Today, I’m excited to formally announce @mirendil with my amazing co-founders Harsh Mehta, Shayan Salehian, and Tara Rezaei!
We’re fortunate to work with @a16z and @kleinerperkins, who led our seed round of $200M, followed by a major investment from NVIDIA, among others.
Mirendil exists to accelerate science and technology, and through them, to help solve humanity's most pressing problems.
Self-accelerating AI R&D is the most direct path to delivering on AI's broader promise, which is why we believe the most important application of AI is AI itself. Get this loop right, and it compounds. It fundamentally changes the rate of progress itself across all domains.
We believe this capability should be democratized. It should be used to power all scientific efforts trying to innovate at the frontier. There are far more important problems—and broader ones—than any single lab can take on, so more groups should be able to pursue them.
This pulls concentration of power away from a few labs: businesses and science labs can own their AI and infrastructure, keep their margins, and control their own destiny instead of ceding it all to a single AI lab.
We’re a small team with a singular focus. Our founding team consists of 20 researchers and engineers from frontier institutions including Anthropic, xAI, Google DeepMind, and OpenAI, united by a passion for science and a drive to build the technologies that move it faster. If you want to build the system that builds systems, join us!
@HarshMeh1a, @shayan_, @tararezaeikh
Our team just published a deep dive on Anthropic, and what made it such an unusual winner in AI.
The easy answer is Claude Code, coding revenue, or Dario. The more interesting answer, to us, is organizational. Anthropic pulled off two things that rarely show up together: real strategic focus and a genuinely coherent culture.
In an industry where everyone wants to chase every frontier at once, Anthropic has been unusually willing to say no. Fewer bets. Lower egos. A stronger mission. More patience for the unglamorous work that actually compounds.
This piece is our attempt to unpack how that happened, and why culture might be the most underrated source of advantage in AI.
Read here: https://t.co/IiPCkky2Vi
@EngramLab came out of stealth today, $98M, and one of their launch partners is Harvey.
by my count that makes Engram the 5th outside team Harvey now leans on for model work. four of them are straight post-training plays — @appliedcompute, @FireworksAI_HQ, and @baseten on open-weight models, plus @trajectorylabs.(Notion shows up in some of the same announcements too, so this isn't just a Harvey thing.)
here's the fun part: Engram, the 5th, doesn't even call itself a post-training company. they explicitly reject the pre-train/post-train split — the whole pitch is models that are "always training," i.e. continual learning + memory. i'm counting them anyway, and that reframe is kind of the whole story. (Trajectory's in the same continual-learning camp, which tells you which way the wind's blowing.)
funny thing is, this time last summer a friend close to Harvey told me one of their internal "things we got wrong" was trying to post-train models for legal tasks. basically zero return.
a year later everyone's doing it. three things flipped imo:
- applied AI research is getting outsourced. companies like Harvey are sitting on a mountain of real-world data that has to get used somehow, but standing up an outstanding research team is brutal right now with the talent war. so you partner out the open-ended exploration. cleaner.
- intelligence → cost. you're paying up for frontier intelligence and the harnesses quietly balloon your token usage (black box, good luck auditing it). open model + post-training cuts the bill and props up the long tail of use cases.
- the value prop of post-training is changing shape. the old world was SFT. the new one is continual learning + memory-style personalization — which is exactly why a "memory" company lands on this list at all.
and yeah, Engram. engram = memory trace. the name kind of tells you where this whole thing is going.
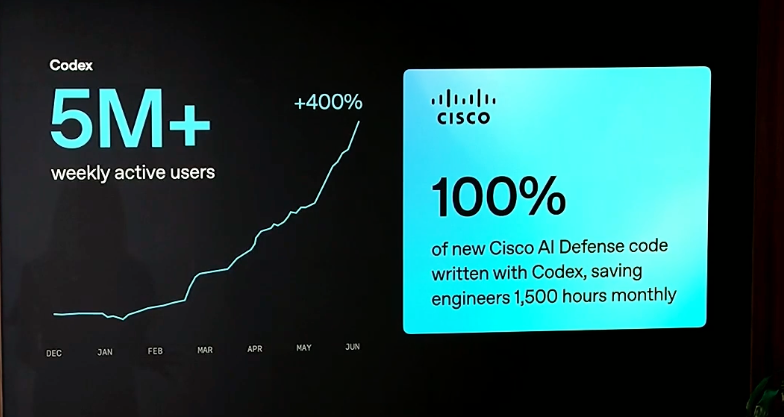
OpenAI's Intelligence at Work stream today re-confirmed Codex's turnaround is real. 5M weekly actives now. the shift in how people around me talk about it has been pretty striking:
- even before GPT 5.4, some had already noticed Codex just follows complex prompts more reliably. Claude Code feels smarter in some ways but it's way more prone to going off and doing its own thing
- then OpenAI got aggressive on pricing, cheap with generous usage, so people didn't drop Claude Code, they stacked the two. CC for planning and review, Codex for actually writing code. the one real knock on GPT 5.4 was how slow it was, but Spark fixed that almost overnight
- then GPT 5.5 and the updates after Opus 4.7 flipped things. a lot of people i know have now switched to Codex as their main driver
Anthropic's pricing is pulling in two directions right now, and I think the second one is where it gets interesting.
Big enterprises are just paying it. According to The Information, ServiceNow torched its whole annual budget in a few months, Palo Alto's shelling out 6x for Mythos, and everyone keeps saying it's worth it. Makes sense, because for them tokens are basically a productivity expense, not something that eats into what they sell.
The AI apps can't think that way. If tokens are your actual cost of goods, Anthropic's price is a margin problem you have to solve, so Cursor, Factory and Harvey have all been routing off a single frontier model just to stay viable.
Here's the thing though. That squeeze didn't hurt them. Open source caught up right about when they needed it to. Composer turned out to be a huge success. Factory said its open usage tripled against closed last month. Harvey built its own runtime so picking a model is just a routing call now. The pricing pressure didn't break the app layer, it shoved it down onto a floor open source had quietly been raising the whole time.
So you end up with the same token clearing at two totally different prices depending on who's holding it. And every frontier release widens that gap. It sells the genuinely hard stuff at a premium, and at the same time knocks last quarter's premium tasks down to where cheap-and-good-enough is fine. The frontier keeps building the cheap market it then has to stay ahead of.
Which is the part I'd actually watch. Once the harness is standardized the model is just a swappable part you shop around for, and the labs pushing managed runtimes are trying to climb up a layer to get lock-in back before that fully happens. Whoever ends up owning the routing layer, and the evals that make routing something you can trust, gets to set the clearing price for intelligence. Right now nobody does.
Narrative violation:
Open model use in Factory has more than 3x’d in the last month relative to closed models. By both total consumption and event count.
Will be interesting to see what open vs closed token-share looks like at EOY
Nuance: the buyer is actually Centurium Capital, Luckin's controlling shareholder — not Luckin itself. Centurium was Luckin's Series A backer, then led the post-fraud rescue in 2022 (bought out disgraced founders w/ IDG & Ares, restructured the whole business). Li Hui, Centurium's founder, is now Luckin's chairman.
They looked at Starbucks China (wanted control, didn't happen) and Costa Coffee (got close, fell through) before landing on Blue Bottle. Plan is to run it separately from Luckin — premium positioning + a real US footprint for <$400M. Nestlé paid $425M for just 68% back in 2017.
One of the wildest PE turnaround arcs in China: fraud → delisting → $180M SEC fine → new ownership → 31K stores & $7B revenue → now acquiring iconic US specialty coffee brands. Centurium basically speedran the Luckin redemption arc and is now exporting the playbook.
Luckin Coffee (Chinese Starbucks) acquired Blue Bottle retail operations for $400M from Nestle, who had bought a majority at a ~$700M valuation back in 2017. Blue Bottle had raised from True, Index and GV.
Nestle will keep the FMCG brand.
Luckin was delisted from the Nasdaq in 2020 when it came out that they had fabricated $310M of sales, and paid a $180M fine. They seem to have turned it around and might get relisted after 5 years in the penalty box. It’s trading at ~$10B on OTC markets
https://t.co/VqRjbMQ38f
@rexsalisbury yep even in enterprise i'm seeing engineers start to skip SendGrid/WorkOS entirely and just leverage agentic engineering to build their email agents. fewer abstractions, faster iteration, actually works
Did some research on this product and felt impressed. Wanted to share some notes because I don't think enough people are paying attention to this one.
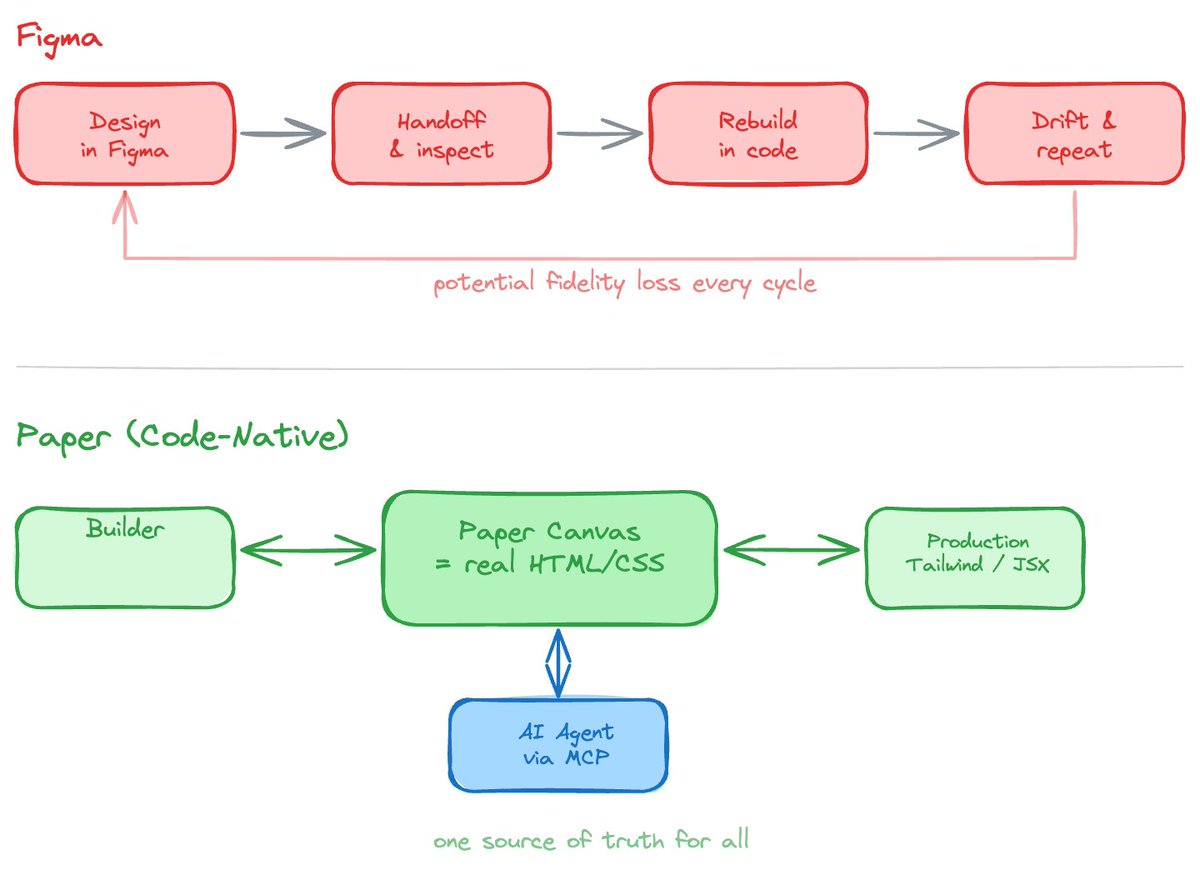
Quick context: the team behind @paper built Radix UI. If you've worked with React in the past few years, you've almost certainly used it.
The big idea is dead simple but the implications are huge: everything you design in Paper is actual HTML/CSS/React. Not a proprietary format that some plugin tries to "export" into code. The design IS the code. You copy a component out of Paper and you get production-ready Tailwind or JSX. They're working directly with Tailwind team on real-time Tailwind rendering, idiomatic import/export.
The thing that really got me is the agent story. Paper is the first design tool I've seen that treats AI agent integration as a first-class architectural decision, not a feature. Through MCP, any agent can read and write your design files directly. Create frames, update styles, pull JSX output, take screenshots. Your coding agent and your design team literally share the same canvas now.
I've been using @Paper + Codex/Claude for the past few days and this is truly a step function change in design/dev workflows.
Just reflecting on the different tools I've used in the past: Sketch, Zeplin, Wake, Origami, Pixelcloud, Abstract, Framer...
What a time we live in
I've been seeing more and more posts like this lately, and it got me thinking—what if we organized a more structured trip to China for folks who want to go deeper?
Some ideas:
- Visit top AI labs (DeepSeek, Qwen, Kimi, ByteDance Seed) and have real conversations with their leadership and researchers
- Head to Shenzhen and Guangzhou to experience the insane innovation velocity in consumer electronics and see how the ecosystem enables companies like Bambu Lab and Plaud to innovate and ship so fast
- Meet with leading Chinese VCs to understand what's happening at the frontier
- Fun activities along the way
...
If there's enough interest, I know enough people on the ground to actually make this happen. DM me if you're interested and feel free to throw in more ideas.
Just scanned 120 comments on the Codex App launch thread on HN. Here's the sentiment breakdown:
✅ Positive signals
- GPT-5.2-Codex model upgrade is legit, users report fewer manual edits needed
- Multi-agent parallel execution (up to 4) is a real differentiator vs Claude Code's single thread
- Free tier access + doubled rate limits, so competition is good for everyone
⚠️ Biggest risk
- The follower narrative is now baked in: MCP, Skills, desktop agents... the community sees @OpenAI as copying @AnthropicAI's tooling playbook, not innovating macOS only at launch, Windows/Linux devs are vocal about frustration
- Output consistency still a problem: Session A is chef's kiss, Session B is random vandalism
🏟️ Competitive mentions
@AnthropicAI Claude Code mentioned 20+ times, the default benchmark.
@cursor_ai also came up frequently.