Together @harpolabs and I developed a web app to estimate how many packs are needed to complete a Panini album https://t.co/F4lH8kh4JP
A report summarizing the probabilistic theory behind this web app can be read at https://t.co/xDwNHVQaGO
Let the Paninimania begin!😀
🚄Taking RAG apps from POC to Production, Fast
Learn how @nutlope , author of the viral open source app PDF to Chat, built a POC that scaled seamlessly to tens of thousands of users overnight
https://t.co/pgW2Q68THk
📽️ New 4 hour (lol) video lecture on YouTube:
"Let’s reproduce GPT-2 (124M)"
https://t.co/QTUdu8b0qh
The video ended up so long because it is... comprehensive: we start with empty file and end up with a GPT-2 (124M) model:
- first we build the GPT-2 network
- then we optimize it to train very fast
- then we set up the training run optimization and hyperparameters by referencing GPT-2 and GPT-3 papers
- then we bring up model evaluation, and
- then cross our fingers and go to sleep.
In the morning we look through the results and enjoy amusing model generations. Our "overnight" run even gets very close to the GPT-3 (124M) model. This video builds on the Zero To Hero series and at times references previous videos. You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
Github. The associated GitHub repo contains the full commit history so you can step through all of the code changes in the video, step by step.
https://t.co/BOzkxQ8at2
Chapters.
On a high level Section 1 is building up the network, a lot of this might be review. Section 2 is making the training fast. Section 3 is setting up the run. Section 4 is the results. In more detail:
00:00:00 intro: Let’s reproduce GPT-2 (124M)
00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint
00:13:47 SECTION 1: implementing the GPT-2 nn.Module
00:28:08 loading the huggingface/GPT-2 parameters
00:31:00 implementing the forward pass to get logits
00:33:31 sampling init, prefix tokens, tokenization
00:37:02 sampling loop
00:41:47 sample, auto-detect the device
00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
00:52:53 cross entropy loss
00:56:42 optimization loop: overfit a single batch
01:02:00 data loader lite
01:06:14 parameter sharing wte and lm_head
01:13:47 model initialization: std 0.02, residual init
01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
01:39:38 float16, gradient scalers, bfloat16, 300ms
01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
02:00:18 flash attention, 96ms
02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping
02:21:06 learning rate scheduler: warmup + cosine decay
02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms
02:34:09 gradient accumulation
02:46:52 distributed data parallel (DDP)
03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU)
03:23:10 validation data split, validation loss, sampling revive
03:28:23 evaluation: HellaSwag, starting the run
03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro
03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA
03:59:39 summary, phew, build-nanogpt github repo
Meet #DBRX: a general-purpose LLM that sets a new standard for efficient open source models.
Use the DBRX model in your RAG apps or use the DBRX design to build your own custom LLMs and improve the quality of your GenAI applications. https://t.co/wXzxQOZym6
Video of the talk I gave yesterday at the Bavarian Academy for the Sciences and Humanities in Munich.
Topics:
- What AI and deep learning can do today: image and language understanding.
- the Self-Supervised (Deep) Learning revolution.
- AI in science and medicine: medical imaging, physics, chemistry, biology, neuroscience, material science, environmental protection.
- AI in social media and online services
- Generative models for images.
- Auto-Regressive LLMs: power and limitations.
- We are still quite far from human-level AI, how do we bridge the gap?
- World models and Self-Supervised Learning from images and video.
- A cognitive architecture for Objective-Driven AI: machines that could understand how the world works, have common sense, reason, and plan.
- The future impact of AI on society: a new renaissance.
Slide deck: https://t.co/FA8sYGSv3K
https://t.co/kMaFcpzc7r
🎡 Introducing LangChain Hub 🦜🔗
A place to publish, discover, and try out prompts
We’re particularly excited about a centralized hub’s promise to enable:
-Encoding of expertise
-Discoverability of prompts for a variety of models
-Inspectability
-Cross-team collaboration
🧵
🧮LangChain "RAG Evaluation" Webinar
RAGAS is an open-source evaluation framework for your Retrieval Augmented Generation (RAG) pipelines
I'm VERY excited to be doing a webinar with them next week!
RAGAS Repo: https://t.co/kNz8jvkZ9X
Webinar: https://t.co/GMAr6hvzhW
Flowise is trending on GitHub
It's an open-source drag & drop UI tool that lets you build custom LLM apps in just minutes.
Powered by LangChain, it features:
- Ready-to-use app templates
- Conversational agents that remember
- Seamless deployment on cloud platforms
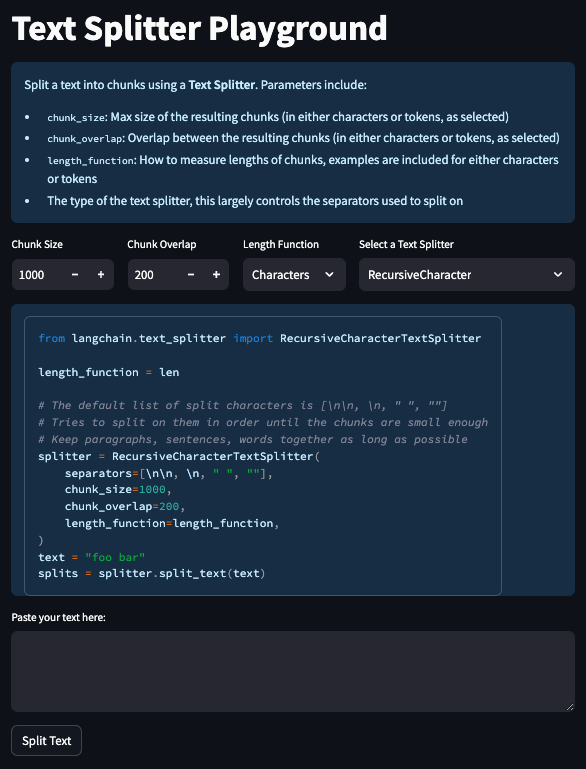
✂️Text Splitting Playground
Chunking text into appropriate splits is seemingly trivial yet very nuanced
Open sourcing a playground to help explore different text splitting strategies
GitHub: https://t.co/xqv2DONj84
Hosted Playground: https://t.co/NuxcPlx65i
LLM Use Case: Summarization 📚🧠
We've kicked off a community driven effort to improve @langchain docs, starting w/ popular use cases. Here is the new use case doc on Summarization w/ @GoogleColab notebook for easy testing ...
https://t.co/kTpWdY3sVU
Daniel Fabian and Jacob Crisp from @GoogleAI wrote an excellent summary of the types of attacks their red teams focus on mitigating. This is part of the work we do as well. If you work with generative AI, you must read this. https://t.co/bzcT8gzqT1
The open source models arena
I try not to post too much about open models until we reach a point where there will no longer be any debate about if they are at the level of closed models.
So let's make it brief.
----
LLaMA 2
The open models arena heated up last week with the release of LLaMA 2.
The model is a direct continuation of the base model for the LLaMA from Meta and marks a significant leap from the first model that can be attributed mainly to the double amount of data on which the model was trained on.
(And probably also the quality of this data, which remained confidential)
The model was also released in a chat version but I will not expand on it at this stage, that chat version suffers from several problems and it is considered not very useful at the moment.
(But the paper do list many tricks used when training the chat version and those tricks are especially interesting and useful. recommended)
----
Update Versions
Since the release, nearly all groups working on open source models have updated their models to use the new base model.
We received updated versions from some of the most powerful open models today:
- New WizardLM model: https://t.co/dd4SqtDtwF
(from @WizardLM_AI)
- New Airoboros model: https://t.co/qZxDhkNj9U (from @jon_durbin)
- New Hermes model: https://t.co/BvXu1h4ADo (from @NousResearch)
----
The most powerful model today: Stable Beluga 2
(from @StabilityAI & @carperai)
Last week we also got one of the most powerful open models we've seen so far from StabilityAI.
The model is comparable to ChatGPT in almost [1] all measurable metrics and is currently holding the first place on Huggingface's leaderboard.
- Stable Beluga 2: https://t.co/eObXUcvV5O
-----
Long Models
The research on extending the context window length also continues in full force we received longer versions of the base model itself, which you can find here:
- LLaMA 7B 16K: https://t.co/E8KuF1W081 (from @EnricoShippole)
- LLaMA 13B 16K: https://t.co/51GeYxMawl (from @EnricoShippole)
- LLaMA 7B 32K: https://t.co/iq6Qxt0fJz (from @togethercompute)
-----
Small Powerful Models
Another interesting model we got is a 3B-parameter model that is as powerful as a 7B model.
This goes to show what most of us have feel for a long time: We have not yet reached the limit of these models. There is more to push.
You are probably thinking that the trick is simply more data: as always.
Surprise.
The tricks are:
- A large (600B) fully de-duped dataset: SlimPajama. This is the first model to train on slim pajama end 2 end [1]
- SwiGLU [2]
- ALiBI [3]
- Variable Sequence Length (2 stage training: short then long) [4]
- Maximal update parameterization (muP): Allows you to "guess" the best hyper-parameters before starting to train. [5]
- BTLM-8K-Base: https://t.co/wMkbIU8tS3 (from @cerebras)
---
[1] https://t.co/ipWKikv9Dg
[2] https://t.co/cZwmBK1sAl
[3] https://t.co/Zfz2hEw9YN
[4] https://t.co/vgvKVrxUr6
[5] https://t.co/EVF2XzG9xn (remember that on GPT-4's paper, the loss was "predicted" before the training started?)
---
-----
Open model defeats ChatGPT in MMLU
Although a single number on a single test does not reflect reality, Last week for the first time we got a model that defeats ChatGPT at MMLU.
(And is not particularly trained to do so. That's why it's impressive)
The model: https://t.co/KzYHPeSTxr
-----
Multi-Turn Chats
One of the main differences setting apart open source models at the moment is multi-turn conversations, (in my humble opinion) we already got to the point where in a single turn our models compete with the closed models but when it comes to multi-turn conversations: Open models tend to go off topic.
This is about to change.
A particularly interesting model was released serveral days ago: Another model trained according to Orca's methods (adding detailed explanations to each answer) BUT for multi-turn long chats.
The model was created with a window length of 8K and according to initial impressions it is one of the best models released.
The model: https://t.co/Epgb04d7EW (from @Shahules786)
-----
Chinese models are putting up a fight
Even before the release of Lemma 2, it was clear that the Chinese models are already particularly strong.
And you are advised to try them, their English is excellent and some of them are very useful.
The most powerful programming model for its size: CodeGeex2
The Chinese coding model CodeGeeX2 comes to us with a tiny size of 6B parameters (trained from the flagship Chinese model ChatGLM) and overtakes all models of this size scoring 35.9 on HumanEval (Pass@1).
The model: https://t.co/HnRREpqCNj (from @thukeg)
-----
More details on the Chinese models
Lately I find myself reading more and more posts translated from Chinese via Google Translate.
Infrastructure for LLMs training and dealing with data coming from China is often times particularly high-quality and also incorporate techniques that do not exist in more popular code bases.
(Such as: training with masking, bidirectional training, architecture improvements and delicate tokenizer work to support the Chinese language)
I recommend everyone in the field to also read about the advances of the Chinese models.
-----
Are the open models already at the level of ChatGPT?
Short answer: Not yet, but they are on their way.
Usually when someone say that open source models are on the level of ChatGPT, immediately someone comes up with the hardest test they can think of to show that the open source models are not on the same level as ChatGPT.
According to rumors, ChatGPT was trained on somewhere around 6 times the data of LLaMA 2.
If you want to find holes, you will find them.
Nonetheless, in the real world: I use open models everyday they are just as good as ChatGPT.
-----
What is still left to do?
After the release of the Stable Beluga 2 model I wrote a post summarizing all the metrics from all the datasets where the model's results still don't crush ChatGPT.
You can find it here: https://t.co/aDNFtCHhyl
-----
How do we measure the quality of models?
There are several main "holes" that separate the open models from the closed models, you can read about these holes and the differences between the various models here: https://t.co/5vLhrCf4Eb
-----
From the news: Open source model from OpenAI?
On the background of this, we recently received an interesting news article about the efforts within OpenAI to release an open model.
Link: https://t.co/5NQVxpfBIa
It is not known if the information in this article is correct, but according to the article, open source models are putting pressure on OpenAI they are currently working on an open model as a response to the LLaMA 2.
The model does not compete with the quality of ChatGPT (and certainly not with GPT-4).
A new episode of Bicicletas Mentales with Pablo Rubinstein, one of my cofounders at @gradientdefense. It's in Spanish, so I had an idea: the first person to reply to this tweet with a sound file containing a decent machine-generated translation into English (there must be two voices matching each of us) gets $100 (USDT if you prefer). $50 bonus if the voices sound close to ours.
https://t.co/7dP3O5Y13n
Oh my, LLaMA 2! 7B, 13B, 70B, 2T tokens, 4K context, commercial license!
https://t.co/W21MjxhAxV
But why, Meta, why no 33B or similar size? You missed out the sweet spot? :(
Unless with 2T tokens and 4K context, 13B proves more than good enough.. could be!























![Yampeleg's tweet photo. The open source models arena
I try not to post too much about open models until we reach a point where there will no longer be any debate about if they are at the level of closed models.
So let's make it brief.
----
LLaMA 2
The open models arena heated up last week with the release of LLaMA 2.
The model is a direct continuation of the base model for the LLaMA from Meta and marks a significant leap from the first model that can be attributed mainly to the double amount of data on which the model was trained on.
(And probably also the quality of this data, which remained confidential)
The model was also released in a chat version but I will not expand on it at this stage, that chat version suffers from several problems and it is considered not very useful at the moment.
(But the paper do list many tricks used when training the chat version and those tricks are especially interesting and useful. recommended)
----
Update Versions
Since the release, nearly all groups working on open source models have updated their models to use the new base model.
We received updated versions from some of the most powerful open models today:
- New WizardLM model: https://t.co/dd4SqtDtwF
(from @WizardLM_AI)
- New Airoboros model: https://t.co/qZxDhkNj9U (from @jon_durbin)
- New Hermes model: https://t.co/BvXu1h4ADo (from @NousResearch)
----
The most powerful model today: Stable Beluga 2
(from @StabilityAI & @carperai)
Last week we also got one of the most powerful open models we've seen so far from StabilityAI.
The model is comparable to ChatGPT in almost [1] all measurable metrics and is currently holding the first place on Huggingface's leaderboard.
- Stable Beluga 2: https://t.co/eObXUcvV5O
-----
Long Models
The research on extending the context window length also continues in full force we received longer versions of the base model itself, which you can find here:
- LLaMA 7B 16K: https://t.co/E8KuF1W081 (from @EnricoShippole)
- LLaMA 13B 16K: https://t.co/51GeYxMawl (from @EnricoShippole)
- LLaMA 7B 32K: https://t.co/iq6Qxt0fJz (from @togethercompute)
-----
Small Powerful Models
Another interesting model we got is a 3B-parameter model that is as powerful as a 7B model.
This goes to show what most of us have feel for a long time: We have not yet reached the limit of these models. There is more to push.
You are probably thinking that the trick is simply more data: as always.
Surprise.
The tricks are:
- A large (600B) fully de-duped dataset: SlimPajama. This is the first model to train on slim pajama end 2 end [1]
- SwiGLU [2]
- ALiBI [3]
- Variable Sequence Length (2 stage training: short then long) [4]
- Maximal update parameterization (muP): Allows you to "guess" the best hyper-parameters before starting to train. [5]
- BTLM-8K-Base: https://t.co/wMkbIU8tS3 (from @cerebras)
---
[1] https://t.co/ipWKikv9Dg
[2] https://t.co/cZwmBK1sAl
[3] https://t.co/Zfz2hEw9YN
[4] https://t.co/vgvKVrxUr6
[5] https://t.co/EVF2XzG9xn (remember that on GPT-4's paper, the loss was "predicted" before the training started?)
---
-----
Open model defeats ChatGPT in MMLU
Although a single number on a single test does not reflect reality, Last week for the first time we got a model that defeats ChatGPT at MMLU.
(And is not particularly trained to do so. That's why it's impressive)
The model: https://t.co/KzYHPeSTxr
-----
Multi-Turn Chats
One of the main differences setting apart open source models at the moment is multi-turn conversations, (in my humble opinion) we already got to the point where in a single turn our models compete with the closed models but when it comes to multi-turn conversations: Open models tend to go off topic.
This is about to change.
A particularly interesting model was released serveral days ago: Another model trained according to Orca's methods (adding detailed explanations to each answer) BUT for multi-turn long chats.
The model was created with a window length of 8K and according to initial impressions it is one of the best models released.
The model: https://t.co/Epgb04d7EW (from @Shahules786)
-----
Chinese models are putting up a fight
Even before the release of Lemma 2, it was clear that the Chinese models are already particularly strong.
And you are advised to try them, their English is excellent and some of them are very useful.
The most powerful programming model for its size: CodeGeex2
The Chinese coding model CodeGeeX2 comes to us with a tiny size of 6B parameters (trained from the flagship Chinese model ChatGLM) and overtakes all models of this size scoring 35.9 on HumanEval (Pass@1).
The model: https://t.co/HnRREpqCNj (from @thukeg)
-----
More details on the Chinese models
Lately I find myself reading more and more posts translated from Chinese via Google Translate.
Infrastructure for LLMs training and dealing with data coming from China is often times particularly high-quality and also incorporate techniques that do not exist in more popular code bases.
(Such as: training with masking, bidirectional training, architecture improvements and delicate tokenizer work to support the Chinese language)
I recommend everyone in the field to also read about the advances of the Chinese models.
-----
Are the open models already at the level of ChatGPT?
Short answer: Not yet, but they are on their way.
Usually when someone say that open source models are on the level of ChatGPT, immediately someone comes up with the hardest test they can think of to show that the open source models are not on the same level as ChatGPT.
According to rumors, ChatGPT was trained on somewhere around 6 times the data of LLaMA 2.
If you want to find holes, you will find them.
Nonetheless, in the real world: I use open models everyday they are just as good as ChatGPT.
-----
What is still left to do?
After the release of the Stable Beluga 2 model I wrote a post summarizing all the metrics from all the datasets where the model's results still don't crush ChatGPT.
You can find it here: https://t.co/aDNFtCHhyl
-----
How do we measure the quality of models?
There are several main "holes" that separate the open models from the closed models, you can read about these holes and the differences between the various models here: https://t.co/5vLhrCf4Eb
-----
From the news: Open source model from OpenAI?
On the background of this, we recently received an interesting news article about the efforts within OpenAI to release an open model.
Link: https://t.co/5NQVxpfBIa
It is not known if the information in this article is correct, but according to the article, open source models are putting pressure on OpenAI they are currently working on an open model as a response to the LLaMA 2.
The model does not compete with the quality of ChatGPT (and certainly not with GPT-4).](https://pbs.twimg.com/media/F2Q61xEXAAAeJIp.jpg)






























