One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
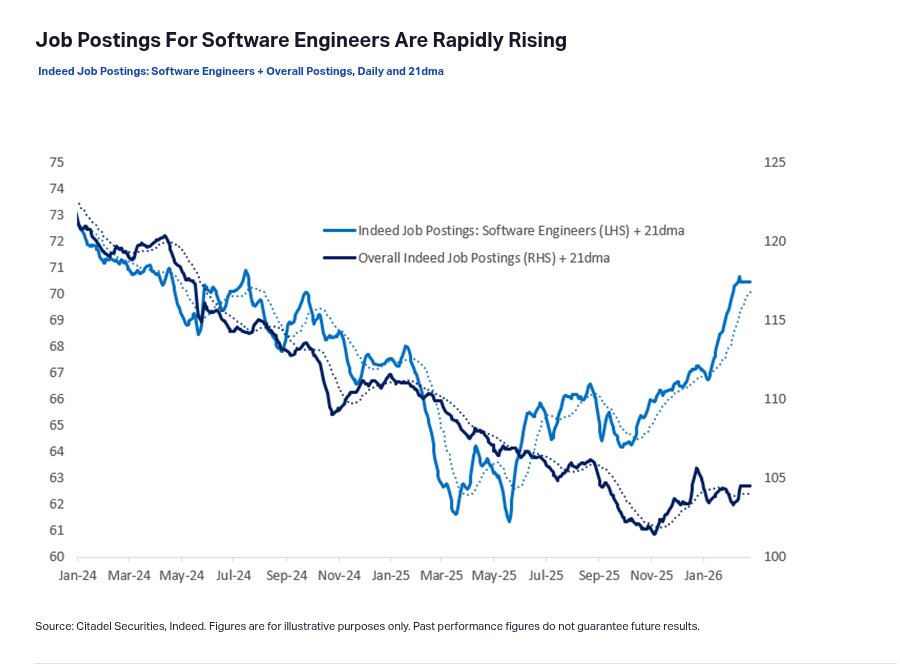
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
I'm biased, but this is the beginning of a headless future. These same capabilities work outside Salesforce too. Inside Claude, Slack, ChatGPT, Teams, anywhere your people work.
SaaS is changing. You don't have to click through all your apps and tabs anymore. The apps comes to you through the agent wherever you work. The human is no longer the integration layer between apps. Humans direct. Agents execute, the platform governs.
This is just the beginning.
There is no substitute for bestie @DavidSacks … showed up black-shirted, caffeinated, & fully armed with enough crazy. Besties talked future of enterprise, AI agents that actually work (not just hype), and @chamath has enough truth China bombs to trigger all the Besties. Zero filter. Brilliant El Niño insight from @friedberg. I wasn’t ready for @Jason and neither was the group chat. Buckle up. This one’s XX spicy. 🌶️ 🚀 Check out the full episode here → https://t.co/VeqjCG0loE
Forward deployed engineers, or equivalent, are about to become one of the most in-demand jobs in tech. And one of the most important functions for AI rollouts.
Deploying agents is far more technical of a task than most people realize, often far more involved than deploying software. Software generally works the same way every time, and generally for the past few decades has been updated versions of an existing technology or concept (which basically means easier for the enterprise to update their workflows on a newer system).
With agents, you’re actually deploying the equivalent of work output within the enterprise. The customer is effectively using you as a professional services provider for a task, which they expect to get solved nearly end-to-end now. This means you need to actually deeply understand the business process as a vendor, and get the customer from the current to the end state seamlessly.
Companies need help figuring out which models will work best for their workflows, they need extensive evals setup often, they need change management support for workflows, they need to get their data setup for the agents, and constant tuning of the agentic system for their process.
Massive role in tech now. And another example of the kind of highly technical work that AI is creating.
As agents become the biggest users of software, then all software has to be available in a headless fashion. Agents won’t be using your UI, they’ll be talking to your APIs.
So the question becomes what is the business model of software and this headless approach in the future?
Here are a few thoughts on how everything plays out based on what we’re seeing and doing at Box, but also conversation with other platforms.
1) Seats don’t go away for *people*. Seats are still a convenient and efficient way to have a customer use technology predictably for a set of users within a baseline set of usage. The key, though, is that when the customer pays for a seat, it has to come with a set of usage of APIs on behalf of that user that the agent can use on their behalf.
The user will need to be able to interact with their data and the underlying tool via any agent they work with, and an embedded amount of usage will come with the seat. I would imagine most software -Box included- will enable seats to work with their data at a relatively high volume via systems like ChatGPT, Codex, Claude, Gemini, Cursor, Copilot, Perplexity, Factory, Cogniton, et al. quite seamlessly. If you don’t do this, you’re DOA.
2) Agents may have “seats” if they are doing stateful work in the system, but they will be priced very differently than people. Seats (or the equivalent) can make sense when you have an agent that has its own workspace, stores its own data, needs a different set of permissions compared to the user, and so on.
If a company wants this agent to be around for long period of time, that may very well look like another “user” in the system. Openclaw-style agents highlight what this future could look like.
The only issue on pricing here is that one customer could decide to do all their work in 1 agent, and another might split it into 1,000 agents. So pricing like a human seat is nearly impossible and impractical; each company will have a different approach for this as it gets tricky perfectly trying to capture all the value within an agent seat.
3) The dominant pricing for headless use that goes above the seat allotment, or when an agent is firmly acting on their own, will be a consumption model. Many enterprises software platforms have previously operated like this with PaaS options, and agents will look like another machine user of their system.
In some cases the APIs might get priced just as they did previously, but in other cases there may need to be new types of APIs that represent the work an agent would do in one go -more akin to an outcome- instead of a series of API calls. This is especially germane when the headless software also has an agentic use-case embedded within in, such as orchestrating the process within their own system via AI.
Overall the growth of this usage pattern is effectively unbounded as the use-cases for agents operating on data in these systems will dramatically exceed what people do with their data and tools today. Every platform that goes headless (which will be anyone that wants to take advantage of agents) will need to adopt a model like this. Some may fight it initially but it’s an inevitably as there will always be more and more agents outside your platform than people.
Overall, there’s a lot of really interesting changes left to come in software due to headless use of these systems. Early days.
We build a lot of things at @Salesforce. But this week, at #TDX26, I was reminded that the best thing we've ever built is our Trailblazer Community. It was so awesome seeing the joy on everyone's faces all week as they reconnected with each other, shared stories, learned about what's new at Salesforce, and danced at all the parties. @swbjoyce said it best: It's about the people.
I took delivery of a beautiful new shiny HW4 Tesla Model X today, so I immediately took it out for an FSD test drive, a bit like I used to do almost daily for 5 years. Basically... I'm amazed - it drives really, really well, smooth, confident, noticeably better than what I'm used to on HW3 (my previous car) and eons ahead of the version I remember driving up highway 280 on my first day at Tesla ~9 years ago, where I had to intervene every time the road mildly curved or sloped. (note this is v13, my car hasn't been offered the latest v14 yet)
On the highway, I felt like a passenger in some super high tech Maglev train pod - the car is locked in the center of the lane while I'm looking out from Model X's higher vantage point and its panoramic front window, listening to the (incredible) sound system, or chatting with Grok. On city streets, the car casually handled a number of tricky scenarios that I remember losing sleep over just a few years ago. It negotiated incoming cars in tight lanes, it gracefully went around construction and temporarily in-lane stationary cars, it correctly timed tricky left turns with incoming traffic from both sides, it gracefully gave way to the car that went out of order in the 4-way stop sign, it found a way to squeeze into a bumper to bumper traffic to make its turn, it overtook the bus that was loading passengers but still stopped for the stop sign that was blocked by the bus, and at the end of the route it circled around a parking lot, found a spot and... parked. Basically a flawless drive.
For context, I'm used to going out for a brief test drive around the neighborhood to return with 20 clips of things that could be improved. It's new for me to do just that and exactly like I used to, but come back with nothing. Perfect drive, no notes. I expect there's still more work for the team in the long march of 9s, but it's just so cool to see that we're beyond finding issues on any individual ~1 hour drive around the neighborhood, you actually have to go to the fleet and mine them. Back then, I processed the incredible promise of vehicle autonomy at scale (in the fully scaleable, vision only, end-to-end Tesla way) only intellectually, but now it is possible to feel it intuitively too if you just go out for a drive. Wait, of course surround video stream at 60Hz processed by a fully dedicated "driving brain" neural net will work, and it will be so much better and safer than a human driver. Did anyone else think otherwise?
I also watched @aelluswamy 's new ICCV25 talk last week (https://t.co/RdaM23kvez) that hints at some of the recent under the hood technical components driving this progress. Sensor streams (videos, maps, kinematics, audio, ...) over long contexts (e.g. ~30 seconds) go into a big neural net, steering/acceleration comes out, optionally with visualization auxiliary data. This is the dream of the complete Software 1.0 -> Software 2.0 re-write that scales fully with data streaming from millions of cars in the fleet and the compute capacity of your chip, not some engineer's clever new DoubleParkedCarHandler C++ abstraction with undefined test-time characteristics of memory and runtime. There's a lot more hints in the video on where things are going with the emerging "robotics+AI at scale stack". World reconstructors, world simulators "dreaming" dynamics, RL, all of these components general, foundational, neural net based, how the car is really just one kind of robot... are people getting this yet?
Huge congrats to the team - you're building magic objects of the future, you rock! And I love my car <3.
With Agentforce, humans & agents unite! Salesforce now delivers 24/7 global support in 7 languages—real-time AI+human chat translation with Agentforce + Service Cloud. 🌍
Try it: https://t.co/sR2Lbhnmsz
🔥 #Salesforce#Agentforce
i can't think of a non-cliche way to say this, but everyone who says having a kid is the best thing in the world is both correct and still somehow understating it.
Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly increase (/decrease) the probability of every action I took for the future". You get a lot more leverage from verifier functions than explicit supervision, this is great. But first, it looks suspicious asymptotically - once the tasks grow to be minutes/hours of interaction long, you're really going to do all that work just to learn a single scalar outcome at the very end, to directly weight the gradient? Beyond asymptotics and second, this doesn't feel like the human mechanism of improvement for majority of intelligence tasks. There's significantly more bits of supervision we extract per rollout via a review/reflect stage along the lines of "what went well? what didn't go so well? what should I try next time?" etc. and the lessons from this stage feel explicit, like a new string to be added to the system prompt for the future, optionally to be distilled into weights (/intuition) later a bit like sleep. In English, we say something becomes "second nature" via this process, and we're missing learning paradigms like this. The new Memory feature is maybe a primordial version of this in ChatGPT, though it is only used for customization not problem solving. Notice that there is no equivalent of this for e.g. Atari RL because there are no LLMs and no in-context learning in those domains.
Example algorithm: given a task, do a few rollouts, stuff them all into one context window (along with the reward in each case), use a meta-prompt to review/reflect on what went well or not to obtain string "lesson", to be added to system prompt (or more generally modify the current lessons database). Many blanks to fill in, many tweaks possible, not obvious.
Example of lesson: we know LLMs can't super easily see letters due to tokenization and can't super easily count inside the residual stream, hence 'r' in 'strawberry' being famously difficult. Claude system prompt had a "quick fix" patch - a string was added along the lines of "If the user asks you to count letters, first separate them by commas and increment an explicit counter each time and do the task like that". This string is the "lesson", explicitly instructing the model how to complete the counting task, except the question is how this might fall out from agentic practice, instead of it being hard-coded by an engineer, how can this be generalized, and how lessons can be distilled over time to not bloat context windows indefinitely.
TLDR: RL will lead to more gains because when done well, it is a lot more leveraged, bitter-lesson-pilled, and superior to SFT. It doesn't feel like the full story, especially as rollout lengths continue to expand. There are more S curves to find beyond, possibly specific to LLMs and without analogues in game/robotics-like environments, which is exciting.
Agentforce, now fully deployed @davos, is revolutionizing how attendees navigate this global summit. Not since #Dreamforce have we witnessed such impactful value delivery. Leveraging a decade of insights from WEF attendees' preferences and choices stored in Salesforce, Agentforce elevates attendee experiences to new heights. Discover the power of #Agentforce, your personal guide to maximizing your Davos experience. Empower your journey and unlock the full potential of this conference like never before! #InnovationAtDavos 🔥 Check out the app: https://t.co/o7SI5lj9oB
MINT-1T: Salesforce launched the first trillion-token open-source multimodal interleaved dataset. Salesforce uses it to train our models as a groundbreaking resource that scales up data diversity and size, enabling the training of larger, more capable multimodal models. Perfect for research and innovation in AI! Discover more:
https://t.co/AwSC5PZgS9
Congrats @SFResearch!


















![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)