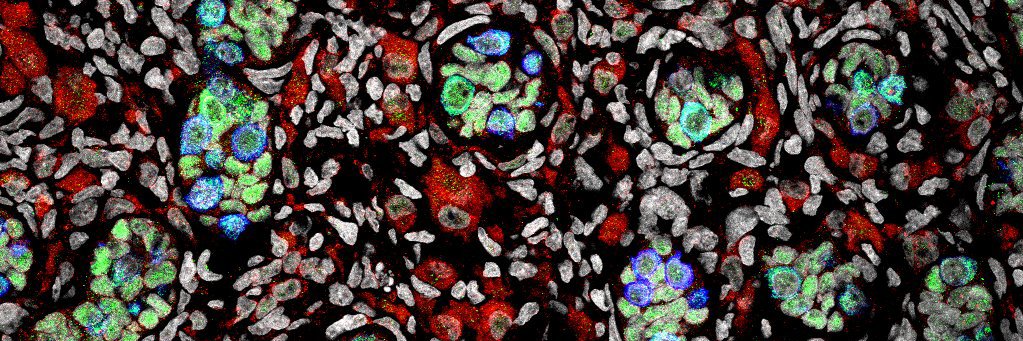
Excited to share our Review on human PGC development covering the latest in vivo observations & in vitro developments, particularly in the last 5 years. If you’re interested – have a read! https://t.co/UI7QEG6TI3
From: @astar_gis@karolinskainst@uniofwarwick@GurdonInstitute
The average timeline for a drug in clinical testing - after developing drug candidates - takes around a decade.
Even if all diseases were mapped to genes, which they aren't, because of polygenicity, the difficulties of recruiting with sufficient power for running association studies, functional validation, and so on, it would still take a long time for that to result in treatments for most diseases.
But it also seems false that sequencing hasn't led to better medicines and health. Consider:
- Many rare disease drugs including nusinersen (for spinal muscular atrophy), ivacaftor (for cystic fibrosis), and voretigene neparvovec (for retinal dystrophy) came from sequencing
- Highly effective siRNA drugs for cholesterol and other liver diseases depend on sequencing their targets
- RSV and Covid vaccines that involved stabilizing proteins through genetic engineering based on sequence
- New, more stable oral polio vaccines based on the sequence of the Sabin type 2 strain
- PCSK9 inhibitors like evolocumab for LDL cholesterol, based on rare loss-of-function variants identified through sequencing
- and many more examples...
I think the underlying problem is misunderstanding causality: different aspects of drug development aren't additive.
Even if genome sequencing was a necessary cause of certain drugs existing, that doesn't make it sufficient.
In a world where it was indispensable, other bottlenecks could still prevent that contribution from showing up in outcomes at all. And clinical trials are a bottleneck.
But genomics has touched nearly every part of biology! And I expect that we'll increasingly see the fruits of the genomic revolution as time goes by, not solely through mapping genes to diseases and developing drugs to target them, but by developing new genetic engineering tools and platforms too.
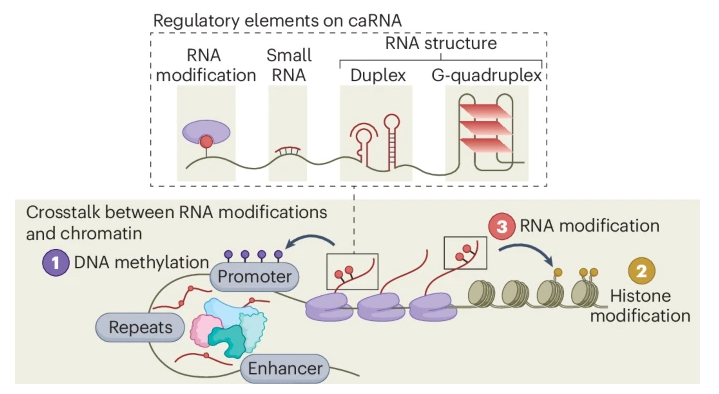
A new Perspective discusses recent developments in RNA modifications on chromatin-associated RNAs, how they modulate chromatin states, and future direction for studying RNA regulatory elements to control gene expression
https://t.co/a2tMAH02ra
HERRO has been published in @Nature !!
https://t.co/zZFSuYvXq7
This achievement is a result of the great work by @domstanojevic, with contributions from @DehuiLin, @sergeynurk, and @PaolaFlorezdeS
We are entering the era of high-quality genome assemblies supported by AI. This is just the beginning.
New paper out in @CellStemCell . We uncover unexpected complexity in how metabolism changes when the embryo implants or when stem cells exit naive pluripotency, revealing a central role for dynamic TCA cycle rewiring in cell fate decisions. https://t.co/YftwM1ZkMX
IRB reform proposal w/ @IFP: Giving researchers the right to choose their Institutional Review Board (IRB) from accredited ones would bring accountability & consistency to ethics review and speed up life-saving research by avoiding bureaucratic gridlocks.
https://t.co/pa517jt9nC
Excited to share that my second paper from graduate school is out now at Nature Genetics. We show that Enhancer-Promoter interactions can form de novo in the absence of loop extrusion.
https://t.co/GOGyzCf8U8
Using synthetic enhancer combinations to switch on lethal payloads only when in the correct target cancer cells.
News&Views: https://t.co/163YpflDVf
Article: https://t.co/6XqlG2qF9b
Our Human Multiomic Development Atlas paper is out in Nature today! A heart-felt "thank you" to all co-authors for their tireless work on this complex yet exciting project! Congrats all! https://t.co/iUiZz00KOt
The story about bureaucracy almost stopping a man from treating his dog’s cancer with an mRNA vaccine went viral.
The problem transfers to humans: we’ve made these clinical trials unnecessarily hard, denying hope to patients.
New article on this.
https://t.co/11JweSHisz
Excerpts:
"A story about Paul Conyngham, an AI entrepreneur from Sydney who treated his dog Rosie’s cancer with a personalized mRNA vaccine, has been circulating on X since yesterday. What makes the story inspiring is the initiative the owner showed: he used AI to teach himself about how a personalized vaccine could work, designed much of the process himself and approached top researchers to take it forward. Whether the treatment itself was fully curative and how much of an improvement it is over state-of-the art is not the main focus of this essay. Others have already debated that question at length, and I recommend following their discussions.
What interests me instead is the bureaucratic absurdity the dog’s owner encountered while trying to pursue the treatment. He described the long and frustrating process required simply to test the drug in his dog: “The red tape was actually harder than the vaccine creation, and I was trying to get an Australian ethics approval and run a dog trial on Rosie. It took me three months, putting two hours aside every single night, just typing the 100 page document.” Even in a small and urgent case, where the owner was fully willing to fund the treatment himself, the effort was slowed by layers of procedure.
Of course, this kind of red tape is not confined to Australia, nor to veterinary medicine. In fact, in the US, the red tape is even worse, at least for in-human trials. In a previous post, I recommended the Australian model for early stage
In the United States, GitLab co-founder Sid Sijbrandij found himself in a similar position after the relapse of his osteosarcoma. When the ordinary doors of medicine closed, he entered what he called “founder mode on his cancer.” Like many entrepreneurs confronted with a difficult problem, he began trying to build his own path forward by self-funding his exploration of experimental therapies.
Even then, he ran into the same maze of regulatory and institutional barriers that not only delayed him, but also unnecessarily raised the price of his experimental therapies. These are obstacles that only someone with extraordinary resources could hope to navigate, often by assembling an entire team to deal with them and navigate the opacity. In the end, Sijbrandij prevailed: he has been relapse free since 2025, after doctors had told me he was at the end of his options.
Around the same time, writer Jake Seliger faced a similar situation while battling advanced throat cancer. Like Sid Sijbrandij, he was willing to try anything that might help. The difference was that Seliger was not a billionaire. He could not hire a team to navigate the system on his behalf, and he struggled even to enroll in the clinical trials that might have offered him a chance.
A system originally conceived to safeguard patients has gradually produced a strange and troubling outcome: the mere chance of survival is effectively reserved for the very few who possess the means to assemble an army of experts capable of navigating its labyrinthine procedures.
What makes these stories particularly frustrating is that we already know clinical trials — especially small, early-stage ones like the ones Sijbrandij enrolled in for himself— can be conducted far more cheaply and with far less bureaucracy than is currently required. Ironically, the original article cites Australia as a bad example, yet clinical trials there are conducted 2.5–3× cheaper and faster than in the U.S., at least for human trials, without any increase in safety events—a genuine free lunch.
Removing unnecessary barriers has long been important. That is why I co-founded the Clinical Trial Abundance initiative in 2024, a policy effort aimed at increasing both the number and efficiency of in-human drug trials and have consistently argued about the importance of making this crucial but often neglected part of the drug discovery process more efficient.
Since then, the issue has only become more urgent with the rise of AI. One of the central promises of the AI revolution is that it will accelerate medical progress. Organizations such as the OpenAI Foundation list curing disease as a core goal, and researchers like Dario Amodei of Anthropic have argued that AI could dramatically speed up biomedical innovation. But, as I have written before in response to an interview between Dario and Dwarkesh Patel, AI will not automatically accelerate a key bottleneck in making these dreams a reality: clinical trials. Conyngham’s observation that navigating the red tape to start a trial for his dog took longer than designing the drug itself only underscores the point.
Clinical trials themselves vary widely. At one end are small, bespoke trials involving one or a few patients testing highly experimental therapies—like the treatment in the Australian dog story or the experimental therapy Sijbrandij pursued. At the other end are large-scale trials involving thousands of participants, designed to confirm earlier findings and support regulatory approval.
Different types of trials require different reforms. In this essay, I will focus on the former: small, exploratory trials, which will be called early-stage small n trials for the purpose of this essay. These are often the fastest way to test promising ideas in humans and learn from them. They represent our best chance at a meaningful “right-to-try,” form the top of the funnel that generates proof-of-concept evidence, and may be the only viable path for personalized medicine and treatments for ultra-rare diseases. Understanding why these trials have been made unnecessarily difficult—and how we might change that—is essential if medical innovation is to keep pace with our growing ability to design new therapies.
When the story first circulated on X, many people interpreted it as evidence that a cure already exists but simply hasn’t been used due to bureaucracy. That isn’t quite true, as I explained.
The type of mRNA vaccine that the owner pursued looks promising, but he did not know a priori whether it worked or not, as it had not been tested before. So it was not a cure, but “a chance at a cure”. I hesitate to call it an “experimental treatment”, since this term evokes fears of potential safety issues while we generally can predict safety quite well now. The inaccuracy of whether this was a cure or not, however, does not make the story of the bureaucratic red tape that Conyngham encountered any less infuriating. More and more promising treatments are accumulating in the pipeline, fueled by an explosion of new therapeutic modalities, ranging from mRNA to better peptides and more recently, by AI. Yet we are not taking full advantage of them.
To better understand these points, it is helpful to briefly outline the clinical development process—the sequence of in-human trials through which a promising scientific idea is gradually translated into a therapy.
Drug development is often described as a funnel: many ideas enter at the top, but only a few become approved treatments. Early human studies, known as Phase I trials, sit at the entrance of this process. They involve small numbers of patients and are designed to quickly test whether a new therapy is safe and shows early signs of effectiveness.
If the results look promising, the therapy moves to larger and more complex studies, including Phase III trials that enroll large numbers of patients to confirm whether the treatment truly works. Most people gain access to new therapies only after these large randomized trials are completed.
On average, moving from a promising idea to Phase III results takes seven to ten years and costs roughly $1.2 billion. Accelerated approval pathways in areas such as cancer or rare diseases can shorten this timeline by relying on surrogate endpoints, but the process remains slow. As a result, many discoveries that make headlines today will take close to a decade before they become treatments that patients can widely access.
Part of this delay is unavoidable. Observing how a drug affects the human body simply takes time. But much of it is not. Layers of unnecessary bureaucracy, regulatory opacity, and rising trial costs add years to the process without clearly improving patient safety, which is why I started Clinical Trial Abundance.
Allowing a higher volume of small-n early stage trials, the focus of this essay, is a rare “win-win” for both public health and scientific progress. For patients, it transforms a terminal diagnosis from a closed door into a “chance at a cure,” providing legal, supervised access to cutting-edge medicine that currently sits idle in labs. For researchers and society, it unclogs the drug discovery funnel; by lowering the barrier to entry for new ideas, we ensure that the next generation of mRNA, peptide and AI-driven therapies are tested in humans years sooner, ultimately accelerating the arrival of universal cures for everyone.
Next, I will explain why making it easier to run these early stage trials matters.
First, from a patient perspective, they often provide the closest practical equivalent to a right-to-try. In theory, right-to-try laws allow patients with serious illnesses to access treatments that have not yet been confirmed in large randomized Phase III trials. In practice, these pathways rarely function as intended. Pharmaceutical companies are often reluctant to provide experimental drugs outside formal trials, and treatments typically must have already passed Phase I testing. As a result, very few patients gain access through these mechanisms. Early-stage trials offer a more workable alternative. They allow experimental therapies to be tested in structured clinical environments—often in academic settings or academia–industry collaborations—where patients can be monitored and meaningful data can be collected.
Second, early-stage small-n trials are essential for personalized medicine and the treatment of ultra-rare diseases. Many emerging therapies—such as personalized cancer vaccines, gene therapies, and other individualized interventions—do not fit easily into the traditional model of large randomized trials involving thousands of participants. By their nature, these treatments target very small patient populations and often require flexible, adaptive clinical designs.
From a societal perspective, these trials play a crucial learning role. As I argued in my earlier essay Clinic-in-the-Loop, early-stage trials are not simply regulatory checkpoints on the path to approval. They are part of the discovery process itself, creating a feedback loop between laboratory hypotheses and human biology. Later-stage studies, particularly Phase III trials, are designed mainly for validation: they test whether a treatment works under defined conditions and produce the evidence needed for approval.
Early-stage trials, by contrast, are oriented toward learning. Conducted with small patient groups and often using exploratory designs, they allow researchers to observe how a therapy behaves in the human body and how the disease responds. In this way, they close the gap between theory and real-world biology. In the Clinic-in-the-Loop essay, I explain how these trials were crucial to the discovery of Kymriah, the first curative cell therapy for blood cancer."
My take on the whole "AI cures cancer in dog in Australia". It's a very interesting story, but perhaps not for the reasons that are being noted.
In 2007, Freeman Dyson published an essay in The New York Review of Books called “Our Biotech Future.” It contains one of the most memorable predictions about the future of biology I’ve ever read.
“I predict that the domestication of biotechnology will dominate our lives during the next fifty years at least as much as the domestication of computers has dominated our lives during the previous fifty years.”
Dyson believed biology would eventually follow the trajectory of computing. At first, powerful tools live inside large institutions - universities, government labs, major companies. Over time those tools get cheaper, easier to use, and more widely distributed.
Eventually individuals start doing things that once required entire organizations.
“Biotechnology will become small and domesticated rather than big and centralized.”
He even imagined genome design becoming something almost artistic:
“Designing genomes will be a personal thing, a new art form as creative as painting or sculpture.”
Dyson's words rang in my mind as I read the "AI cures dog cancer" story. Much of the coverage framed this as an example of AI discovering new science. But that’s not really the interesting part of the story.
The scientific pipeline involved here is actually well known. It closely mirrors the workflow used in personalized neoantigen vaccine research that has been under active development for years. The steps are fairly standard: sequence the tumor, identify somatic mutations, predict which mutated peptides might be recognized by the immune system, encode those sequences in an mRNA construct, and deliver them to stimulate an immune response.
The biological targets themselves were almost certainly not new discoveries (I have been unable to find out what they are, but mutations in targets like KIT which are common might be involved). Partly therein lies the rub, since the hardest part of drug discovery, whether in humans or dogs, is target validation, the lack of which leads to lack of efficacy - the #1 reason for drug failure. In neoantigen vaccines, the proteins involved are usually ordinary cellular proteins that happen to contain tumor-specific mutations. AlphaFold which was used to map the mutations on to specific protein structures is now a standard part of drug discovery pipelines. The challenge is identifying which mutated peptides might plausibly trigger immunity. What is interesting though is how the pipeline was assembled.
Normally, this type of workflow spans multiple domains - genomics, bioinformatics, immunology, and translational medicine - and in institutional settings those pieces are distributed across specialized teams, document sources and legal and technical barriers. Navigating the literature, selecting computational tools, interpreting sequencing results, and designing a candidate mRNA construct is typically a collaborative process. In this case, AI appears to have helped compress that process, pulling together data and tools from different sources. Instead of requiring multiple experts, a motivated individual was able to assemble the workflow with AI acting as a kind of guide through the technical landscape.
I’ve seen something similar in my own work while building lead-optimization pipelines in drug discovery. The underlying science hasn’t changed, but the friction involved in assembling the workflow can drop dramatically. Tasks that once required stitching together multiple tools, papers, and areas of expertise can now often be executed much faster with AI helping navigate the terrain; and by faster I mean roughly 100x. That kind of workflow compression is powerful, to say the least. When the cost of navigating technical knowledge drops, more people can realistically assemble sophisticated research pipelines. This story is a great example of what naively seems like a boring quantitative acceleration of the research process.
In that sense, therefore, the real novelty here is not the biology but the combination of three things: a non-specialist orchestrating a complex biomedical pipeline, AI acting as a navigational layer across multiple technical domains, and the resulting decentralization of capabilities that were once confined to institutional research environments. But I think the story also points to something deeper, which is a challenge to modern regulatory environments. Modern biomedical innovation does not operate solely according to what is scientifically possible. It is structured by regulatory frameworks - clinical trials, safety oversight, institutional review boards, and regulatory agencies. Those systems exist for important reasons, but they also assume that the development of therapies occurs primarily within large, regulated organizations.
When individuals begin assembling pieces of these pipelines outside those institutions, the relationship between technological capability and regulatory oversight starts to shift. The dog in this story sits outside the human regulatory framework. That fact alone made the experiment possible. In other words, the story is not just about technological capability; it is also about how certain forms of experimentation can occur when they bypass the regulatory pathways that normally govern biomedical innovation. One is reminded of another Australian, Barry Marshall, who received a Nobel for demonstrating through self-experimentation that ulcers are caused by bacteria.
This raises an interesting question: what happens when the tools for assembling sophisticated biological workflows become widely accessible while the regulatory structures governing them remain institution-centric? That tension may ultimately be the most important implication of this moment. Regulatory frameworks will need to adapt to this kind of citizen science. Seen in this light, the story about the AI-assisted vaccine is less about a breakthrough in cancer therapy and more about a glimpse of the early stages of something Dyson anticipated nearly two decades ago: the domestication of biotechnology.
If AI continues to reduce the cognitive overhead required to navigate biological knowledge and assemble complex pipelines, the boundary between professional research and motivated individuals may begin to blur. That shift will require careful thinking about safety, governance, and responsibility. But it also carries an exciting possibility. Dyson imagined a world in which biological design might eventually become something like a creative craft practiced not only by institutions but also by curious individuals experimenting at smaller scales. For a long time that vision felt distant. Now, it feels like we may be seeing the first hints of it.
Deeply grateful to present my PhD work @JoeEcker lab is out at @CellCellPress!
🧠What drives brain aging? We used single-cell multi-omics to map methylation, 3D genome organization, and spatial transcriptomics across the aging mouse brain — uncovering transposon activation, TAD remodeling, and spatial heterogeneity. Plus AI models predicting transcriptomic changes from epigenetic data.
link: https://t.co/84TX1S3YiE