PewDiePie dropping an AI harness on Github that gets to 55k+ stars in the first few days is probably the most surprising development this year in AI
https://t.co/GRrAkzfc9h
We've raised $65 billion in Series H funding at a $965 billion post-money valuation, led by @AltimeterCap, Dragoneer, @Greenoaks, and @sequoia.
This investment will help us advance our research and expand our capacity to meet growing demand for Claude.
JUST IN: Michael Saylor's Strategy proposes selling some Bitcoin to pay dividends.
"You buy Bitcoin with credit, you let it appreciate, and then you sell Bitcoin to pay the dividend."
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Polymarket Accelerates in early 2026
3x more traffic than all other Prediction Markets combined
Counting the math, one in 31 people with internet access from non-restricted region has visited Polymarket website at least once during last 90 days
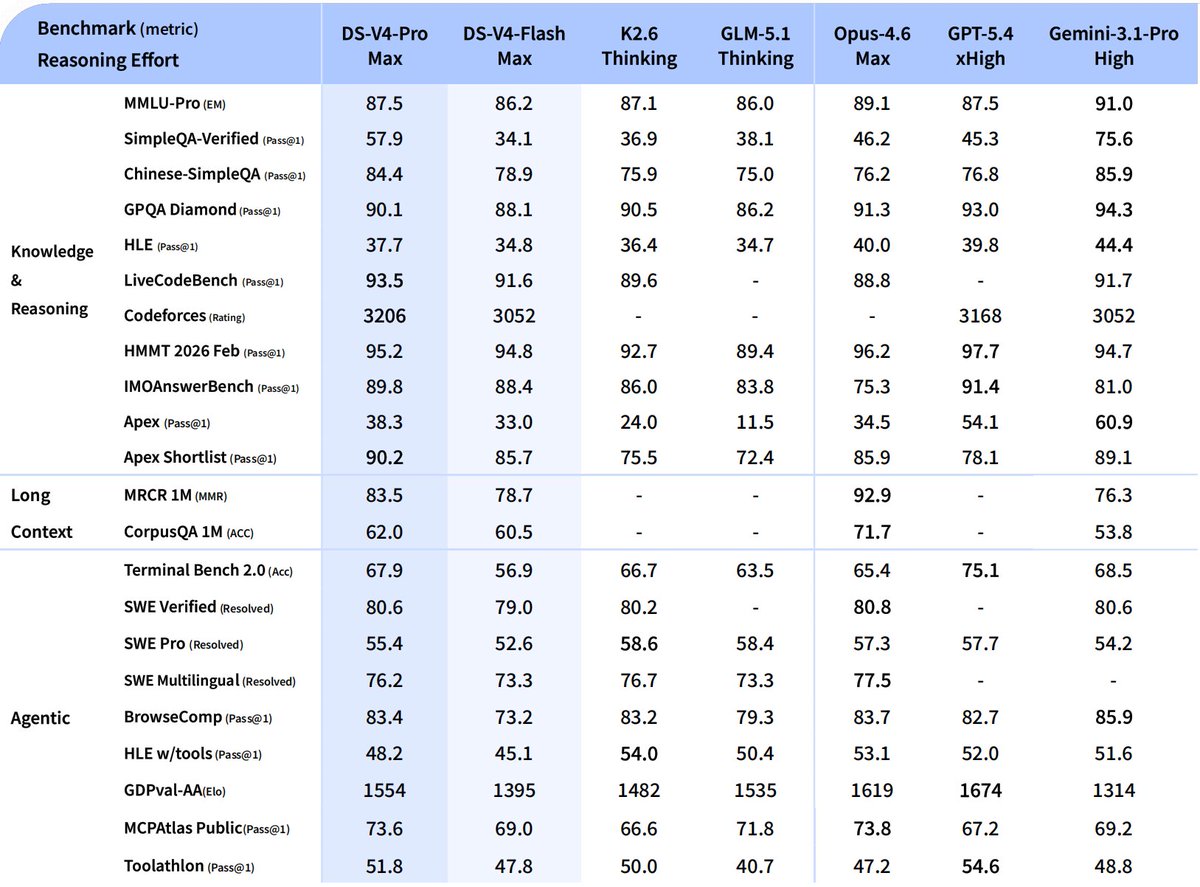
DeepSeek-V4-Flash costs $0.14/$0.28 per M input/output tokens, making it extremely cost efficient for its level of intelligence.
It's a drop-in replacement for Gemini 3 Flash or MiniMax 2.5 that produces much more output for the same cost with similar speed. Also open weights!
DeepSeek-V4-Flash
🔹 Reasoning capabilities closely approach V4-Pro.
🔹 Performs on par with V4-Pro on simple Agent tasks.
🔹 Smaller parameter size, faster response times, and highly cost-effective API pricing.
3/n