quarter I am teaching a new course titled Large Language Models. The focus is on interpretability, alignment, and agents.
All the course materials are public: https://t.co/uemYxe6a4T.
I have been procrastinating for three weeks for this post, but hope that the materials are useful!
When I teach, I prepare my lecture notes by writing on Goodnotes, then export them as PDFs and share to the class. Recently I asked claude code to read these PDF files and convert them into markdown. This is a test I constantly gave to new LLMs and now claude is good enough to pass it.
I converted my RL theory graduate-level course into markdowns and post the lecture notes here: https://t.co/CusCmjVWA0
When preparing the course, I learned a lot from the wonderful courses offered by @CsabaSzepesvari@chijinML@WenSun1@nanjiang_cs and borrowed some good stuffs from their notes. Also I discussed what to teach in a RL course heavily with @zhaoran_wang and stole many of his insights.
A few facts:
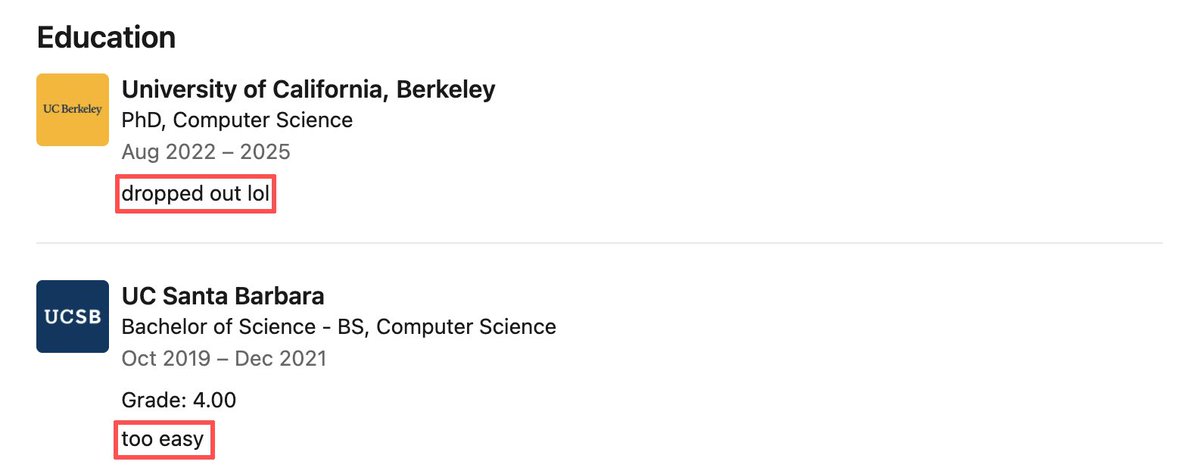
1️⃣ The person who pulled 510k lines of #Claude Code source code from a 60MB source map is a 25 years old boy From China.
2️⃣ His LinkedIn: UCSB in 3 years, 4.0 GPA. His comment:"too easy."
Dropped out of Berkeley PhD after 2–3 years. Comment:"lol."
3️⃣ White hat. Found bugs in X, Chrome. $1.9M in bounties.
4️⃣ He called out Anthropic last year for scraping user code under the guise of "safety reviews."
5️⃣ After the leak, his take:"Claude's code is nowhere near as interesting as OpenCode's."