@dwarkesh_sp Today’s models still suck in certain types of brainstorming such as:
1. Ideating names for things (model-generated names are slop)
2. Providing comprehensive lists of things (“list restaurants I might reserve tonight” -> model only lists a few options, none desirable)
MAI-Thinking-1: A powerful reasoning model developed from scratch that is competitive with models of similar size on STEM reasoning and coding tasks.
Our pre-training focused on a simple scaling emphasizing data-driven iterative improvements to our architecture and data. Our reinforcement learning (RL) framework is optimized for sustained log-linear climbs over many thousands of steps
We are openly sharing all technical details and learnings to build a transparent and science-driven approach to further development in AI
Read More: https://t.co/yK9Cd5loUd
AI agents are advancing research-level math. 🚀
I’m thrilled to share @GoogleDeepMind’s AlphaProof Nexus - an agentic framework for formal proof search powered by Gemini.
When applied to a set of open formal math problems, our agent autonomously solved:
✅ 9 open Erdős problems (including two open for 56 years!)
✅ 44 Online Encyclopedia of Integer Sequences (OEIS) problems
✅ A 15-year-old open problem in algebraic geometry ✅ A 7-year-old open question in min-max optimization
We are collaborating with mathematicians across disciplines - from combinatorics and graph theory to quantum optics. Ultimately, these results show the massive potential of even simple agentic loops powered by Gemini.
Read the paper here: https://t.co/c5M9ZjRXU1
AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
https://t.co/SD1vVPkrHR
@nrehiew_ Is there more or less forgetting vs RL, if one constructs SFT dataset like this (for 0/1 rewards):
Annotators label data sampled from the initial model’s policy, and then we only keep the high-reward samples.
Will that be closer to original distribution than RL distribution?
Jensen is one the smartest and most far seeing folks the world.
"If an AI scientist warns people that AI is going to permeate across radiology and radiologists are going to get wiped out, it might seem helpful but it's hurtful. If we convince everybody not to be radiologists and we now need radiologists, that actually is hurtful to society.
"It is hurtful to convince all the young college graduates not to study software engineering because we are going to need more software engineers than ever.
That's hurtful."
"Scaring people with nonsensical things, which are not going to happen, that this is an existential threat, there's a 20% chance that is is existential, that's ridiculous.
"That it's going to wipe out 50% of college level jobs.
"That is it going to completely destroy democracy.
"These kinds of comments are not helpful. They are made by...CEOS. And you become a CEO, maybe you adopt a God complex and somehow you know everything."
Brutal.
And right.
Big Update🤩: #paperclip now includes full papers from all of arXiv, PubMed Central and 150 million abstracts!🖇️
You can give your LLM all that knowledge in one line—all optimally indexed for AI agents. Much more thorough and ~100x faster than web search, and free.
Students are learning to build with Codex, and building to learn.
Here’s what @UCBerkeley students built at the Codex Creator Challenge with @joinHandshake.
New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
Researchers' brilliant ideas often get lost in the sea of endless SOTA claims on weak baselines. At Marin we battle-test ideas in an open arena, where anyone's idea can be promoted to the next hero run. One that recently rose up was @Jianlin_S MoE Quantile Balancing, used in our last 1e22 and ongoing 130B run. Animated visuals of how QB performed are available in the OpenAthena blog. https://t.co/BDSsonuNH7
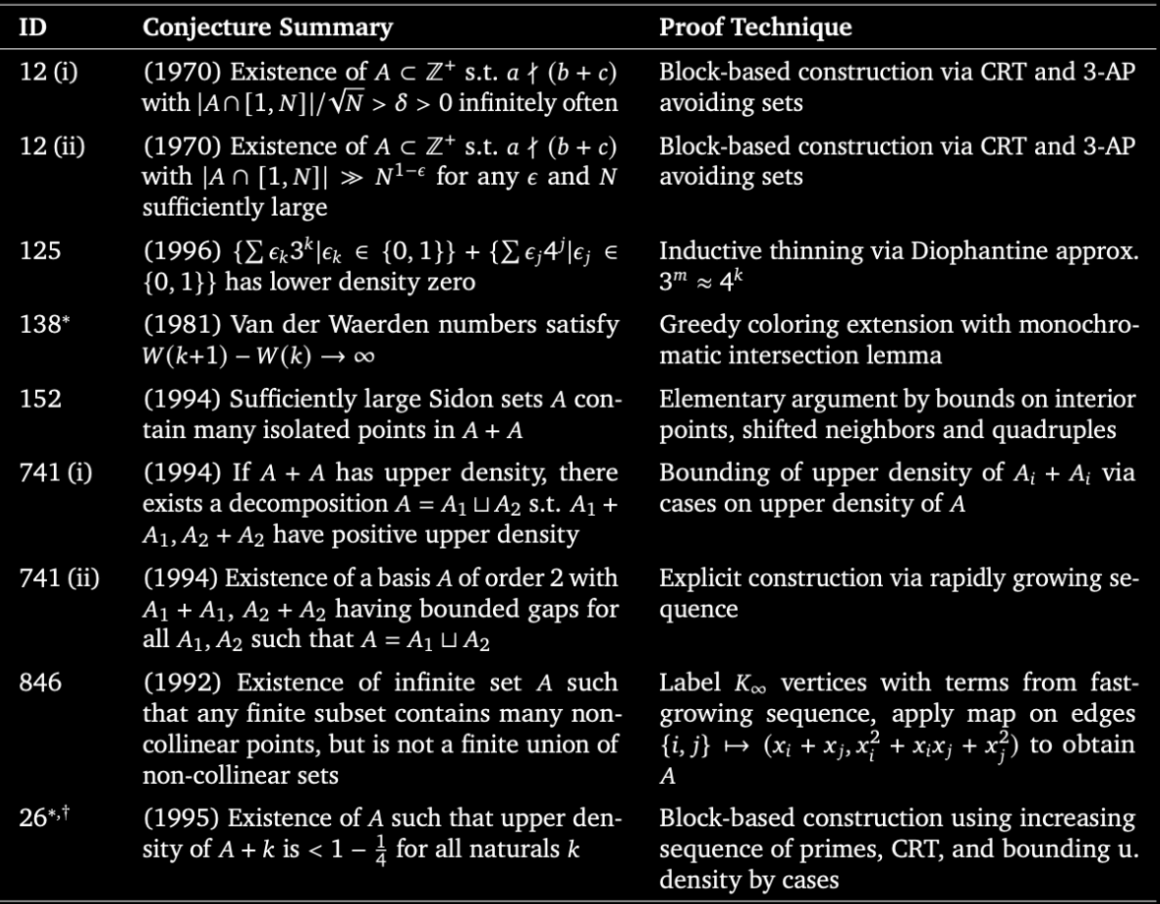
In my doctorate, I proved the Erdős Primitive Set Conjecture, showing that the primes themselves are maximal among all primitive sets.
This problem will always be in my heart: I worked on it for 4 years (even when my mentors recommended against it!) and loved every minute of it.
[Primitive sets are a vast generalization of the prime numbers: A set S is called primitive if no number in S divides another.]
Now Erdős#1196 is an asymptotic version of Erdős' conjecture, for primitive sets of "large" numbers.
It was posed in 1966 by the Hungarian legends Paul Erdős, András Sárközy, and Endre Szemerédi.
I'd been working on it for many years, and consulted/badgered many experts about it, including my mentors Carl Pomerance and James Maynard.
The the proof produced by GPT5.4 Pro was quite surprising, since it rejected the "gambit" that was implicit in all works on the subject since Erdős' original 1935 paper. The idea to pass from analysis to probability was so natural & tempting from a human-conceptual point of view, that it obscured a technical possibility to retain (efficient, yet counter-intuitve) analytic terminology throughout, by use of the von Mangoldt function \Lambda(n).
The closest analogy I would give would be that the main openings in chess were well-studied, but AI discovers a new opening line that had been overlooked based on human aesthetics and convention.
In fact, the von Mangoldt function itself is celebrated for it's connection to primes and the Riemann zeta function--but its piecewise definition appears to be odd and unmotivated to students seeing it for the first time. By the same token, in Erdős#1196, the von Mangoldt weights seem odd and unmotivated but turn out to cleverly encode a fundamental identity \sum_{q|n}\Lambda(q) = \log n, which is equivalent to unique factorization of n into primes. This is the exact trick that breaks the analytic issues arising in the "usual opening".
Moreover, Terry Tao has long suspected that the applications of probability to number theory are unnecessarily complicated and this "trick" might actually clarify the general theory, which would have a broader impact than solving a single conjecture.
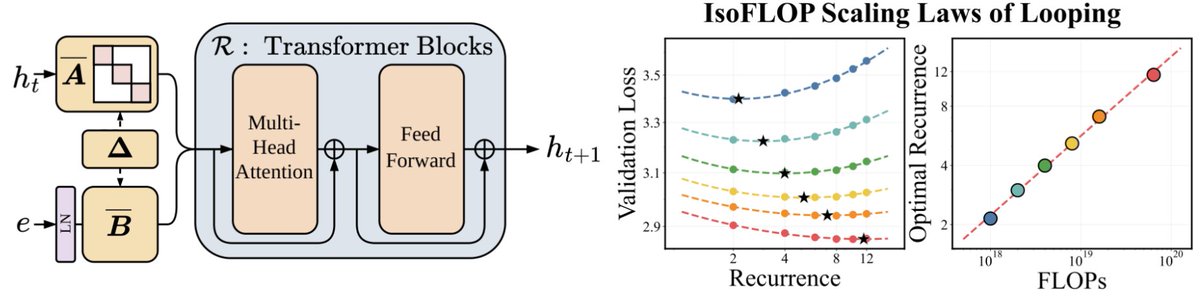
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
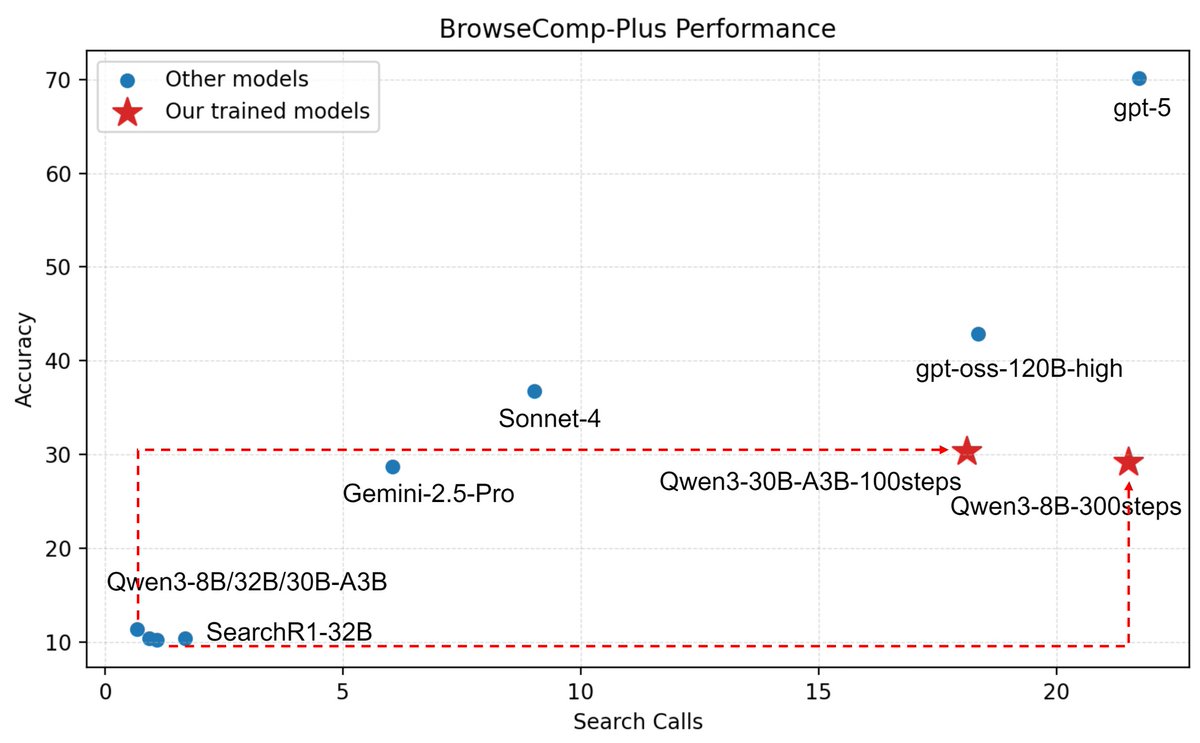
Pleased to share our engineering practices for medium-sized LLMs in multi-turn agentic search, where we boosted Qwen3 8B and Qwen3 A3B from 1-2 turn search and 10% accuracy on Browsecomp-Plus to 15+ and 20+ turns with 30% accuracy. The devils are in the details; we hope our practices in stable RL training and data processing can help the community!
Link: https://t.co/PnDUJRcOJM
Chinese version: https://t.co/pMYF5lFtUw
🧵
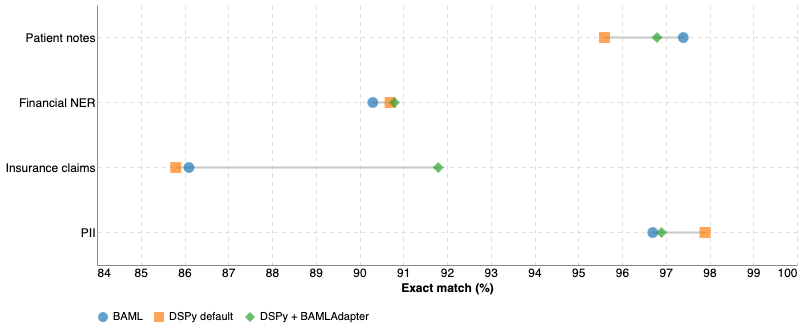
I compared the performance of @boundaryML BAML and @DSPyOSS for a variety of structured outputs, and the results are interesting: different datasets, models and schema formats results in wildly different outcomes, some of then unexpected. There's no universal winner (which means that prompt optimization matters, more than ever, because it's *very* hard to discover the right prompts as a human).
The benchmarks compare BAML's and DSPy's performance (with similar user instructions and description annotations). I also use `BAMLAdapter` in DSPy (which implements BAML's schema formatting in a custom DSPy adapter).
Why use a custom adapter in DSPy? Because it has benefits, especially when dealing with nested data, as the experiments show. 👇🏽
1/7