In 2021 we identified GZMK+ CD8 T cells as Taa - age-associated subset of cells in mice. How they developed remained unclear.
Today, our latest work on the mechanism of development of age-associated GZMK+ CD8 Taa cells in old mice is now out!
https://t.co/4D2FsdxeOL
"Inflammaging in aged tissues drives remodeling of the CD8+ T cell compartment" let by Irina Shchukina and co-supervised by Gwendalyn Randolph with a huge team that helped to make it happen.
We definitively show that:
1. GZMK+ Taa cell development is cell extrinsic and requires antigen exposure in aged tissues.
2. We introduce major new model that accelerates immune aging in CD8 T cells and show that low-grade inflammation accelerates CD8+ T cell aging and Taa cell accumulation.
3. Aged adipose tissue acts as a niche that supports progenitor Taa cells and overall development of these cells.
#aging#rejuvenation#outlook#Community@NatureAging just published a very nice piece describing the view on the field of aging from ~30 experts in the field, humbly yours including:
https://t.co/MvSVJvguaE
In addition to reading the key messages that were nicely assembled by Sebastien Thuault and Hannah Walters, i strongly recommend to read supplementary material to that article, where each of the authors more extensively asnwers to these 10 questions - it is incredible source for discussions, debates and raw insights:
1. Is there one advance in aging or age-related disease research from the past 5 to 10 years that changed how you think about the field, and why?
2. What have we learned about translating geroscience from model organisms to humans, and where do the biggest gaps remain?
3. The field of aging is very broad, covering biology, clinical, public health and social sciences. Has your work or thinking been inspired by approaches or findings from separate disciplines?
4. Which single shared resource (e.g. dataset, biobank, model, tool) would most accelerate progress in your field?
5. How should we balance large, collaborative team science efforts and the focus and agility of individual labs to drive research forward? Should there be more big-team science in aging research?
6. Where do you see research on aging and age-related diseases having the biggest impact on clinical care and public health now and in the future?
7. If you could change one funding or regulatory policy to speed up progress, what would it be and why?
8. There is growing public interest in aging and age-related disease research. What can researchers do to ensure that aging science can be trusted and benefits everyone?
9. What advice would you give to researchers entering the field now?
10. Where do you see your field heading in the next 5 to 10 years?
Very excited to announce our latest paper in Nucleic Acids Research: "Accurate chromatin marks peak calling with Omnipeak." NAR Nucleic Acids Research lead by Oleg Shpynov
https://t.co/NgIWcK24l6
For years, we all have been forced to swap between different tools depending on their data: MACS2 for sharp peaks or SICER for broad domains. Furthermore, the same methods could give vastly different numbers of peaks for the same mark when the quality varies a bit.
Omnipeak changes the game:
✅Unlike MACS2, which struggles with broad histone modifications, Omnipeak captures the full architecture of the epigenome—from razor-sharp H3K4me3 peaks to expansive H3K27me3 domains—within a single framework.
✅ Better Biological Signal: Our method demonstrates higher consistency across biological replicates, ensuring that the "peaks" you find are real biological features, not technical noise.
✅ Superior Boundary Precision: In our benchmarking against ENCODE and Roadmap datasets, Omnipeak consistently outperformed existing methods in defining exact peak start/end coordinates.
✅ Consistency at a low-quality peak calling and no dependency on the control samples. This also provides unique systematic approach for any large-scale epigenetic analysis of many studies and samples.
Stop juggling multiple pipelines. Switch to a universal, unsupervised solution that brings mathematical rigor to your ChIP-seq and ATAC-seq analysis.
8/ Overall, this work provides a practical framework for performing non-additive GWAS at biobank scale. This approach enables the identification of novel associations - like the 781 loci found here - that additive models alone may miss
1/ New in @NatureComms: A scalable method for non-additive GWAS reduces computational cost 700-fold and uncovers 781 novel disease loci in @FinnGen_FI . Led by @ivan_molotkov_ , this work opens large-scale dominant/recessive analysis for large biobanks.
https://t.co/0o8QhcbJc1
7/ Novel loci were replicated in the Million Veteran Program, fine-mapped, and colocalized with 571 datasets. Together with evidence from prior TWAS and RVAS, this analyses revealed potential biological mechanism behind identified likely causal variants
Very happy to see cover on Nov 11 @ImmunityCP issue highlighting our review on Human Immune Aging (https://t.co/vCU0OTzID6). One of key visuals highlights major finding made by Terekhova et al in Immunity, 2023 - systematic shift toward type 2 (Th2/Tc2) immunity in healthy aging!
(https://t.co/MnefUu7v6W)
Just out - our major review piece @ImmunityCP , summarizing couple of decades of the research on human immune aging and providing highlights of the latest advances in the field. Led by Marina Terekhova, truly encyclopedic depth (327 references)
https://t.co/4SenJ8VTOj
#ashg2025 . Recessive and dominant GWAS provides extra power to uncover genetic associations missed by additive GWAS. Costs associated with running the additional analysis steps were the main limitation to bulk non-additive GWAS across biobanks. Come see the talk by @ivan_molotkov_ at ASHG - 10/15 at 10.45am that presents our solution - fast and cheap filtration strategy that retains > 90% of true positive non-additive associations.
Does it work?
We applied this to >2,000 traits in @FinnGen_FI , identified > 800 novel loci, including for the phenotypes that lacked any GWAS signals before.
Importantly, we have spent only $30 in computational costs to run this analysis!!!
Want to add non-additive GWAS to your study for virtually no-effort and no-cost? Come see how to do this.
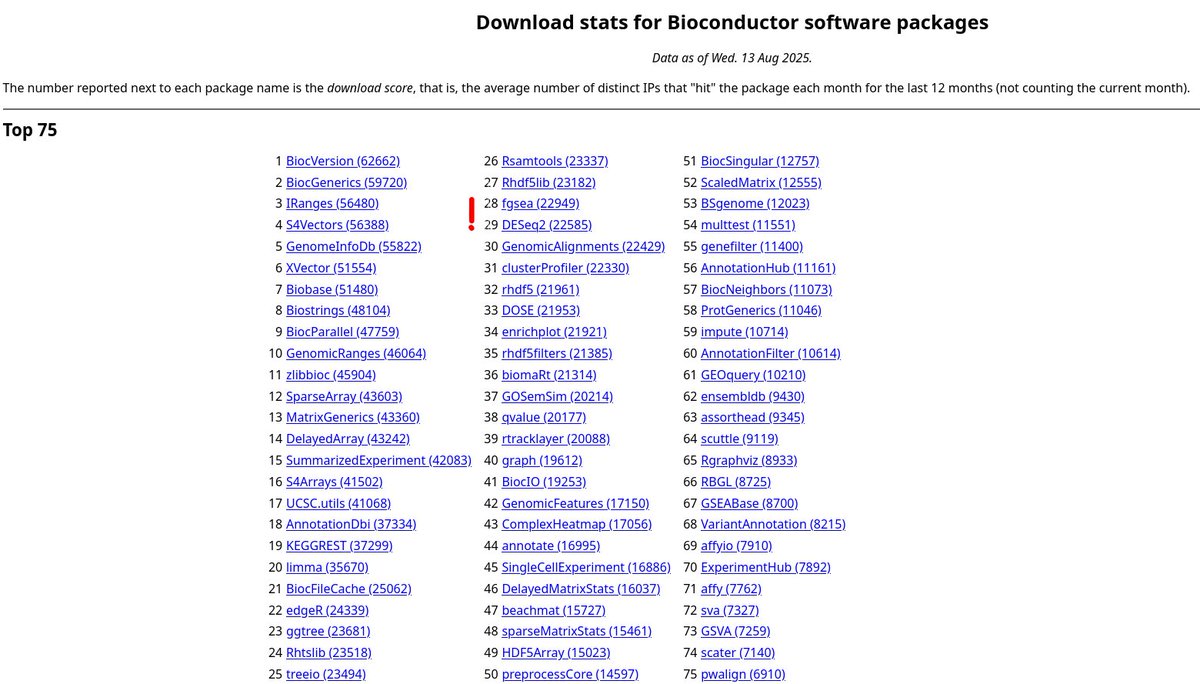
Important milestone for me and my lab: fgsea has passed DESeq2 on the list of most downloaded Bioconductor packages. It started as a side project during my PhD, back when DESeq2 was already a staple of RNA-seq analysis. I never even thought it could go this far—but here we are!
#aging#immune_aging
NEW PREPRINT FROM Artyomov&Randolph labs:
How mouse age-associated GZMK+ CD8 Taa cells develop and what are correct surface markers for them
https://t.co/hO0ErccQ51
Among other things we
- Using OT1-Rag2ko mice explicitly show the TCR dependence and yet non-lymphoid origin of these cells(!)
- introduce new genetic model of chronic very low level inflammation that shows the accelerated immune aging in CD8 T cells (dedicated TNFdelta69 deletion generated in Gwen’s Randolph lab).
- find surface marker of the GZMK+ CD8 T cells using newly generated scRNA-seq dataset – in fact these Taa cells are PD1+CD226- CD8 T cells
- find that adipose tissue is one of the key peripheral sites of expansion of Taa cells
- use heterochronic organ transplant of lungs and adipose tissues to prove that it is adipose tissues that drive this development
Read it now, and send us your comments, we are happy to expand and collaborate on these!
We have rolled out an updated interface and functionality for the SCoRe shared control repository to simplify selection of external ancestry-matched controls and provide some usage examples (https://t.co/ohYIzD9quD).
Key new features:
- AlphaMissense and SNPred filters for missense variant pathogenicity to apply to the variants in matched control dataset
- Interactive selection of variant annotations for analysis
- More detailed variant and gene-based output of allele counts from matched control cohort.
- Updated and detailed tutorial, showing the approach to variant annotation, preparation of local genetic data (check out the binary file data storage!), rare-variant association testing.
PGS browser offers some solutions that help to facilitate practical applications:
-Describing the differences in individual PGS risk estimates resulting from different PGS methods highlighting possible variability in risk prediction across studies
- showing improvement of disease prediction with combination of PGSs
- demonstrating the value of "non-target" PGSs for disease prediction
- providing secure access to large reference population to interpret PGS scores. The PGS distributions that we released are ancestry-adjusted, which significantly simplifies application to different populations.
In our new study we evaluated 3,000+ polygenic risk scores in nearly 500,000 @FinnGen participants. See PGS performance metric, multi-PGS models, PGS-PheWAS and personalized predictive models within #PGSBrowser: https://t.co/VnIUNXbWe0 and the preprint at https://t.co/IEPjVz8H9C
If you are attending #ICED2025 in San Antonio, check out the talk by Sarah Snyder, describing our clinical study of Anorexia and Atypical Anorexia Nervosa - May 30, 4:15pm CT - Neurobiology and Genetics II session