Pope Leo on war: “Humanity possesses far more effective and capable tools for promoting human life and resolving conflicts, such as dialogue, diplomacy and forgiveness. The use of force, violence and weapons reflects a relational poverty that always has disastrous consequences for civilian populations.”
Token costs are why there will be no saas apocalypse / good dev tools are cached intelligence for agents!
The popular theory goes: agents can write code, so they'll just rebuild every tool from scratch and hit raw APIs. no more dev tools, no more CLIs, no more software layers. just agents and endpoints!
We just tested this and the data says the opposite. We benchmarked Claude Code and Codex on real Hugging Face Hub tasks (~1,000 graded runs), with two setups: the agent-optimized hf CLI vs the agent hand-rolling curl or SDK calls from scratch.
Hand-rolling burns up to 6x more tokens on multi-step tasks and fails more often (84% vs 94% task success).
And that's just dropping one abstraction layer. It would obviously be orders of magnitude more tokens and a dramatically higher failure rate if the agent tried to bypass HF altogether and rebuild model hosting, versioning, and distribution from scratch. Every time an agent re-derives a workflow from raw API calls, you pay for that reasoning in tokens. every single run. a good CLI compresses that entire chain into a few high-level commands the agent can't get wrong.
In a world where everyone is complaining tokens are too expensive, abstraction is leverage: thousands of hours of design decisions your agent doesn't have to re-reason about at inference time.
Good tools are cached intelligence for agents!
So no, agents won't rebuild everything from scratch. they'll gravitate to the most token-efficient tools, because that's what their owners pay for. The software that survives won't just be accessible to agents, it will be accurate and cheap for them to drive.
We're seeing it happen with HF, which is becoming the platform for agents to use AI: ~49M requests in just two months, and growing fast!
https://t.co/Y7q6yuxZrZ
.@ApolloAtomics builds the most compact nuclear reactors with the highest uptime and a deployment time of less than 24 months.
Apollo took the pressurized water reactor technology that already powers 80% of the world’s nuclear plants and flipped one part, the steam generator, to make the plant an order of magnitude smaller without compromising power.
Congrats on the launch, @AssilHalimi & Drew!
https://t.co/5lGDpZhmQ5
I read all 277 pages of SpaceX's IPO filing so you don't have to.
Losses up 700%. Revenue decelerating. 107x price-to-sales multiple.
It's a trainwreck. Full breakdown below 👇
my company got breached
the attacker had access for 11 days
on day 3 he emailed our IT helpdesk
complained that the VPN was slow
our helpdesk reset his password
upgraded his access tier to fix the "connectivity issue"
and closed the ticket as resolved
CSAT score: 5 stars
we found this in the logs during forensics
the attacker had rated our IT support
excellent
Singapore’s Foreign Minister, Dr Balakrishnan casually explaining how he built his own AI agent (a 2nd brain for diplomacy) using Claude & WhatsApp integration etc. on a Raspberry Pi
“You cannot govern a technology you have only been briefed on.” 🇸🇬
Yann LeCun says LLMs are strongest in domains where language itself is the substrate of reasoning, like math and code
They can solve problems, prove theorems, and write programs — but they are not creative mathematicians, software architects, or computer scientists
"their role is to help humans build"
Putin is scared.
His "fortress" is cracking and half his decrees are now secret — so Russians can't see how badly the regime is failing.
Here's what he's hiding 👇 [1/11]
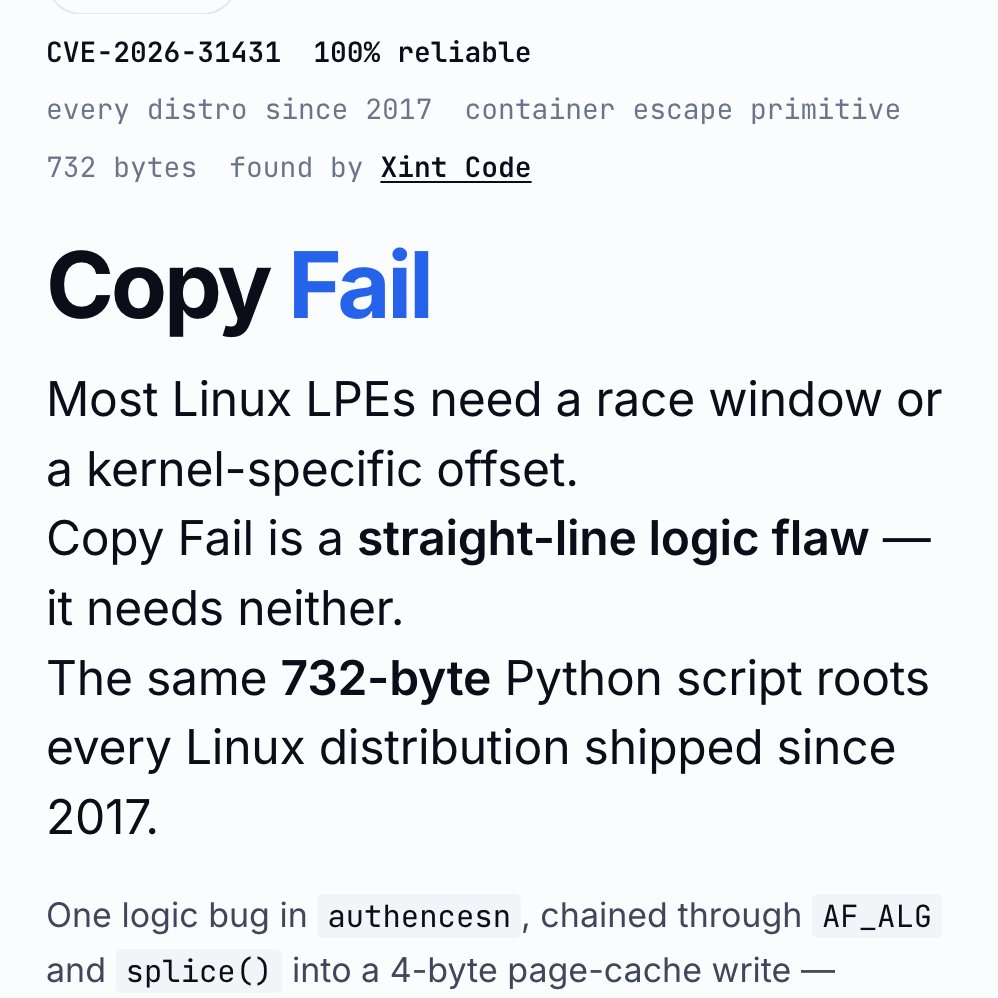
‼️🚨 BREAKING: An AI found a Linux kernel zero-day that roots every distribution since 2017. The exploit fits in 732 bytes of Python. Patch your kernel ASAP.
The vulnerability is CVE-2026-31431, nicknamed "Copy Fail," disclosed today by Theori. It has been sitting quietly in the Linux kernel for nine years.
Most Linux privilege-escalation bugs are picky. They need a precise timing window (a "race"), or specific kernel addresses leaked from somewhere, or careful tuning per distribution. Copy Fail needs none of that. It is a straight-line logic mistake that works on the first try, every time, on every mainstream Linux box.
The attacker just needs a normal user account on the machine. From there, the script asks the kernel to do some encryption work, abuses how that work is wired up, and ends up writing 4 bytes into a memory area called the "page cache" (Linux's high-speed copy of files in RAM). Those 4 bytes can be aimed at any program the system trusts, like /usr/bin/su, the shortcut to becoming root.
Result: the next time anyone runs that program, it lets the attacker in as root.
What should worry most: the corruption never touches the file on disk. It only exists in Linux's in-memory copy of that file. If you imaged the hard drive afterwards, the on-disk file would match the official package hash exactly. Reboot the machine, or just put it under memory pressure (any normal system load that needs the RAM), and the cached copy reloads fresh from disk.
Containers do not help either. The page cache is shared across the whole host, so a process inside a container can use this bug to compromise the underlying server and reach into other tenants.
The original sin was a 2017 "in-place optimization" in a kernel crypto module called algif_aead. It was meant to make encryption slightly faster. The change broke a critical safety assumption, and nobody noticed for nine years. That bug then rode every kernel update from 2017 to today.
This vulnerability affects the following:
🔴 Shared servers (dev boxes, jump hosts, build servers): any user becomes root
🔴 Kubernetes and container clusters: one compromised pod escapes to the host
🔴 CI runners (GitHub Actions, GitLab, Jenkins): a malicious pull request becomes root on the runner
🔴 Cloud platforms running user code (notebooks, agent sandboxes, serverless functions): a tenant becomes host root
Timeline:
🔴 March 23, 2026: reported to the Linux kernel security team
🔴 April 1: patch committed to mainline (commit a664bf3d603d)
🔴 April 22: CVE assigned
🔴 April 29: public disclosure
Mitigation: update your kernel to a build that includes mainline commit a664bf3d603d. If you cannot patch immediately, turn off the vulnerable module:
echo "install algif_aead /bin/false" > /etc/modprobe.d/disable-algif.conf
rmmod algif_aead 2>/dev/null || true
For environments that run untrusted code (containers, sandboxes, CI runners), block access to the kernel's AF_ALG crypto interface entirely, even after patching. Almost nothing legitimate needs it, and blocking it shuts the door on this whole class of bug...
Like @davidbessis and others, I think that Hinton is wrong. To explain why, let me tell you a brief story.
About a decade ago, in 2017, I developed an automated theorem-proving framework that was ultimately integrated into Mathematica (see: https://t.co/nGCIUk44TP) (1/15)
AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]
What gets missed with AI productivity gains is that by and large, most roles will continue to be as sophisticated as the tools allow.
This is why also thinking through “today’s jobs will be replaced with AI” is a fallacy. Everyone thinks the market is static, but it’s not.
As a result of everyone having access to the same technology which augments our work, then users of the tools will increasingly raise their level of output to the point where the prior definition of the job is no longer relevant. Thus, those that understand their particular field and grow in their skills will continue to be differentiated vs. others.
If you can do far more, then you start to tackle bigger and harder problems. If you do that, then the expertise still is required to get the job done fully.
The engineer with AI is going to be far more productive and capable with AI than the non-engineer trying to build the same piece of software. Building a lightweight app is no longer the definition of getting by in software development. Reviewing a contract will no longer be the definition of a paralegal. Splicing a video won’t be the definition of a video editor. Providing basic financial research won’t be the job of the financial analyst in the future.
Simply put, AI will naturally cause most roles to actually grow in complexity rather than reduce in complexity, because we can do far more with the tools.
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
Arrêtez de payer pour Claude IA.
L'IA de Mc Donald's est gratuite et répond à toutes les questions, même si elles ne sont pas sur le BIG MAC.
:-)
De rien.
Sequoia's thesis that the next $1T company will sell work, not software, is the most important reframe in AI right now.
The argument: if you sell a copilot, you're competing with every new model release. But if you sell the outcome — books closed, contracts reviewed, claims handled — every AI improvement makes your margins better, not your product obsolete.
The key insight most people miss: for every $1 spent on software, ~$6 is spent on services.
The entire SaaS playbook was about capturing the software dollar. The AI playbook is about capturing the services dollar — at software margins.
Not "AI for accountants." The AI accounting firm.
Not "AI for lawyers." The AI law firm.
The companies that figure this out won't look like SaaS companies. They'll look like services firms rebuilt on software infrastructure.
That's a fundamentally different company to build, fund, and scale. And most founders are still building copilots.
One of the takeaways from a mindblowing conversation with @harper: We have this idea that a product is a thing, when in fact a product may now be a dynamic set of possibilities that are called out by a process, and may be co-created and constantly modified by our customers. https://t.co/Wo1cPWvYPe




























![khodorkovsky_en's tweet photo. Putin is scared.
His "fortress" is cracking and half his decrees are now secret — so Russians can't see how badly the regime is failing.
Here's what he's hiding 👇 [1/11] https://t.co/NZSCmZIWGF](https://pbs.twimg.com/media/HHD9FqSWUAAxjpy.png)

![AndrewYNg's tweet photo. AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]](https://pbs.twimg.com/media/HG7HHJqbsAA3iao.jpg)
































