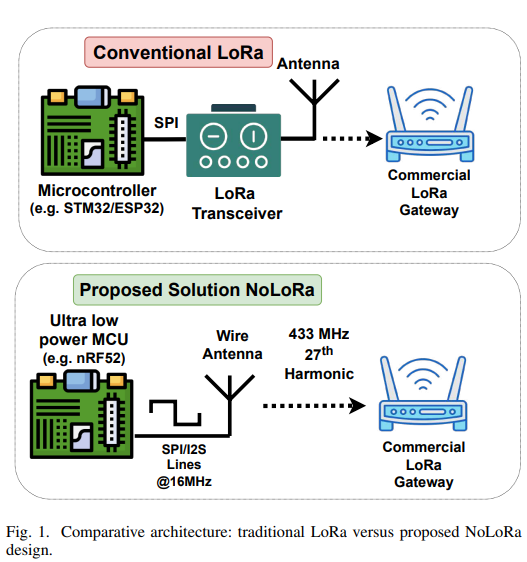
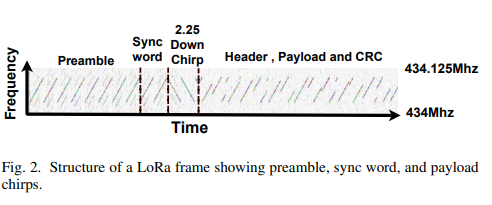
Trust is a necessary component of human existence. It can give us peace of mind but It can also give us broken hearts. The same is true in the context of system design. Trust cautiously.
World Labs CEO Dr. Fei-Fei Li: "The world is not made of words."
"Language models have given machines an extraordinary command of concepts, vocabulary, and reasoning, but the physical world, virtual or real, runs on a different substrate."
"Where language models learn the statistical structure of text, world models learn the statistical structure of space and time: how light falls on a surface, how a garden looks from an angle no camera has captured, how objects respond to force and follow the laws of physics."
"Language gave machines a way to talk about that world. World models are how machines will finally come to understand, imagine, reason and interact with it."
Full piece: https://t.co/C9qOJg5wuc
And FWIW now I have a bare metal go, FIPS 140-3 level 3, CC EAL 6+, Bare Metal Go, ACME CA (ABAC based on Cedar) that does PQ and classical certificates (PQ is not in the SE), that issues x509 and SSH, with device key attestation from the client (think TPMs), and environment attestation (think TDX/SEV/Trustzone/Nitro) and CA key attestation (NXP SE050). I’ve also defined a posture ACME challenge (os version, firewall state, etc) all working on this magical little device. :)
I put together a short spec for Codex to take a working Linux image I have running on a USB Armory, containing exclusively Go code, and use TamaGo to create a bare-metal image of the codebase. I woke up the next day to find an incomplete and poorly designed TCP/IP stack added as part of the codebase. I apparently forgot to add "Do not recreate the missing operating system until the code compiles."
Welp, that happened faster than I predicted. Thought it would be end of 2027, then early 2027, but agentic traffic growing so fast that bots have now passed human traffic online for the first time in the Internet's history. https://t.co/2zX5bHdhsa
Why textualism, original public meaning, and AI governance all turn on the same uncomfortable fact: intent does not travel unless it becomes part of the record.
https://t.co/3zxEtcwNec
🚨 Google Quantum result was just rediscovered and IMPROVED!
On March 31, 2026, Google Quantum AI published a paper showing that 256-bit ECDLP, the hard problem behind ECDSA and therefore behind Bitcoin, Ethereum, TLS, and most of the world's authentication, can be solved with fewer than 1,200 logical qubits and ~90M Toffoli gates. Under 20 minutes on ~500,000 physical qubits.
BUT, they didn't publish the circuits. They published a zero-knowledge proof that the circuits hit those numbers. The standard read at the time: clever responsible disclosure, elegant.
Two months later, that read needs an update. Two things happened, in opposite directions.
1. The ZKP wasn't a stylistic choice. Google was stopped from publishing.
What was speculation in April is no longer. Google did not choose to keep the circuits private. The U.S. government prevented publication. The blog post phrased it politely ("we engaged with the U.S. government"). Call it what it is: diplomatic cover for a publication block.
This is the line Scott Aaronson warned about. At some point, the people estimating the resources needed to break deployed cryptosystems would stop publishing. We just watched it happen, and the actor enforcing the silence isn't Google's PR team. It's a government.
2. The ZKP turned out to be a reward function. AI used it.
Here's the part that's almost funny.
A ZK proof that "this hidden circuit achieves these resource counts" is, when you flip it, a public verifier of any candidate circuit. Submit a circuit, get back: does it compute ECC point addition correctly, and at what cost. Pass/fail plus a number. That is exactly the shape of a reinforcement-learning reward function.
The ZKP was designed to hide the attack. What it actually published is the reward function for rediscovering it.
The research community wired the verifier into an automated AI-driven search loop. They reproduced Google's numbers. Then they improved them by 11.5%. Two months, from outside Google, no access to the circuits, using the very artifact Google released to keep them proprietary.
Both of these are true at once. Hiding the circuits worked: nobody outside Google has Google's exact circuits. And hiding the circuits did not slow the frontier; it changed who is doing the search, and arguably accelerated it, because the verifier industrialized the search loop.
Let's NOT PANIC!
Neither of these is a working CRQC. There is still no quantum computer that can run this circuit. The headline state of the world has not changed.
What has changed is the honesty of every public PQC timeline. Cryptography exists to create mathematical trust in the security of systems. Trust isn't broken when an attack runs. It is eroded when the foundation looks thinner than the public record suggests, and the public record is now demonstrably thinner than reality in two ways: by classification on one end, by AI-driven re-derivation on the other.
In security, the moment you start doubting the foundation is the moment you start rebuilding it. Not the moment you panic. The moment you plan.
This isn't a moment to rush. It's a moment to commit to a migration plan and execute against it, knowing the threat model is shaped by what governments are willing to classify, not by what researchers are allowed to publish.
Stay safe. Stay honest about your trust assumptions.
Imagine replacing 90% of your employees with a team of geniuses who have no idea how your company operates.
Total chaos. Nothing works.
That’s what AI feels like today.
The missing piece is extracting all the domain knowledge from people’s heads and providing that as structured context to the models.
It's a gorgeous and funny bug.
Fwiw, I'm the biggest eBPF fanatic, but I don't think unprivileged users should be able to load arbitrary eBPF programs.
The app layer couldn’t get a better advertisement than a company spending $500M to build their own version of it. Obviously lots of nuance here that can’t be captured in the headline, but this should make you very bullish on software.
CortexMAE, our fMRI foundation model preprint is out (accepted to ICML)!
we trained an image foundation model on flat map brain scans instead of natural images
i believe this is the way forward to extract the most signal from fMRI, whereas traditional preprocessing just treats each brain independently, our method processes scans within broader context of the population
several labs have tried out the idea, but we think they've all been too optimistic and their papers don't share the code / preprocessing / data splits to make direct comparison possible
so we combine this release with Brainmarks, an open-source fMRI FM evaluation suite spanning several different tasks (e.g., clinical diagnosis, image decoding) and supporting 7 different FMs (including CortexMAE) for reproducible direct comparisons of models
takeaway is that our model does best (particularly for cross-subject dynamic state decoding), but simple non-FM baselines perform very close; we also see our model scales according to strict power law (but is currently data limited)
CortexMAE & Brainmarks are fully open-source, we share code & model weights & our data downloading steps
we are now extending this work to structural + functional MRI and participating in the FOMO26 challenge—join our MedARC discord to help us develop our next models!
also welcome to chatting with any partners who could help us scale up our FM to become more clinically relevant! We want to run pilots and prove the utility of this approach to predict treatment response + neurodegenerative disorder progression
Kirkland & Ellis, the world's highest-grossing law firm, is setting aside $500M to build its own AI platform rather than rely on tools available to its rivals (Financial Times)
(Visit Techmeme dot com for the link and full context!)
Today we're bringing Cua Driver to Windows: background computer-use for any agent. Claude Code, Codex, or your own loop can drive real Windows apps through CLI or MCP while your desktop stays usable, with true multi synthetic pointer support.
1/6
Compliance is painful, bureaucratic, and often paper-based, so it has long persisted as being manual and human intensive.
That friction has historically made compliance a graveyard for startups.
But AI may finally go from "good enough to pilot" to "good enough to trust".
In legal, broad model choice and consistently high accuracy gave teams the confidence to finally embrace AI. Many LLMs now score 80-100% on LegalBench’s 162 legal reasoning tasks.
This matters directly for compliance, because compliance is essentially applied legal reasoning under operational constraints, built on the same core tasks: reading regulatory text, applying rules to fact patterns, identifying exceptions, and flagging ambiguities.
Full piece from a16z's @jamdac and @astrange: https://t.co/niRB3jPioN