BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!
CONFIRMED:
Uber has now capped agentic coding tools at $1,500 per employee per month per tool after it blew through the entire annual budget in 4 months.
Under CTO Praveen Neppalli Naga, reports say 10X of the blown output were driven by code commits from developers in India.
AKADEMİSYENLER VE DOKTORA ÖĞRENCİLERİNİN HEP KULLANDIĞI AMA HERKES BİLSİN İSTEMEDİĞİ SİTELER.
Bunu kaydedin mutlaka. Akademik anlamda sürekli ödeme yapmanıza gerek yok. Aşağıdaki siteler size fazlasıyla yetecek.
1. https://t.co/AiiUAUM75I
Dünyanın en büyük açık kütüphanesi. Profesörünüzün atadığı neredeyse her ders kitabı burada ücretsiz olarak mevcut.
2. https://t.co/NTBv4fcBI3
Akademik makaleler için arama motoru. En etkili araştırmaları bulmak için atıflara göre sıralayın.
3. https://t.co/rexxn41f8R
Akademik tez ve makale üretim motoru. Sıfır halüsinasyonla bölüm yazımı.
4. https://t.co/9AcMjHxGwm
Allen Enstitüsü tarafından geliştirilen yapay zeka destekli makale arama. Her atıfı bağlamında vurgular.
5. https://t.co/1pUSgSdS6D
Bir makaleyi girin, her ilgili çalışmayı bir grafik olarak haritalanmış görün. Uzmanların gerçekten birlikte okuduğu şeyleri ortaya çıkarır.
6. https://t.co/tHPqEh4Jfa
Bir yapay zeka araştırma asistanı. Herhangi bir soruyu sorun ve ana bulgularla birlikte yapılandırılmış makale tabloları alın.
7. https://t.co/iQBF4OKvAL
Binlerce makalenin sonuçlarını tek bir cevapta birleştirir. Kiraz seçmeyi önler.
8. https://t.co/FGPnpvrhZy
Makalelerin Spotify'si. Zaten okuduklarınıza dayanarak yeni araştırmalar önerir.
9. https://t.co/Hvs7besTv6
Atıf zincirlerini görselleştirir. Bir fikrin on yıllar süren araştırmalarda nasıl yayıldığını gösterir.
10. https://t.co/Pl3X0YIvIg
Hangi makalelerin herhangi bir iddiayı desteklediğini, çürüttüğünü veya bahsettiğini söyler. Saatlerce gerçeklik kontrolü yapmaktan tasarruf sağlar.
11. https://t.co/r7BhsKSHp7
200 milyon açık erişimli makale tek bir aranabilir indekste. Dünyanın en büyük ücretsiz akademik arşivi.
Today, the Stanford @DigEconLab launches the AI Economic Indicators, a new platform for tracking how AI is reshaping work, productivity, adoption, and the economy.
1/6
Andrej Karpathy spent 2h showing how he actually uses AI day to day
he's a co-founder of OpenAI and led AI at Tesla, so when he shows how he works, it’s worth watching
and the whole session is just him telling the machine what he wants in simple terms, like he's briefing a coworker
watch what's actually happening the entire time:
> he describes the task in normal words
> it goes off and does the work
> he glances at the result and nudges it with one more sentence
that's the whole skill, and you've had it since you learned to talk
the only gap between that and a worker that runs on its own is handing that sentence a schedule and the tools to act
check his work, then build the version that keeps working when you stop
The @UChi_Economics rule is 2 minutes per slide. Mike Golosov also added that each slide should have at most four bullets. I found this rule to only be viable at @UChi_Economics . Audiences show a wide range of interaction, most way below the Uchicago level. So I follow this rule:
- each slide should have only one idea, at most four bullets, and a bullet can never break a line
- if I know that the audience wants interaction, I follow the Uchicago gold standard
- if I am uncertain, I do one minute per slide and adjust during the talk.
It is often optimal to choose two contrasting experiments than more other experiments to determine entrepreneurial strategy, from @joshgans and Luca Gius https://t.co/eRGtSIJSry
hey academics --
frustrated with endlessly long/messy process of responding to referee comments? want to gamify the process and get through your response letter a bit sooner?
I saved you some compute and vibe coded something (experimental) you could use!
presenting Point by Point!
https://t.co/dQipXvTWLV
a platform to make responding to referees actually fun!
just upload your old paper + referee reports (in one pdf or separate files) and get a swanky interface where you can
a) dictate responses
b) get tips on how to respond
c) get grades on how hard the request is, how good your answer is
d) generate a final PDF document with responses
check it out!
Stanford recently livestreamed a 3.5 hour conference with leading economists (@Susan_Athey , Matt Gentzkow, and @ahall_research , among others) on "Empirical Work in the Age of AI"
I turned the whole thing into a readable transcript, separated by talk.
You can pass the whole thing to your coding agent to extract exactly what is useful for you.
Check it out here!: https://t.co/jKtU6mgG1X
Today, we're releasing our first Free Systems product: Bellwether, an API, MCP server, and dashboard to help the media report prediction-market prices more reliably.
Prediction markets can give us access to real-time, continuous, objective probabilities of important world events---but only if we build them to be well-structured, liquid enough, and resistant to manipulation.
Bellwether helps by:
--Reporting prices that are less manipulable because they're based on a volume-weighted average, not the last traded price
--Flagging whether the price comes from a sufficiently liquid market or not, so that the media can avoid reporting on prices that are unreliable or super easy to manipulate
--Standardizing across platforms, to help resolve when contracts for the same event across Kalshi and Polymarket are actually the same, or not
We hope that you'll check it out, let us know what you think, and suggest improvements!
https://t.co/9RMBUC2Ipo
This is joint work with @elliotjpaschal and @vania_chow
Μαθητές Γυμνασίου/Λυκείου στην Ελλάδα: άνοιξε ο Πανελλήνιος Διαγωνισμός Τεχνητής Νοημοσύνης (online).
Προθεσμία: 1 Μαρτίου 2026.
Διάλεξε 1 από τα προβλήματα και κάνε την 1η σου υποβολή. Links στο 1ο σχόλιο 👇
#ΤεχνητήΝοημοσύνη#AI#Πληροφορική
🚀 🇬🇷 A year in the making! I’ve just completed a set of 21 lectures in Machine Learning, in Greek, designed for high school students. The course introduces key ML concepts, coding in Python & PyTorch, and real-world AI applications. #MachineLearning#AI#EdTech#Greece
It’s happened.
Mac Studio is here. Gemma 4 31b @GoogleDeepMind installed, chatting with my main @openclaw for $0 in token expenses now...
I've burned $5-6k on tokens on my crazy ideas over past few months, so this mac studio should pencil out for me within 3 months or so 🤓
@aaryan_kakad Check this paper bro from my academic field "management", broadly defined: https://t.co/8xqyixCJlk
I found it beautiful conceptually and trying to find a tractable model around this notion of "jaggedness".
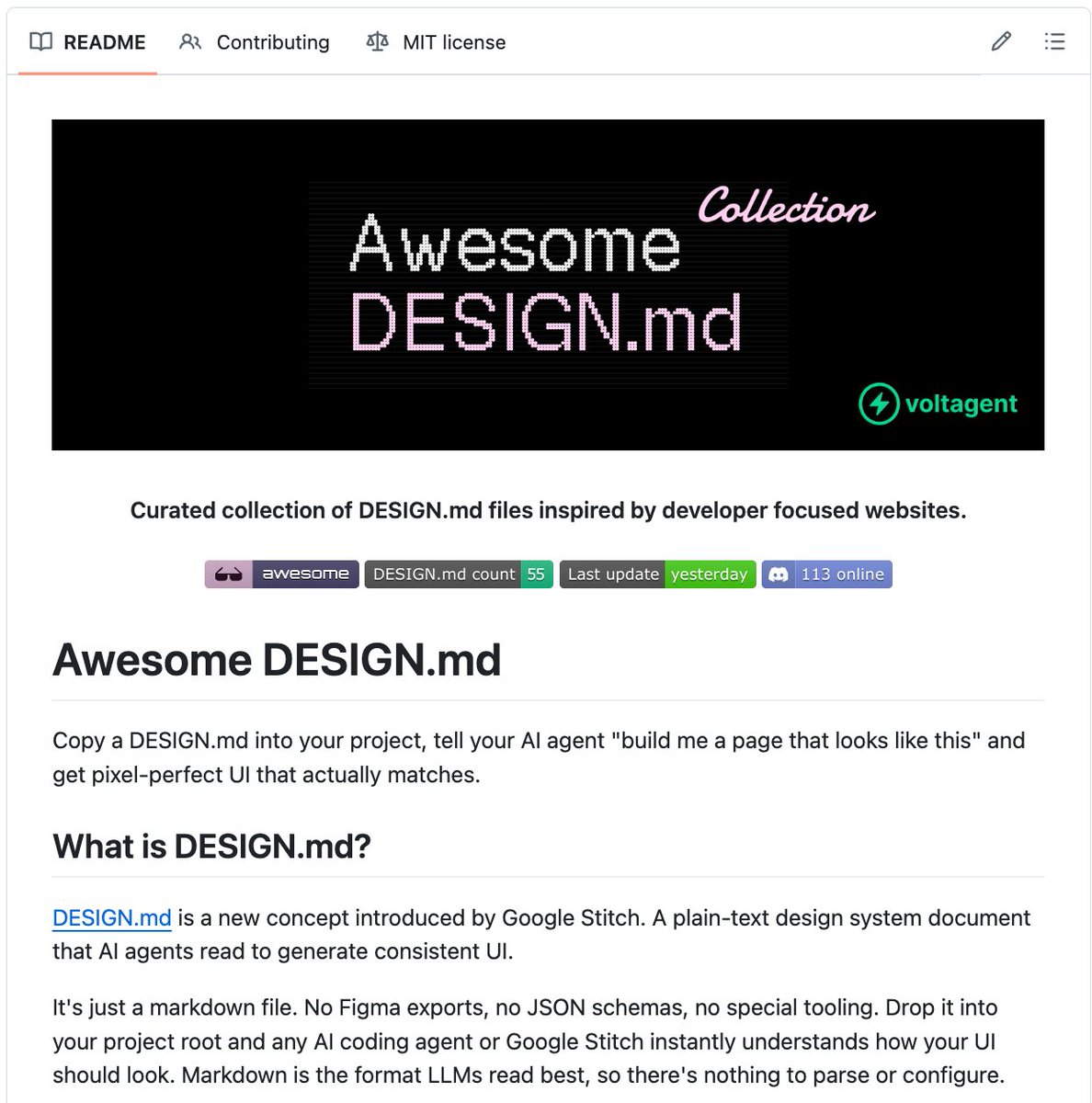
🚨 Someone reverse-engineered the design systems of Apple, Spotify, Airbnb, and 30+ billion-dollar companies.
Packed each one into a single file. Free.
It's called Awesome Design MD.
Drop one file into your project. Your AI agent builds UI that looks like Spotify. Or Apple. Or Airbnb. Instantly.
Not screenshots. Not Figma links. A single DESIGN .md file that captures every color, font, spacing value, button style, and layout pattern from a real website. In a format AI agents read and reproduce.
Here's the difference:
Tell Claude Code "build me a landing page" and it gives you generic UI.
Tell Claude Code "build me a landing page" with Spotify's DESIGN .md in your project and it gives you Spotify.
Here's what's inside:
→ Apple. Premium white space, SF Pro typography, cinematic imagery.
→ Spotify. Vibrant green on dark, bold type, album-art-driven layout.
→ Airbnb. Warm coral accent, photography-driven, rounded UI.
→ Linear. Ultra-minimal, precise spacing, purple accent.
→ SpaceX. Stark black and white, full-bleed imagery, futuristic.
→ BMW. Dark premium surfaces, precise German engineering aesthetic.
→ NVIDIA. Green-black energy, technical power aesthetic.
→ Uber. Bold black and white, tight type, urban energy.
→ Sentry, PostHog, Raycast, Cursor, ElevenLabs, and 20+ more.
Here's how to use it:
→ Pick a design system from the collection
→ Copy the DESIGN .md file into your project root
→ Tell your AI agent to use it
→ Get UI that matches the design language of a billion-dollar company
That's it. One file. Your AI agent now has the design taste of a $200/hour design consultant.
Designers charge $5,000+ for a custom design system. Companies spend $50,000+ building one from scratch.
This is free. 31 design systems. Copy. Paste. Ship beautiful UI.
Works with Claude Code, Cursor, Codex, and any AI coding agent that reads project files.
100% Open Source. MIT License.
Advice for PhD students in economics about using AI, from the brilliant Isaiah Andrews. This should probably be circulated to all PhD cohorts
https://t.co/07xEbmx5n5
This is Farzapedia.
I had an LLM take 2,500 entries from my diary, Apple Notes, and some iMessage convos to create a personal Wikipedia for me.
It made 400 detailed articles for my friends, my startups, research areas, and even my favorite animes and their impact on me complete with backlinks.
But, this Wiki was not built for me! I built it for my agent!
The structure of the wiki files and how it's all backlinked is very easily crawlable by any agent + makes it a truly useful knowledge base.
I can spin up Claude Code on the wiki and starting at index.md (a catalog of all my articles) the agent does a really good job at drilling into the specific pages on my wiki it needs context on when I have a query.
For example, when trying to cook up a new landing page I may ask:
"I'm trying to design this landing page for a new idea I have. Please look into the images and films that inspired me recently and give me ideas for new copy and aesthetics".
In my diary I kept track of everything from: learnings, people, inspo, interesting links, images.
So the agent reads my wiki and pulls up my "Philosophy" articles from notes on a Studio Ghibli documentary, "Competitor" articles with YC companies whose landing pages I screenshotted, and pics of 1970s Beatles merch I saved years ago. And it delivers a great answer.
I built a similar system to this a year ago with RAG but it was ass.
A knowledge base that lets an agent find what it needs via a file system it actually understands just works better.
The most magical thing now is as I add new things to my wiki (articles, images of inspo, meeting notes) the system will likely update 2-3 different articles where it feels that context belongs, or, just creates a new article.
It's like this super genius librarian for your brain that's always filing stuff for your perfectly and also let's you easily query the knowledge for tasks useful to you (ex. design, product, writing, etc) and it never gets tired.
I might spend next week productizing this, if that's of interest to you DM me + tell me your usecase!
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.