at @neurips today and tmrw!
pls do lmk if you want to talk about:
- periodic / vision / ai scientists https://t.co/IMxIgeOXVb
- technicals, i.e., how to:
---
will be at https://t.co/1946zXpi4u with the rest of the @periodiclabs folks, some socials
bonus (2/2): always thought conferences would be a great time to enable in-person collabs / research jams (when else are we all together)
maybe a bit tight this year, but have a big backlog of blog ideas / early methods to derisk, and a stash of tinker credits to burn
- curious if ppl interested?
(ty @dchaplot, @thinkymachines for all the support, maybe it uniquely enables this kind of collab? and @jerrywliu for enabling this post lol)
some past examples (last one especially great❤️)
1. https://t.co/5ensucKpTC
2. https://t.co/gCA6dqi6bv
3. https://t.co/oOJlZgkzMS (tbt the goats @EyubogluSabri@simran_s_arora )
at @neurips today and tmrw!
pls do lmk if you want to talk about:
- periodic / vision / ai scientists https://t.co/IMxIgeOXVb
- technicals, i.e., how to:
---
will be at https://t.co/1946zXpi4u with the rest of the @periodiclabs folks, some socials
if you’re interested in autonomous science at frontier scale, come find the @periodiclabs team at neurips!
look for:
@vwxyzjn to discuss training big MoEs
@xiangfu_ml for atomic GNNs
@mzhangio for AI scientists
@VincentMoens for RL systems
me for midtraining sample efficiency
do chat w Jerry! he's been doing a lot of great foundational work on numerical precision in ML settings, think this would go a long way w improving science modality foundation models
(as you may imagine, while softmax attn and bf16 are great for decoding to tokens, it kinda wrecks what the models can pick up for some modalities)
I’ll be at NeurIPS until Sunday! My work focuses on understanding the core mechanics of ML architectures, recently: (1) pushing ML toward better numerics, and (2) *constructively* understanding mechanisms for fact-storage. If you're excited about how deeper algorithmic insight can unlock new capabilities (esp. in AI+science), let’s chat. Also open to spring/summer 2026 internships!
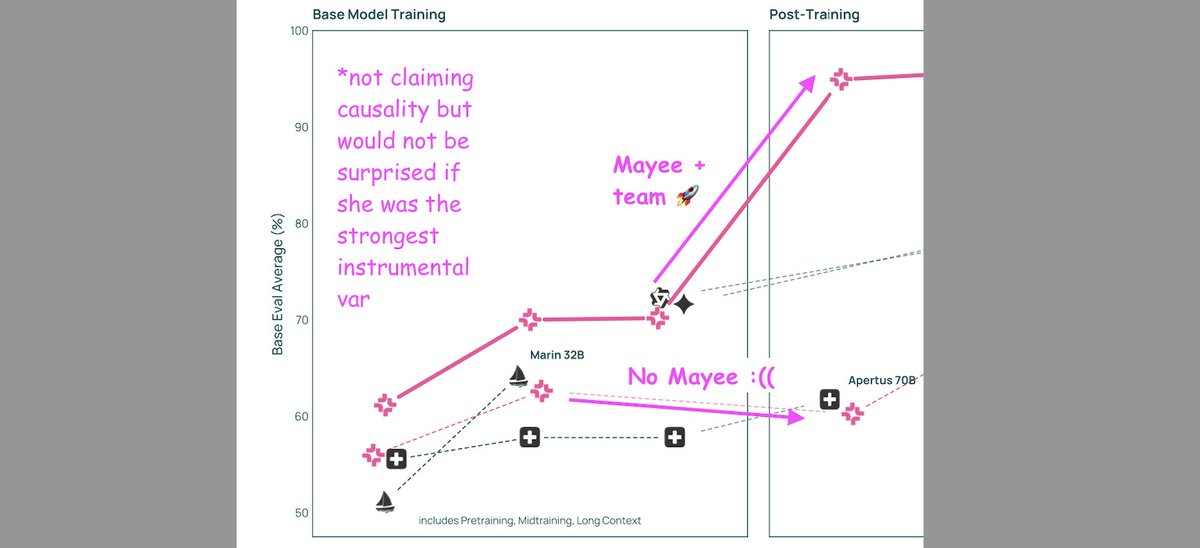
v cool to see Mayee's work shape up to one of the more interesting + timely Q's
how to curate pretraining data to optimize for post-trained performance?
- yes you want deduplication, yes you want diverse data
- but there's so much more fun stuff to do (rt @hazyresearch and the 2023 coreset notes...)
- and open questions!
(how should pretraining distributions change if we're targeting specific domains? conversely, or multiple RL tasks? cost-wise, should we pour more tokens into "it just works" next-token prediction if it means needing to do less RL later on?)
Thrilled to have contributed to Olmo 3! The best fully open 32B model (data, training recipes, checkpoints and more!)
As an intern at AI2 these last 8 months, I’ve grown to deeply appreciate the careful science, iteration, and collaboration that go into models like this and have learned so much from the team. I am more optimistic than ever about the future of open-source and data-centric research right now.
My particular contribution was working on the Dolma 3 data mix 👩🍳 I was able to apply ideas from some of my earlier mixing work, explore new problem settings, and see firsthand the data challenges that arise when building datasets intended for real models at scale. More on this coming soon!
We were surprised to learn that the very best AMD kernels out there are hand-optimized by a handful of engineers **in raw assembly**. Unsurprisingly, this is difficult to scale to the breadth of AI workloads we need to support. It's difficult to read and modify.
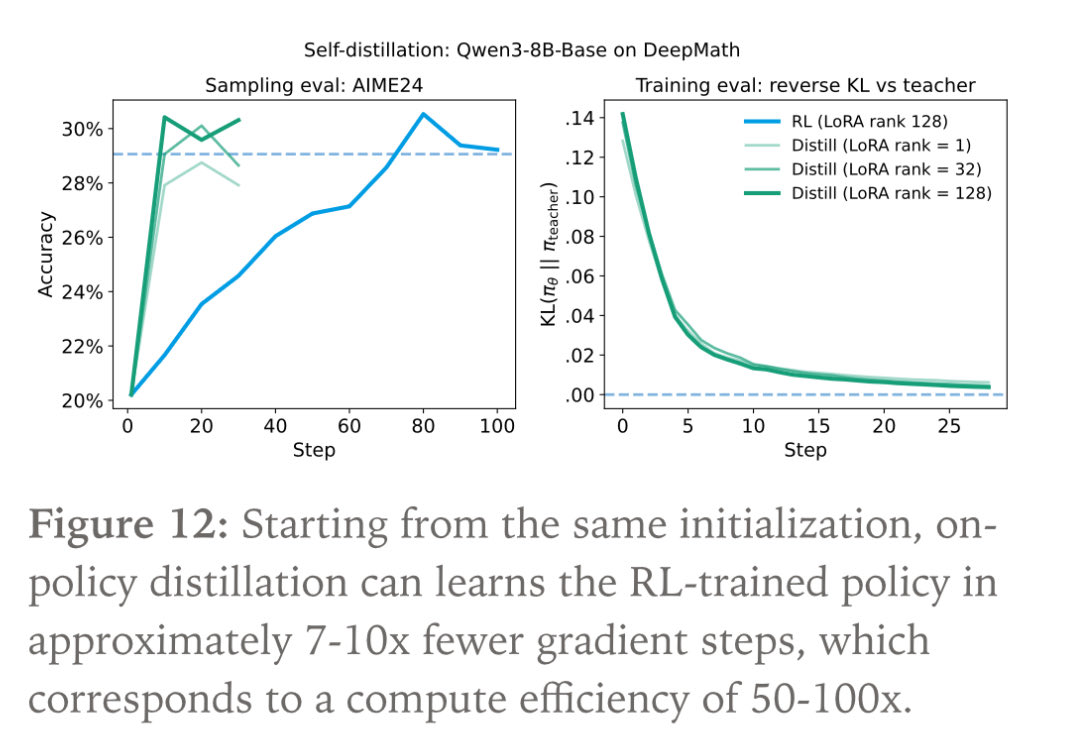
cool post!
was curious did y’all also ablate the effect of “on-policy” and “distillation”?
i.e., did you compare against:
- supervising w reverse KL but no importance weighting (was this “off-policy distill” or was that just sft on big model traces?)
- just importance-weighted xent on expert trajectories
maybe @agarwl_ you recall? (ig could msg, but why keep things on slack when we can share a fun discussion here :)
aren’t we starting w much stronger priors tho
iirc before it was randomly initialized NNs, where tbh it was a miracle they could latch onto anything thru all the sampling (not to mention trying to predict the final outcome from a partial rollout? lots of noise!)
now w pretrained LLMs it’s like the tasks are more ID to the base policies; they can already “operate the controls” to some extent and we have less to teach
yess; excited to see Reflection take on American open-source
i think the bossman @HazyResearch put it best below (source in reply). We owe a lot to Qwen, K2, and Deepseek today. But we also owe it to ourselves to at least have a parallel set of Western models. This keeps things competitive, and lets us continue picking models, doing research, and building progress based on quality alone.
@achowdhery has been a personal inspiration; excited to see what she, @MishaLaskin, and the team share
(even better if it’s a family of models from 4B to 235B MoE that researchers and startups can do post-training scaling curves on 🙏😅)
Today we're sharing the next phase of Reflection.
We're building frontier open intelligence accessible to all.
We've assembled an extraordinary AI team, built a frontier LLM training stack, and raised $2 billion.
Why Open Intelligence Matters
Technological and scientific progress is driven by values of openness and collaboration.
The internet, Linux, and the protocols and standards that underpin modern computing are all open. This isn't a coincidence. Open software is what gets forked, customized, and embedded into systems worldwide. It's what universities teach, what startups build on, what enterprises deploy.
Open science enables others to learn from the results, be inspired by them, interrogate them, and build upon them in order to push the frontier of human knowledge and scientific advancement. AI got to where it is today through scaling ideas (e.g. self-attention, next token prediction, reinforcement learning) that were shared and published openly.
Now AI is becoming the technology layer that everything else runs on top of. The systems that accelerate scientific research, enhance education, optimize energy usage, supercharge medical diagnoses, and run supply chains will all be built on AI infrastructure.
But the frontier is currently concentrated in closed labs. If this continues, a handful of entities will control the capital, compute, and talent required to build AI, creating a runaway dynamic that locks everyone else out. There's a narrow window to change this trajectory. We need to build open models so capable that they become the obvious choice for users and developers worldwide, ensuring the foundation of intelligence remains open and accessible rather than controlled by a few.
What We've Built
Over the last year, we've been preparing for this mission.
We’ve assembled a team who have pioneered breakthroughs including PaLM, Gemini, AlphaGo, AlphaCode, AlphaProof, and contributed to ChatGPT and Character AI, among many others.
We built something once thought possible only inside the world’s top labs: a large-scale LLM and reinforcement learning platform capable of training massive Mixture-of-Experts (MoEs) models at frontier scale. We saw the effectiveness of our approach first-hand when we applied it to the critical domain of autonomous coding. With this milestone unlocked, we're now bringing these methods to general agentic reasoning.
We've raised significant capital and identified a scalable commercial model that aligns with our open intelligence strategy, ensuring we can continue building and releasing frontier models sustainably. We are now scaling up to build open models that bring together large-scale pretraining and advanced reinforcement learning from the ground up.
Safety and Responsibility
Open intelligence also changes how we think about safety. It enables the broader community to participate in safety research and discourse, rather than leaving critical decisions to a few closed labs. Transparency allows independent researchers to identify risks, develop mitigations, and hold systems accountable in ways that closed development cannot.
But openness also requires confronting the challenges of capable models being widely accessible. We're investing in evaluations to assess capabilities and risks before release, security research to protect against misuse, and responsible deployment standards. We believe the answer to AI safety is not “security through obscurity” but rigorous science conducted in the open, where the global research community can contribute to solutions rather than a handful of companies making decisions behind closed doors.
Join Us
There is a window of opportunity today to build frontier open intelligence, but it is closing and this may be the last. If this mission resonates, join us.
original blog post for screenshot: https://t.co/zjpWqIpYVB
(i don’t endorse all the aesthetics but agree w the overall message above, and am thankful to have an advisor + lab that welcomes discussion and discourse :))
GPUs are expensive and setting up the infrastructure to make GPUs work for you properly is complex, making experimentation on cutting-edge models challenging for researchers and ML practitioners.
Providing high quality research tooling is one of the most effective ways to improve research productivity of the wider community and Tinker API is one step towards our mission there.
Tinker API is built on top of our experimental results on fine-tuning with LoRA: https://t.co/bV00V1cBKG
Beta starts and you can join the waitlist today: https://t.co/AbzVwxYyjm
oh yes you can also apply for jobs directly here
https://t.co/EAqKOsk3dQ
- pick the other role for RL or any other jobs you might like
(we have fun slack emojis and many things to post-train)
excited to share what we’ve been up to!
at Periodic Labs, we’re creating AI scientists
they think, design experiments, and optimize for results
they also run experiments by moving robot arms in an autonomous lab
it’s a fun, multi-turn task, with lots of open problems for AI in the real world
https://t.co/R1vJ9dK1QL
Today, @ekindogus and I are excited to introduce @periodiclabs.
Our goal is to create an AI scientist.
Science works by conjecturing how the world might be, running experiments, and learning from the results.
Intelligence is necessary, but not sufficient. New knowledge is created when ideas are found to be consistent with reality. And so, at Periodic, we are building AI scientists and the autonomous laboratories for them to operate.
Until now, scientific AI advances have come from models trained on the internet. But despite its vastness — it’s still finite (estimates are ~10T text tokens where one English word may be 1-2 tokens). And in recent years the best frontier AI models have fully exhausted it.
Researchers seek better use of this data, but as any scientist knows: though re-reading a textbook may give new insights, they eventually need to try their idea to see if it holds.
Autonomous labs are central to our strategy. They provide huge amounts of high-quality data (each experiment can produce GBs of data!) that exists nowhere else. They generate valuable negative results which are seldom published. But most importantly, they give our AI scientists the tools to act.
We’re starting in the physical sciences.
Technological progress is limited by our ability to design the physical world.
We’re starting here because experiments have high signal-to-noise and are (relatively) fast, physical simulations effectively model many systems, but more broadly, physics is a verifiable environment. AI has progressed fastest in domains with data and verifiable results - for example, in math and code. Here, nature is the RL environment.
One of our goals is to discover superconductors that work at higher temperatures than today's materials. Significant advances could help us create next-generation transportation and build power grids with minimal losses. But this is just one example — if we can automate materials design, we have the potential to accelerate Moore’s Law, space travel, and nuclear fusion.
We’re also working to deploy our solutions with industry. As an example, we're helping a semiconductor manufacturer that is facing issues with heat dissipation on their chips. We’re training custom agents for their engineers and researchers to make sense of their experimental data in order to iterate faster.
Our founding team co-created ChatGPT, DeepMind’s GNoME, OpenAI’s Operator (now Agent), the neural attention mechanism, MatterGen; have scaled autonomous physics labs; and have contributed to some of the most important materials discoveries of the last decade. We’ve come together to scale up and reimagine how science is done.
We’re fortunate to be backed by investors who share our vision, including @a16z who led our $300M round, as well as @Felicis, DST Global, NVentures (NVIDIA’s venture capital arm), @Accel and individuals including @JeffBezos , @eladgil , @ericschmidt, and @JeffDean. Their support will help us grow our team, scale our labs, and develop the first generation of AI scientists.
more of my own takes in this post below
if you’re excited about helping out, or think this could be helpful to accelerating your own R&D, please reach out 🙂
https://t.co/PJVlBmDoca
I asked Liam: Why name our startup Periodic Labs? He said think about *periods* in time. And then it hit me: we define entire periods of history by their critical materials: Copper Age → Bronze Age → Iron Age → Silicon Age.
The name says all about our mission: to discover the materials that will define our future.