@livgorton We have a solution to this problem, "CiteGuard: Faithful Citation Attribution for LLMs via Retrieval-Augmented Validation" (ACL'26 oral) led by @yeemanchoi and @eagle_hz ! Hope research reviewing platforms such as @openreviewnet can consider adopting the integration as well :)
Can LLMs cite like humans?🧐 Meet CiteGuard 🛡️our retrieval-augmented agent for faithful citation attribution. +17% over prior baselines and 68.1% on CiteME, near-human accuracy #ACL2026#ai4scientist#LLM
🚨 Excited to share that our paper CiteGuard https://t.co/1mEElRMkm8 is accepted to ACL 2026 (Main)!
LLMs are powerful for scientific writing—but up to 90% of their citations can be fabricated.
Why this matters + our solution 👇
📢 The First Call for Papers for EMNLP 2026 is officially out! 📝
We welcome long & short papers featuring original research on empirical methods for NLP.
🗓️ ARR Submission Deadline: May 25, 2026
🔗 Read the full CFP here: https://t.co/GU2kaISjUG
#EMNLP2026
We need more 𝗼𝗽𝗲𝗻, 𝗿𝗲𝗮𝗹𝗶𝘀𝘁𝗶𝗰 𝗮𝗴𝗲𝗻𝘁 𝗲𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁𝘀 for training and evaluating agents! 💡
🚀But what are the 𝗶𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁 𝗲𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁𝘀 𝘁𝗼 𝗯𝘂𝗶���𝗱?
📈What are the 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗯𝗼𝘁𝘁𝗹𝗲𝗻𝗲𝗰𝗸𝘀 for these environments in training and evaluation, and how can we 𝘀𝗰𝗮𝗹𝗲 𝘂𝗽 the number of available environments?
🌟Most importantly, how should we utilize these environments: 𝗥𝗟 𝗼𝗿 𝗯𝗲𝘆𝗼𝗻𝗱?
If you’re interested in discussing together, come join us at our workshop on “𝙎𝙘𝙖𝙡𝙞𝙣𝙜 𝙀𝙣𝙫𝙞𝙧𝙤𝙣𝙢𝙚𝙣𝙩𝙨 𝙛𝙤𝙧 𝘼𝙜𝙚𝙣𝙩𝙨” @NeurIPSConf tmr (7th Dec)! We have an amazing lineup of invited speakers and panelists, including 𝐄𝐝𝐰𝐚𝐫𝐝 𝐆𝐫𝐞𝐟𝐞𝐧𝐬𝐭𝐞𝐭𝐭𝐞 from 𝐆𝐨𝐨𝐠𝐥𝐞 𝐃𝐞𝐞𝐩𝐌𝐢𝐧𝐝 and 𝐒𝐡𝐮𝐲𝐚𝐧 𝐙𝐡𝐨𝐮 from 𝐃𝐮𝐤𝐞.
Also check out our latest 𝐬𝐮𝐫𝐯𝐞𝐲 𝐩𝐚𝐩𝐞𝐫 on the topic led by Yuchen Huang: https://t.co/gvsdqkp6jf 🎯
The SEA Workshop at @NeurIPSConf 2025 is coming next Sunday. It seems we urgently need more open, realistic agent environments for training and evaluating agents. But what are the important environments to build? What are the infrastructure bottlenecks for these environments in training and evaluation? How can we scale up the number of available environments? And how should we use these environments, RL or beyond? These questions are still not clear.
We’re bringing together an amazing list of speakers and panelists to spark the discussion: @egrefen, @Mike_A_Merrill, @mialon_gregoire, @deepaknathani11, @jl_marino, @syz0x1, @qhwang3, Anthony G. Cohn, Eric Sommerlade, and @fredsala. You won’t want to miss it if you’re around.
Also, huge thanks to our four sponsors, @TheInclusionAI (@AntLingAGI), @SnorkelAI, @SonicjobsApp, and @VmaxAI for their generous support!
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵
#EMNLP Keynote by @hengjinlp:
No more Processing. Time to Discover!
AI for Science is just so exciting! Let us make LLMs discover like true scientists: Observe → Think → Propose and Verify
(A pity to miss the talk. Photo from @May_F1_@emnlpmeeting )
What if your policy could reason and think dynamically, especially about uncertainty, enabling better real-world behavior?
⚡️Introducing EBT-Policy, an instantiation of Energy-Based Transformers for Policies!
TLDR:
- EBT-Policy broadly outperforms Diffusion Policy in both simulated and real-world tasks, while using significantly less (up to 50x less) resources during both training and inference.
- EBT-Policy is the first vanilla Behavior Cloning approach to demonstrate emergent zero-shot retry behavior—recovering from failures/OOD states using only successful demos, with no retry data/training.
- EBT-Policy successfully learns uncertainty, enabling dynamic compute allocation for action sequences it’s more uncertain about.
🧵Thread:
Introducing UniDoc-Bench: The First Unified Benchmark for Document-Centric Multimodal RAG
📄 Paper: https://t.co/33S6yvibzO
Real documents mix text, tables, and charts—but most RAG benchmarks test them in isolation. We built UniDoc-Bench to change that.
📊 What's inside:
➡️ 70K PDF pages across 8 domains
➡️ 1,600 QA pairs grounding text, tables & images
➡️ Fair comparison across 4 RAG paradigms
🔍 Key finding: Text-image fusion RAG (68.4%) beats both multimodal joint retrieval (64.1%) and single-modality approaches. Current multimodal embeddings still lag behind combining strong unimodal retrievers.
💻 Code: https://t.co/gzVHUqRb0i
📊 Data: https://t.co/UndBiJ3Aqy
➡️ Work by Xiangyu Peng @beckypeng6, Can Qin @canqin001, Zeyuan Chen @ZeyuanChen, Ran Xu @stanleyran, Caiming Xiong @CaimingXiong, and Chien-Sheng Wu @jasonwu0731.
#FutureOfAI #EnterpriseAI #MultimodalAI #DocumentIntelligence
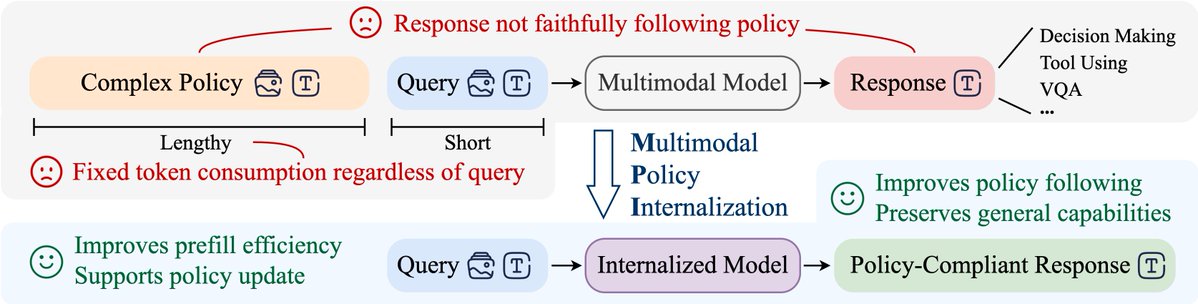
Multimodal conversational agents struggle to follow complex policies, which also impose a fixed computational cost.
We ask:
👉 How can we achieve stronger policy-following behavior without having to include policies in-context?
🌐: https://t.co/mIdhuPw6Cj 🧵1/3
Our VISTA workshop at ICDM 2025 is still open for submissions!
If you’re working on GenAI standards, legal constraints, copyright risks, & compliance, we’d love to see your papers! 📄✨
🧵More information and submit:
🚨 Call for Papers: VISTA Workshop @ ICDM 2025 🚨
📅 Nov 12, 2025 | 📍 Washington, DC
Explore GenAI standards, legal constraints, copyright risks, & compliance. Submit by Sep 5!
🔗 https://t.co/MjmZx8UunI
Speakers: V. Braverman, D. Atkinson, A. Li
#ICDM2025#GenAI#AIStandards
🚨 Deadline Extended! 🚨
Our Scaling Environments for Agents 🧑💻🤖 workshop at @NeurIPSConf 2025 is still open for submissions!
If you’re working on scaling, environments, or agents, we’d love to see your papers! 📄✨
📅 New deadline: Sept 1st
🧵More information and submit: