Finally sharing—Our Distribution Edited Model paper received an award at EMNLP '24 & was featured on @AmazonScience blog!
https://t.co/czHzKXL2UG
Big shoutout to Dhananjay Ram, @AdityaRawaI, @momcilh—plus all who shaped the effort.
#DL#LLMs#EMNLP
Do LLMs' reasoning abilities come from training on code🤔? Many think so, but how does this hold across languages🌐?
We study the interplay of code and reasoning in our recent work (#acl2024).
📃https://t.co/gtuS1g2N2e
🗃️https://t.co/SYMlliXnuG
1/6 🧵
DeAL
Decoding-time Alignment for Large Language Models
paper page: https://t.co/6ena1OiOcI
Large Language Models (LLMs) are nowadays expected to generate content aligned with human preferences. Current work focuses on alignment at model training time, through techniques such as Reinforcement Learning with Human Feedback (RLHF). However, it is unclear if such methods are an effective choice to teach alignment objectives to the model. First, the inability to incorporate multiple, custom rewards and reliance on a model developer's view of universal and static principles are key limitations. Second, the residual gaps in model training and the reliability of such approaches are also questionable (e.g. susceptibility to jail-breaking even after safety training). To address these, we propose DeAL, a framework that allows the user to customize reward functions and enables Decoding-time Alignment of LLMs (DeAL). At its core, we view decoding as a heuristic-guided search process and facilitate the use of a wide variety of alignment objectives. Our experiments with programmatic constraints such as keyword and length constraints (studied widely in the pre-LLM era) and abstract objectives such as harmlessness and helpfulness (proposed in the post-LLM era) show that we can DeAL with fine-grained trade-offs, improve adherence to alignment objectives, and address residual gaps in LLMs. Lastly, while DeAL can be effectively paired with RLHF and prompting techniques, its generality makes decoding slower, an optimization we leave for future work.
excited to finally release Mamba-2!! 8x larger states, 50% faster training, and even more S's 🐍🐍
Mamba-2 aims to advance the theory of sequence models, developing a framework of connections between SSMs and (linear) attention that we call state space duality (SSD)
w/@tri_dao
Our 2020 paper "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention" with @angeloskath@apoorv2904 and @nik0spapp reached 1000 citations!
https://t.co/ZLBrR3FX6k
Today we are excited to announce a new partnership with @awscloud! 🔥
Together, we will accelerate the availability of open-source machine learning 🤝
Read the post 👉 https://t.co/fb77d1J2qX
Updating ML models can introduce unseen errors, such as a virtual assistant 🤖 suddenly not understanding your often used command. How to avoid this?
✨
Backward Compatibility During Data Updates by Weight Interpolation
✨
📜 https://t.co/MX3ug3I7ph
⌨️ https://t.co/5y973CupOM
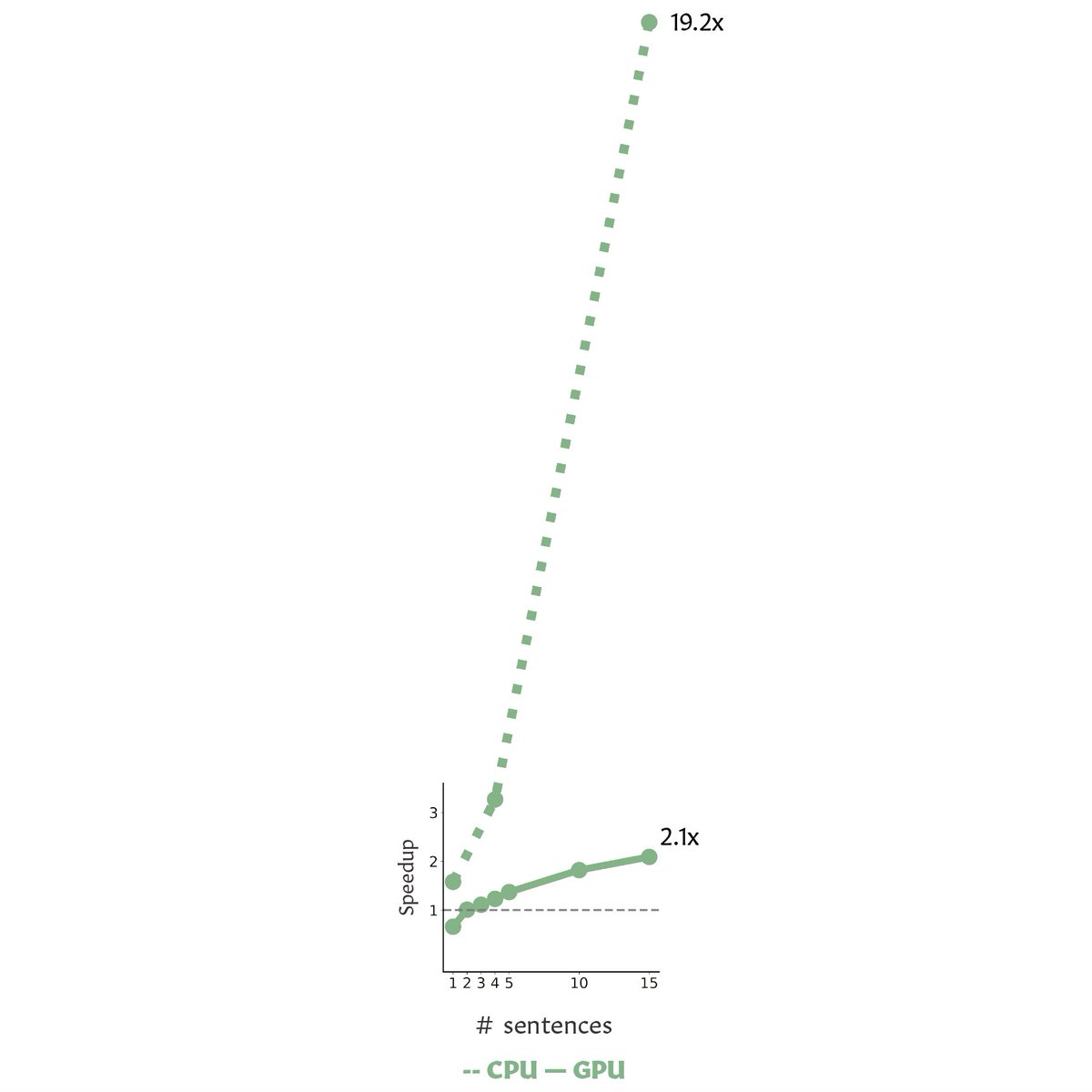
Linear-complexity models are cool, but shouldn't they work best on loooong documents? We tried RFA on doc-level translation, and got >2x speedup with memory savings, >7x when memory is controlled, and >19x on CPU. Similar/better BLEU; some consistency scores are slightly hurt 1/2
We also found that adding a gate to control information flow helps, which can be easily done with the RFA formulation.
#emnlp2022 findings. Come check us out in the @SustaiNLP2022 workshop on Wednesday! With @haopeng_nlp @nik0spapp@nlpnoah https://t.co/1kAi3Upkzp 2/2
I am looking for PhD students to join my lab @UMRobotics@UMich in Fall 2023! You'll already find my name on the #robotics dept/application website. Deadline is Dec 1, GRE not required, and there are application fee waivers!
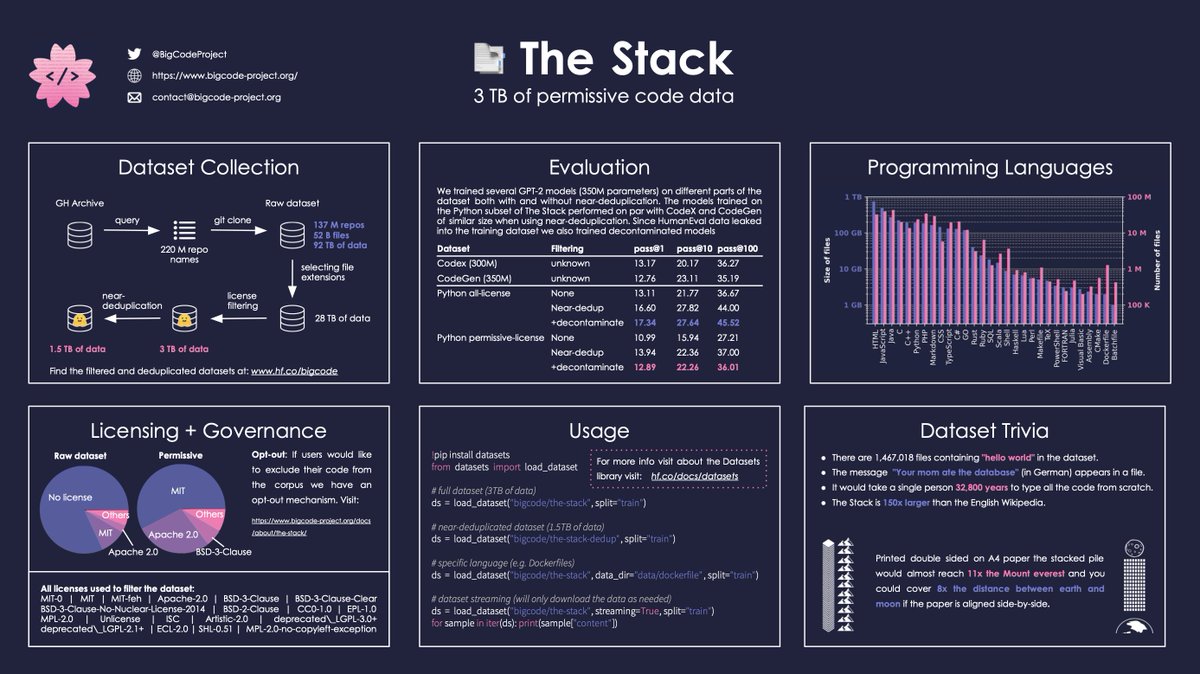
Introducing 📑 The Stack - a 3TB dataset of permissively licensed code in 30 programming languages.
https://t.co/xA8hNHQFm5
You want your code excluded from the model training? There is an opt-out form and data governance plan:
https://t.co/YiTWxwvXzO
Let's take a tour🧵
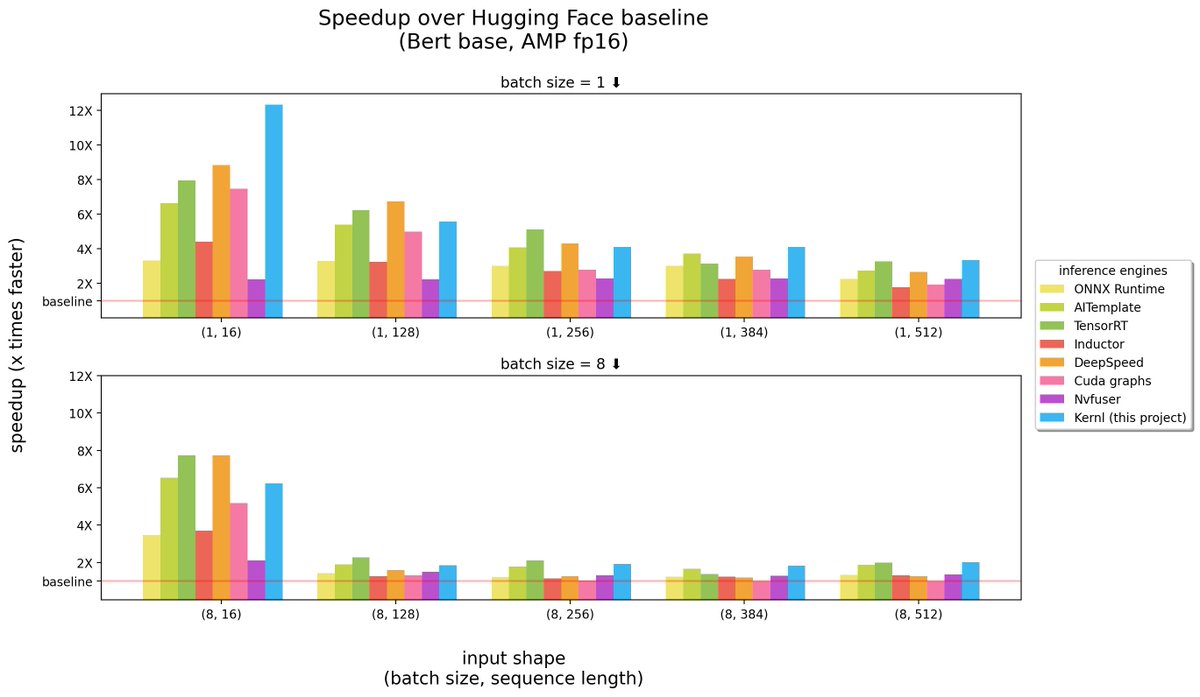
12X faster transformer model, possible?
Yes, with @OpenAI Triton kernels!
We release Kernl, a lib to speedup inference of transformer models. It's very fast (sometimes SOTA), 1 LoC to use, and hackable to match most transformer architectures.
https://t.co/xFK4Yom3gL
🧵
It's a joke that all NLP talks must include this graph.
But if you are a student it is a bit intimidating. How can you become an expert in where we are going if you can barely run BERT?
I asked twitter for specific advice that you might focus on:
Paper accepted to @NeurIPSConf 🎉
Big credit goes to @deng_cai who led the work during his internship at @awscloud and special acknowledgment to my collaborators!
You can check out the arXiv pre-print in the meantime https://t.co/cMB03WdWuY
We release the public beta for bnb-int8🟪 for all @huggingface 🤗models, which allows for Int8 inference without performance degradation up to scales of 176B params 📈. You can run OPT-175B/BLOOM-176B easily on a single machine 🖥️. You can try it here: https://t.co/TxnXxMWeaN
1/n
Can’t wait to attend #NAACL2022 with Lex AWS AI and meet colleagues in person next week. If you are into efficiency, out-of-domain generalization and calibration/robustness topics, let’s chat!
A great number of recent methods successfully scale attention in transformers to long sequences but conceptually grouping them can be daunting. How can we view them in a unified way? (1/5)
This raises the question: can we also learn a contextualized control strategy? The answer is yes! To learn more about it and how Linformer can be applied in autoregressive settings watch the talk by the amazing Hao Peng (@haopeng01) at #ACL2022: https://t.co/Ob6YMKJ8Qr (4/5)