Random thoughts after trying 3 amazing AI+consumer tools @a16z highlighted:
@mindseraAI provides coaching to improve journaling and reflection. It uses guidelines and methodologies, aiding those who struggle with writing, like ChatGPT's recommended questions.
@wadefoster@zapier We built an internal agent to collaborate. Access control and interation are challenging. Would love to try it. We perfectly fit all the expectations here
Features
- Unified tool inventory. All skills, MCPs, plugins, commands, hooks across 34 agents in one table.
- Cross agent install. Install once, enable on any agent via symlink. No copies, no drift.
- Full CLI. Everything in GUI also works as shuttle command.
I built Shuttle. Mac app for managing skills across 34 AI agents.
Claude Code, Codex, Cursor, Gemini CLI, OpenCode all in one place.
Install a skill once. Enable on whichever agent you want. Symlinks, not copies. No version drift.
https://t.co/7CcmisA4xv
3: CapEx/Revenue gap.
~$690B hyperscaler AI capex in 2026.
~$100B in direct AI software revenue.
7x gap.
Sequoia's David Cahn called this the "$600B question" in June 2024. The gap has only widened since.
Apps are the only path to converting infra spend into actual revenue.
There's a reliable rotation between Infra and apps.
1/ Infra goes open source → value moves to apps
2/ Infra commoditizes, fierce competition → margin compresses, apps capture value
3/ CapEx explodes but revenue lags → apps become the only way to justify the spend
2: commoditized infra
the enterprise llm market flipped fast: openai went from ~90% share to anthropic taking ~70% of new spend in 18 months.
with 5+ models within ~2% on benchmarks, models become a commodity.
edge moves to workflows, data, and distribution: the app layer.
Dub — Open-Source Link Attribution Platform
Started as a URL shortener and evolved into an open-source link attribution platform covering the full pipeline of link management → conversion tracking → affiliate payouts. Used by 100,000+ companies including Twilio, Vercel.
The opportunity: whoever owns the policy layer owns the institutional DeFi stack.
This is the boring, essential middleware that makes the next $1T in institutional DeFi possible.
Institutions want DeFi exposure. Everyone knows this. But there's a missing piece almost no one is building: programmable policy enforcement.
Without it, institutions can't touch DeFi. With it, the floodgates open. 🧵
The mental model shift: DeFi has been punitive. you break the rules, you get liquidated. Institutions need DeFi to be proactive. the rules are enforced before you can break them.
That's a completely different architecture.
Liquidity disappears fast. exactly what Gorton described in 2007: AAA collateral flipped from info-insensitive → info-sensitive, repo haircuts jumped, markets froze.
Leverage RWA will speed this up.
Vault risk is quietly becoming information-sensitive.
When a “safe” collateral needs due diligence, it stops trading like money and starts trading like stock.
Why P.M. wins?
- Capped Risk: No liquidation wicks. You know your max win/loss instantly.
- Time Agnostic: You don't fight complex Theta decay. You simply bet on a reality coming true.
Every token will soon have three standard listings:
- Spot
- Perp
- Prediction Market
Perps made leverage accessible. Prediction Markets will democratize Options.
Decentralized AI will come back this year, providing cheaper and faster inference for capable models. @exolabs@hyperbolic_labs
With smart models and tools, Agents are used in production. This year, long running tasks is hot. Cost and performance will become bottleneck.
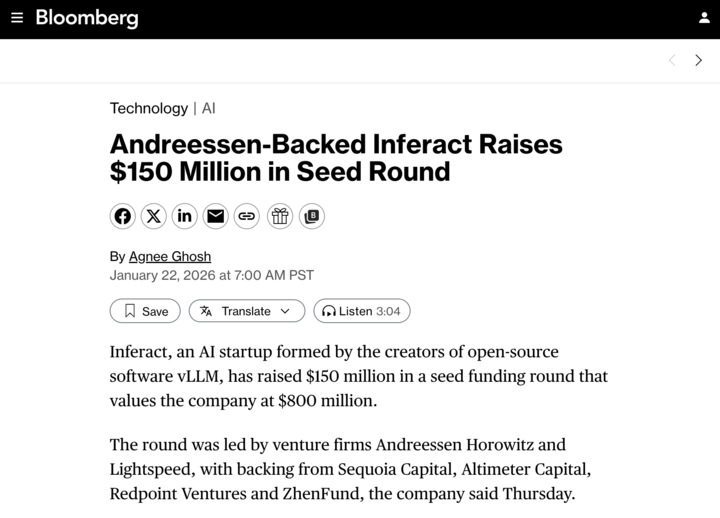
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale. This ecosystem, built with 2,000+ contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team