Another great example of how scientists, science journals and science journalists willfully distort science for clout and profit. Compare the much-hyped paper that just came out on the genetics of response to GLP1 receptor agonists to the press release about the paper.
The paper itself is fine.
https://t.co/qe9Y0YtoER
While it's not particularly surprising that variants in GLP1R and GIPR would be linked to drug efficacy and side-effects, it's useful to have the specifics documented in a study with a large sample size
However, as the paper reports, the effect sizes are pretty small, and even when you fold the genetics into a model with a host of non-genetic factors, the amount of the variance it explains remains small (and if past experience is a guide, is likely an overestimate).
But then you turn to Nature's own press-release, which tends to guide how the story is covered, and you get a sensationalist headline that does not accurately reflect the results in the paper: "Why obesity drugs work better for some people: these genes hold clues".
https://t.co/1Dje8xBB5Z
And now that's the story everybody's going to remember, even though the article actually reports the exact opposite of this result. This doesn't help science - all it does is engender distrust.
Obviously, science is dealing with a lot of challenges these days, but this one is entirely of our own creation, and it's really disgraceful that we collectively let this kind of journal propaganda dominate the way that science is portrayed to the public.
@MitoPsychoBio GFRAL neurons in the Area Postrema are a subset of the GLP1R neurons responsible for anorexigenic effects of semaglutide ( ozempic ). Do you think repeated activation of brainstem GFRAL neurons by sema could also have risks of interfering with GDF15 based energy sensing ?
My thoughts on connectomics and upload:
1) there is zero question connectomes are invaluable, and we need to get them for mouse, monkey, and human
2) the human, or even monkey, connectome seems a long ways off given costs (roughly $1/neuron). The projectome (map of all the axons) seems eminently reachable and should be a top priority imho
3) but even having the full connectome would only tell you numbers of synapses, not actual synaptic weights, and the two can be hugely divergent (eg only 5% of synapses onto V1 layer 4 neurons come from thalamus, even though this is the major driving input)
4) given #2 & #3, I think we can get to upload in the sense of building a functionally equivalent organism much faster through understanding the algorithms of the primate brain than through blind copying
5) in putting together something as complex as the human brain we would definitely want to check that the various pieces work as we go, which we can only do if we understand these pieces
6) I don't think upload in the sense of blindly creating a digital copy is the path to the abundant transhumanist future--actual understanding of brain structures so we can intelligently interface with them, and emulate their function in code without copying all the details, is.
All to say, we need functional understanding to go hand in hand with anatomical mapping!
@dileeplearning@AsteraInstitute Do we think completely reverse-engineering the cortex will bring us AGI? Don’t we also need to reverse-engineer the brainstem, hypothalamus —the regions that give us meaning and motivation, not just pure computation? That’s something LLMs already appear to be good at
Studies using fruit flies by University of Oxford researchers @RafSarnataro & Dr Peter Hasenhuetl are providing new insights into how sleep is controlled.
As two winners of the Emerging Neuroscientist Seminar Series 2025, they recently spoke at SWC ⤵️
https://t.co/4oebbT2gmy
Too much data, too little thinking.
A important essay from Ruslan Medzhitov on the importance of understanding data, not just generating it. A must read.
@RMedzhitov@YaleIBIO
https://t.co/d3Q2Slp0hx
This is so inspiring. I recommend everyone read this. In the near future, almost everyone will be able to go into founder mode for their health and personalize it thanks to AI advances. This won't require gadzillions or teams of experts. But we must break down the gatekeeping.
It's that magical time of year when private jets descend on a Swiss mountain village to discuss climate change and poverty! Anyway, here's my annual reminder. I'll stop posting this when they stop avoiding the real issue: their own massive tax avoidance 💰
Another great short essay, by Paul Nurse, 2021:
"Theorizing should be encouraged, and theories should be included in experimental papers to put data in context."
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.
Just out! “The astrocytic ensemble acts as a multiday trace to stabilize memory.” We identified astrocytic ensembles that link experiences across days to stabilize memory https://t.co/po9zIlZvPb. New astrocyte tools are openly available at Addgene: https://t.co/OXCmcYSleI. 1/8
Really interesting papers, confirming and extending what many believed true for a while. The last 20 years gave us the illusion of super hyper specialization of brain regions thanks to opto/chemogenetics. Turns out we were just under a lamppost. We're in a "neo-Lashley" era. Brain functions are mostly spread out throughout the brain, not in one spot. If you’re not already looking elsewhere than under the lamppost, you should.
MIT Course announcement: Machine Learning for Computational Biology #MLCB25
Fall'24 Lecture Videos: https://t.co/tA3zeuIF7g
Fall'24 Lecture Notes: https://t.co/C3WmXZuQur
(a) Genomes: Statistical genomics, gene regulation, genome language models, chromatin structure, 3D genome topology, epigenomics, regulatory networks.
(b) Proteins: Protein language models, structure and folding, protein design, cryo-EM, AlphaFold2, transformers, multimodal joint representation learning.
(c) Therapeutics: Chemical landscapes, small-molecule representation, docking, structure-function embeddings, agentic drug discovery, disease circuitry, and target identification.
(d) Patients: Electronic health records, medical genomics, genetic variation, comparative genomics, evolutionary evidence, patient latent representation, AI-driven systems biology.
Foundations and frontiers of computational biology, combining theory with practice. Generative AI, foundation models, machine learning, algorithm design, influential problems and techniques, analysis of large-scale biological datasets, applications to human disease and drug discovery.
First Lecture: Thu Sept 4 at 1pm in 32-144
With: Prof. Manolis Kellis @manoliskellis, Prof. Eric Alm @ejalm, TAs: Ananth Shyamal, Shitong Luo @luost26
Course website: https://t.co/ateGr6xKLM
@MIT@MITEECS@MITdeptofBE@MITCSBPhD@MIT_CSAIL@Harvard@HarvardMed@BroadInstitute
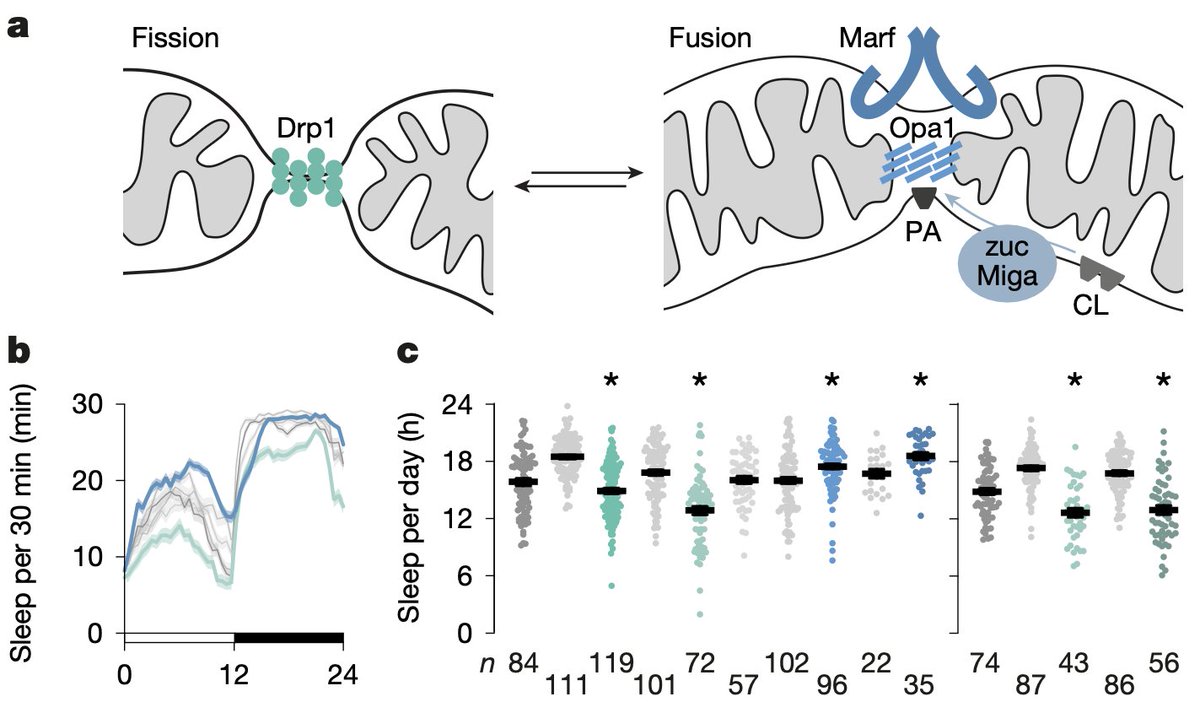
Why do we sleep? What happens in our cells that make us feel the need to go to bed?
New study in flies showing that as energy flows with more energy resistance (éR) in our mitochondria--producing "reductive stress"-- the pressure to sleep increases
Manipulating mitochondrial fusion and fission dynamics also changed the flies' daily need for sleep, connecting mitochondrial energetics and dynamics with sleep behavior
https://t.co/gsSTOJBAOn