I will be at MLsys 2026 in Bellevue next week. We are hiring across ML infrastructure including pre-training, post-training, and inference. Come find me and chat!
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
Today we're sharing our work on interaction models. A new class of model trained from scratch to handle real-time interaction natively, instead of gluing it onto a turn-based one.
https://t.co/MoS5s4cm60
Congrats @radixark !
From SGLang @lmsysorg to Miles, and to future products, RadixArk is dedicated to building a crucible capable of repeatedly producing cutting-edge AI, bringing the best of AI into every household. We believe in a future of AI diversity and hope to drive the integration of AI into every aspect of production and daily life. In the future we envision, AI will become a partner to many companies and individuals, finding ways to self-evolve—in production, in daily companionship, and within virtual worlds.
Everything we have experienced and will continue to experience in the SGLang and Miles open-source communities is unforgettable and highly anticipated. It has been both demanding and exhilarating, allowing us to see friendship, the world, and the boundaries.
Over the past six months, I have witnessed for the first time how a united team moves forward hand in hand, and how deeply passionate they are about creation. Each of us has taken on our respective roles and numerous new tasks for the first time; we are all stepping out of our comfort zones, growing, and creating at a rapid pace.
"It’s the step-by-step journey of a thousand miles that has carried us here today, and the same relentless march that will lead us into the tens of thousands of miles yet to come."
In an era where AI has made ordinary productivity cheaper, relentless, day-to-day refinement has increasingly become the rare key that drives innovation and the future. We hope this will forever remain the soul of RadixArk's culture: focused, uncompromising, humble, and fearless. The underlying logic of creation is not the deliberate pursuit of novelty, but rather independent thinking that remains unswayed by temptation, paired with a meticulous drive for perfection.
Real-time videogen has been something I have been pushing hard at FastVideo Team. And Today, we have a big update -- we just made it: Now you can create a 5s 1080p Video in 4.5s with FastVideo on a Single GPU
I believe this is the fastest 1080p text-image-to-audio-video pipeline ever!
Try our free demo to feel the speed and quality: https://t.co/xmJgRioM1K and give us feedback
Blog: https://t.co/OnplmWsJ1n
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale. This ecosystem, built with 2,000+ contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
It still feels a little unreal to look back at how far @vllm_project has come. What started as a small research project that Zhuohan and I launched ended up receiving so much love and connecting me with people who are now some of my closest friends. In so many ways, I already feel incredibly lucky for what this journey has given me.
To be honest, my path with vLLM hasn’t been perfectly straight. Over the past three years, my passion dipped at times, and I did spend my energy exploring things I thought were more interesting than vLLM and inference. vLLM is what it is today because of the community, and I’m truly grateful for their commitment.
My view on inference also evolved a lot along the way. What once felt mostly “solved” turned out to be far from it. The rapid pace of new models, increasingly complex architectures, diverse hardware setups, and agents have made inference genuinely hard. The need for strong inference infrastructure has only kept growing, and it became clear just how much important work remains.
Somewhere along that journey, I realized how special this work really is and how uniquely positioned vLLM is. Now, I’m committed to pushing it all the way. With that, I started @inferact with @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05, and amazing founding team from both inside and outside the vLLM community. I’m deeply grateful to our investors, including @a16z and @lightspeedvp, for believing in us and giving us this opportunity.
Excited for this next chapter, and looking forward to sharing more soon.
Tinker is now generally available. We also added support for advanced vision input models, Kimi K2 Thinking, and a simpler way to sample from models.
https://t.co/nvaJHkGxc0
After two amazing years at Snowflake AI Research, I have joined @thinkymachines! I am excited to work with the incredible team here and build world-class ML systems for the next generation of multimodal AI
Super excited about this work! 🔥
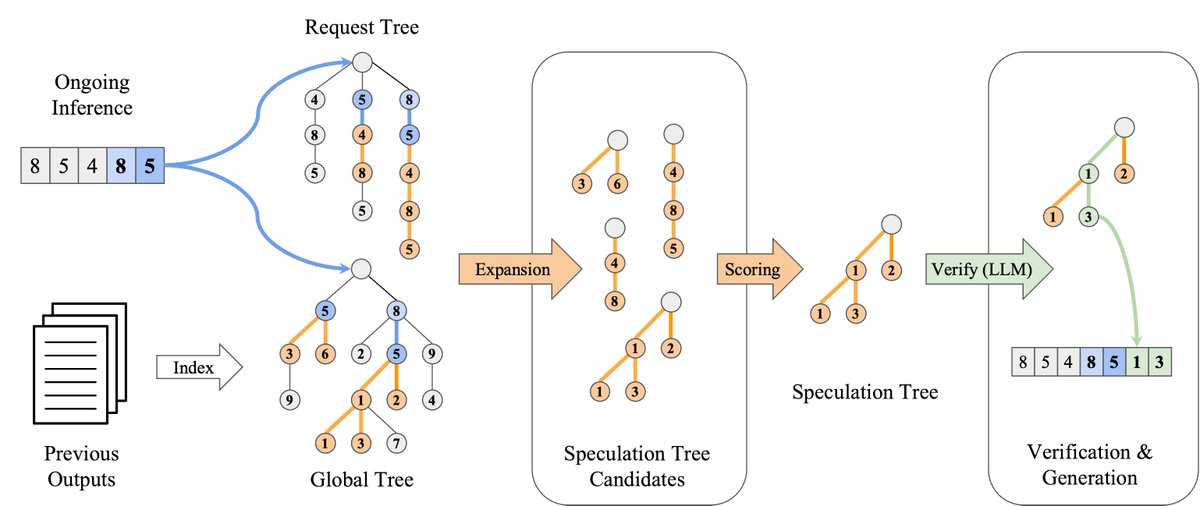
SuffixDecoding accelerates multi-round agent serving by reusing and optimizing over previous agent iterations—5x speedups on AgenticSQL.
Come see @GabrieleOliaro’s #NeurIPS2025 Spotlight!
🐢 Are your #LLM#agents too slow?
🚀 Introducing SuffixDecoding: make agentic workloads run up to 5.3x faster!
🎯 Emerging AI workflows suffer high latency. We fix this with extreme speculative decoding using suffix trees.
🌟 Come see our #NeurIPS2025 Spotlight!
Suffix Decoding is adopted at @Snowflake to accelerate Text2SQL by 1.85x:
https://t.co/t7kZnCD2cQ
Suffix-tree based speculative decoding is adopted by several works to speed up sampling in RL training:
https://t.co/TAYTamV4xx
https://t.co/2SljvcLXFm
https://t.co/DymZra3OFE
Suffix Decoding is at #NeurIPS2025 as a 🏅spotlight! It accelerates LLM inference for coding, agents, and RL.
We also optimized its speculation speed by 7.4x and merged it into vLLM (incoming to SGLang).
Talk to @GabrieleOliaro or me at poster #816 Friday 11am!
Links in🧵
Suffix Decoding:
https://t.co/ike3VBLOA5
Using Suffix Decoding in vLLM:
https://t.co/L0UaVJ9DeX
Community PR in SGLang:
https://t.co/mCz97c93DJ
Speculation optimizations blog:
https://t.co/sWpgrRwxuc