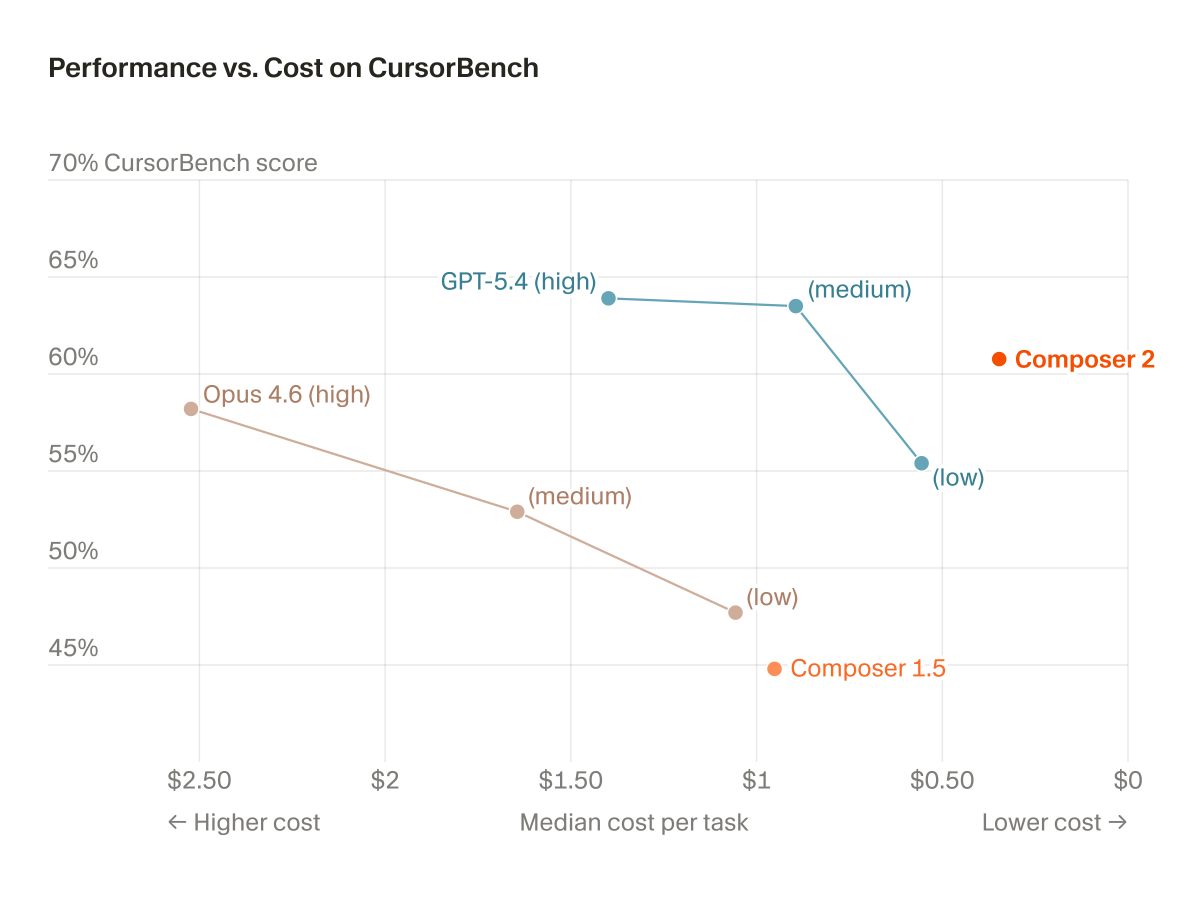
Yep, Composer 2 started from an open-source base! We will do full pretraining in the future.
Only ~1/4 of the compute spent on the final model came from the base, the rest is from our training. This is why evals are very different.
And yes, we are following the license through our inference partner terms.
When you're deciding what to study in college, don't try to predict what will be valuable in the future, because that's so hard that you'll probably get it wrong. Instead focus on what you personally find most exciting. You can't get that wrong.
this is considerably more open than the recent pivot of a LOT of chinese open weights labs to "no bases, just ship the post trained ckpt", as well as data on top of it (!!!)
great stuff
a reminder that Anthropic is a
> fear-mongering company thatʼs
> lobbying against opensource AI
> to stop you from running
> your own AI models
theyʼre
> pro-regulation with an agenda
> pushing “safety” as control
> wants to gatekeep, not protect
> malicious
DO NOT TRUST THEM
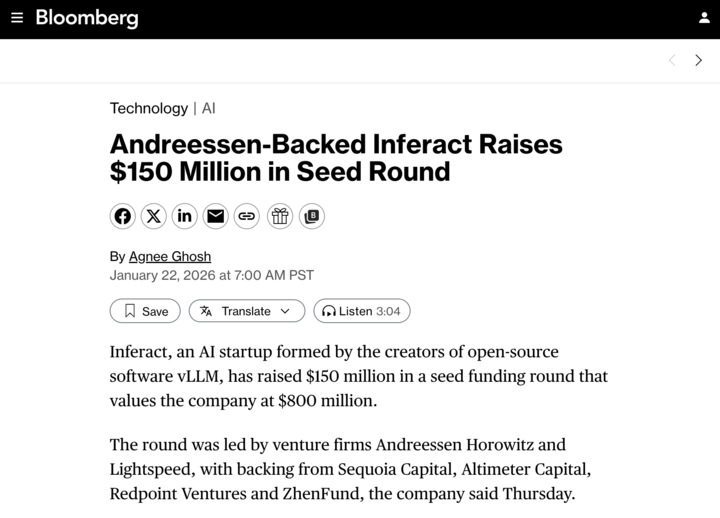
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale. This ecosystem, built with 2,000+ contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
Happy new year! We are excited to announce SkyRL tx 0.2.1, see https://t.co/ekRlMx5yxC. Some highlights of the release include FSDP and multi-node support, Llama 3 model support, custom loss functions, a number of performance improvements and also lots of small fixes that implement more functionality of the Tinker API. The blog post also includes a performance comparison with the Tinker Service! Enjoy the release and happy hacking!
Quick read through of Deepseek's new Manifold-Constrained Hyper-Connections paper:
- You want to increase residual size from 1×C to n×C (n streams instead of 1). Earlier residual update: x' = x + layer(x). Make the x be n×C, and use x' = Ax + B layer(Cx) instead. A, B, C are all dependent on x and are small matrices (n×n, n×1, n×1). A seems the most impactful. This is Hyper-Connections (HC).
- HC has the same issue as other residual modification schemes - eventually the product of the learned A matrices (along the identity path) blows up/vanishes.
- To fix this, they project the A matrices onto the Birkhoff polytope (simpler words: transform it, after exp to make elements positive, to a matrix whose row sums and column sums become 1 - called a doubly stochastic matrix). This has nice properties - products of these types of matrices still have row and column sum 1 (due to closure), so things don't explode (spectral bound), and the invariant is that the sum of weights across streams is 1. For n = 1, this becomes the standard residual stream, which is nice. Their transformation method is simple - alternatively divide rows and columns by row and column sums respectively for 20 iterations (converges to our desired matrix as iterations go to infinity). They find 20 is good enough for both forward and backward pass (across 60 layers, maximum backward gain is 1.6 as opposed to 3000 from usual HC, and 1.6 is not very off from 1).
- Composing these matrices (convex hull of all permutation matrices) leads to information mixing as layer index increases, which is a nice piece of intuition and is also shown very clearly in their composite matrix for 60 layers. I believe overall we get a weighted sum of residual paths (thinking of gradients), where logically group-able paths have weights summing to 1. Quite principled approach IMO, also makes gains (forwards and backwards) very stable.
- Interesting thing to note - lot of "pooling"-like mixing in the first half compared to the second half of the layers. Second half of layers treat different channels more precisely/sharply than the first half, quite intuitive.
- They also change parameterization of B and C (sigmoid instead of tanh, to avoid changing signs probably, and a factor of 2 in front of B, I believe to conserve mean residual multiplier, C doesn't need this because input is pre-normed anyway).
- Cool systems optimizations to make this op fast - they do kernel fusion, recomputation in the mHC backward pass, and even modify DualPipe (their pipeline parallelism implementation).
- Only 6.7% overhead in training when n = 4, loss goes down by 0.02 and improvements across benchmarks.
DeepSeek just dropped a banger paper to wrap up 2025
"mHC: Manifold-Constrained Hyper-Connections"
Hyper-Connections turn the single residual “highway” in transformers into n parallel lanes, and each layer learns how to shuffle and share signal between lanes.
But if each layer can arbitrarily amplify or shrink lanes, the product of those shuffles across depth makes signals/gradients blow up or fade out.
So they force each shuffle to be mass-conserving: a doubly stochastic matrix (nonnegative, every row/column sums to 1). Each layer can only redistribute signal across lanes, not create or destroy it, so the deep skip-path stays stable while features still mix!
with n=4 it adds ~6.7% training time, but cuts final loss by ~0.02, and keeps worst-case backward gain ~1.6 (vs ~3000 without the constraint), with consistent benchmark wins across the board